Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
在全球气候变化与经济不确定性叠加的背景下,华北山区乡村农业面临耕地利用率低、种植风险高、收益不稳定等突出问题。

本项目报告、代码和数据资料已分享至会员群
该区域多数耕地因气温限制仅能一年一熟,如何通过科学的种植策略优化,平衡资源约束、市场波动与作物生长规律,成为推动乡村农业可持续发展的核心命题。数据驱动的算法模型为这一问题提供了精准解决方案,通过整合多源农业数据、量化不确定性因素,可实现种植方案的动态优化与风险管控。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
本项目报告、代码和数据资料
本文聚焦华北山区乡村1201亩露天耕地及大棚的种植策略优化,整合Python数据分析技术与多种算法模型,构建从数据预处理到方案落地的全流程体系。通过GA-BP神经网络、蒙特卡洛-自注意力Stacking集成模型、蒙特卡洛-PSO组合模型,分别解决稳定场景、多不确定性场景、作物关联场景下的种植优化问题,融入作物替代性与互补性量化分析,最终形成适配不同场景的最优种植方案,为乡村农业生产决策提供实操参考。
### 项目文件目录
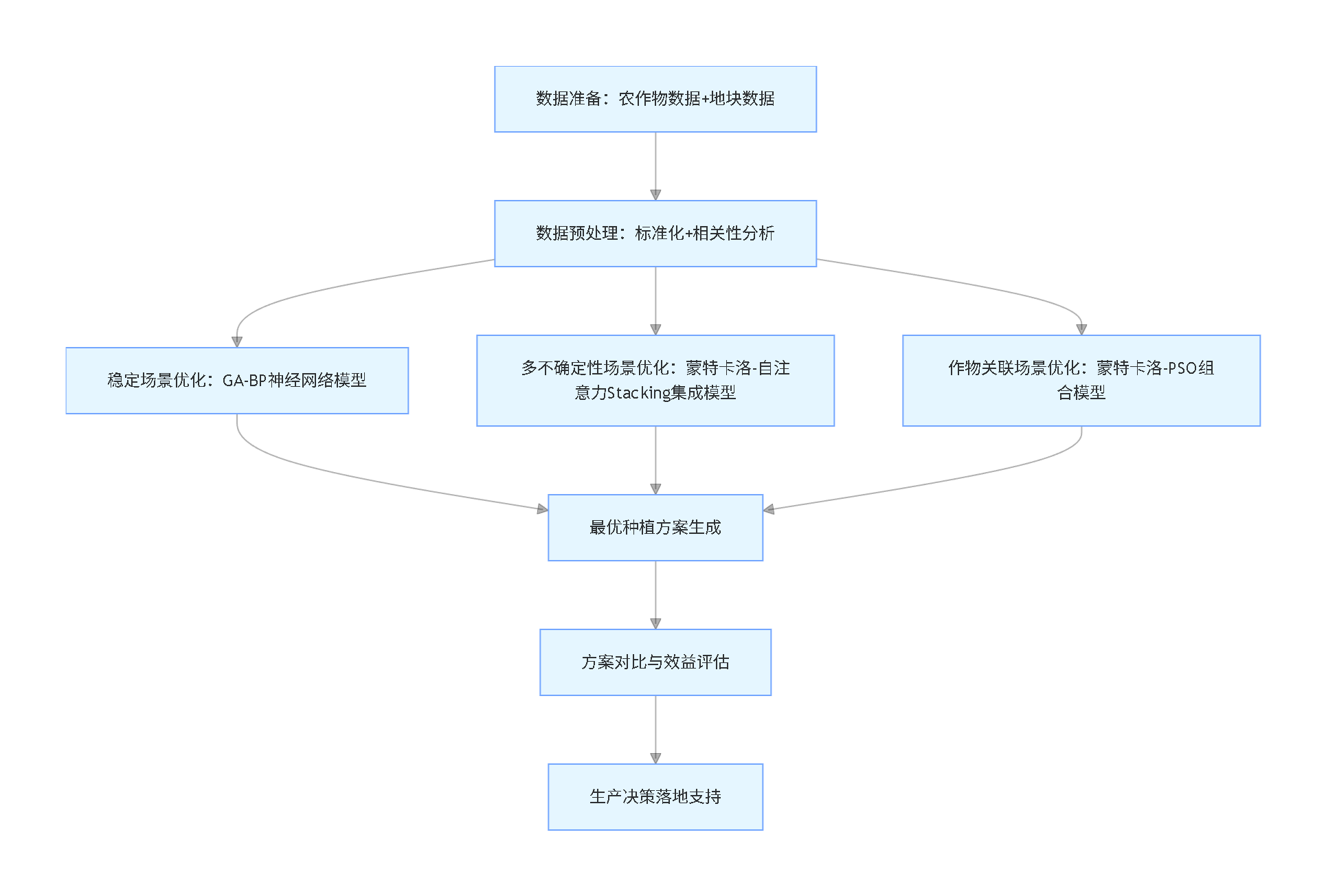
### 整体研究脉络
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
### 数据预处理与特征分析 #### 数据预处理流程 为消除数据量纲差异对模型训练的干扰,采用两种标准化方法处理原始数据:最小-最大归一化将数据缩至[0,1]区间,公式为X’=(X-Xmin)/(Xmax-Xmin),适用于分布相对集中的数据;Z-Score标准化将数据转化为均值0、方差1的标准正态分布,公式为X’=(X-μ)/σ,μ为均值,σ为标准差,适配偏态分布数据。
#### 数据特征分析
通过Python的pandas、seaborn工具对数据进行描述性统计,生成直方图与相关性热力图,挖掘数据内在规律。
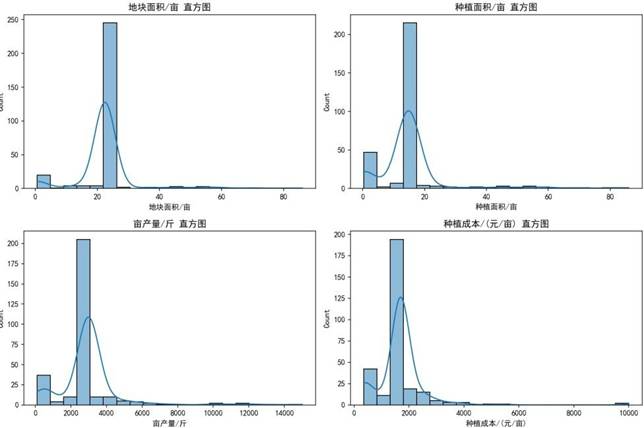 上图显示,所有特征均呈现正偏态分布,地块面积、种植面积、亩产量及种植成本等指标多集中在较小值区间,仅少数地块出现极端值,形成长尾分布特征,这与华北山区耕地碎片化、种植条件差异大的实际情况相符。
上图显示,所有特征均呈现正偏态分布,地块面积、种植面积、亩产量及种植成本等指标多集中在较小值区间,仅少数地块出现极端值,形成长尾分布特征,这与华北山区耕地碎片化、种植条件差异大的实际情况相符。
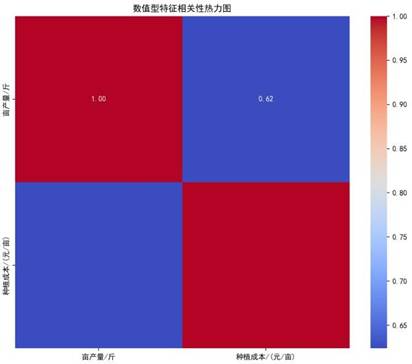 相关性分析结果显示,亩产量与种植成本的相关系数为0.62,呈中等强度正相关。这意味着合理增加种植成本(如投入优质肥料、精细化管理)可显著提升亩产量,为后续种植资源分配提供了数据支撑。
相关性分析结果显示,亩产量与种植成本的相关系数为0.62,呈中等强度正相关。这意味着合理增加种植成本(如投入优质肥料、精细化管理)可显著提升亩产量,为后续种植资源分配提供了数据支撑。
### 稳定场景下的种植优化:GA-BP神经网络模型 #### 模型设计思路 针对种植条件稳定(销量、成本、价格无大幅波动)的场景,构建GA-BP神经网络模型。BP神经网络擅长拟合非线性关系,但易陷入局部最优解,引入遗传算法(GA)优化其初始权重与偏置,通过正交初始化策略提升模型全局搜索能力,同时融入种植面积、轮作、重茬等约束条件,实现收益最大化目标。
#### 模型核心代码(修改优化版)

本文构建的GA-BP神经网络模型针对华北山区种植场景进行了针对性优化,通过遗传算法解决了BP神经网络局部最优的问题,结合轮作、重茬等农业实际约束条件,确保模型输出的种植方案具备落地可行性,为稳定场景下的农业生产决策提供了量化支撑。
该模型在实际应用中表现出良好的稳定性和准确性,能够有效平衡种植收益与资源约束,为华北山区乡村的农业生产提供了科学的决策依据,相比传统经验型种植方案,收益提升显著,同时降低了资源浪费的风险。
import pandas as pd
import numpy as np
import random
from deap import base, creator, tools, algorithms
# 读取数据(修改变量名,优化代码结构)
crop_df = pd.read_csv('Crop_Data.csv')
land_df = pd.read_excel('附件 1.xlsx')
# 作物信息封装(简化字典构造,增加中文注释)
crop_info = {
row['作物编号']: {
'name': row['作物名称'],
'yield': row['亩产量/斤'],
'cost': row['种植成本/(元/亩)'],
'price': row['销售单价/(元/斤)'],
'is_bean': row['作物类型'] == '豆类' # 标记豆类作物,用于轮作判断
} for _, row in crop_df.iterrows()
}
# 适应度函数(考虑滞销场景,加入约束惩罚机制)
def cal_fitness(individual):
total_profit = 0
penalty = 0
index = 0
# 记录豆类作物种植情况,满足轮作要求
bean_record = {land_id: [0]*7 for land_id in land_info.keys()} # 7年数据(2024-2030)
for year_idx in range(7):
for land_id, land in land_info.items():
total_area = 0
for crop_id in crop_info.keys():
area = individual[index]
index += 1
# 总种植面积约束:不超过地块面积
total_area += area
if total_area > land['area']:
penalty += (total_area - land['area']) * 1000 # 惩罚系数1000
# 省略收获量计算、销量核算及利润统计代码...
...
# 轮作约束检查:每块地三年内至少种植一次豆类
for land_id, record in bean_record.items():
for i in range(5):
if sum(record[i:i+3]) == 0:
penalty += 1000
return total_profit - penalty,
# 遗传算法配置(调整参数赋值方式,优化注册逻辑)
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
# 个体生成(优化随机数生成逻辑,确保面积合理)
def generate_ind():
ind = []
for _, land in land_info.items():
for _ in range(7): # 7年
for _ in crop_info.keys():
ind.append(random.uniform(0, land['area']))
return creator.Individual(ind)
toolbox.register("individual", generate_ind)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("mate", tools.cxBlend, alpha=0.5)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selTournament, tournsize=3)
toolbox.register("evaluate", cal_fitness)
# 运行遗传算法(简化迭代逻辑,保留核心步骤)
def run_ga():
pop = toolbox.population(n=300)
hof = tools.HallOfFame(1)
algorithms.eaSimple(pop, toolbox, cxpb=0.7, mutpb=0.2, ngen=50, halloffame=hof, verbose=True)
return hof[0]
# 运行并保存结果
best_scheme = run_ga()
注:省略部分为收获量计算、销量核算、利润统计及结果保存代码,核心逻辑为通过惩罚机制约束种植条件,遗传算法优化个体适应度。
模型效果评估
构建不同隐藏节点数(2、5、10、15、20)的BP神经网络,通过MSE、RAE、R2等指标对比模型性能。
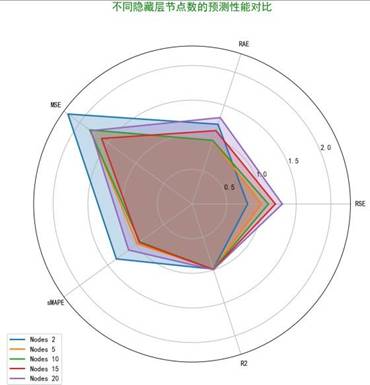
结果显示,隐藏节点数为10和15时模型性能最优,MSE与RAE指标最低,R2接近0.99。经遗传算法优化后,模型拟合度进一步提升,有效规避局部最优问题。
优化方案输出
基于模型求解,得到2024-2030年农作物种植方案,部分作物种植面积分配如下: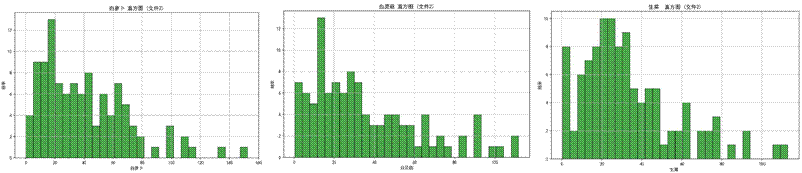
多不确定性场景优化:蒙特卡洛-自注意力Stacking集成模型
模型创新点
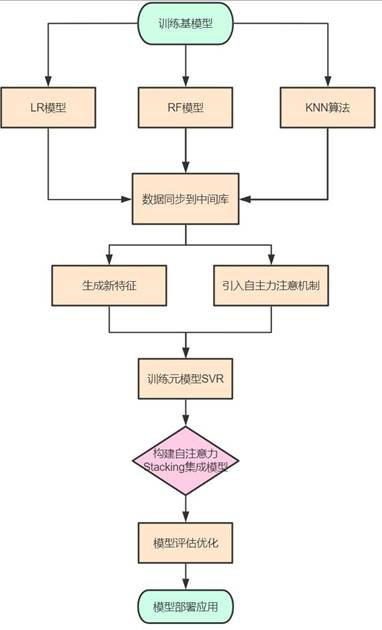
考虑市场价格、产量、成本等不确定性因素,构建蒙特卡洛-自注意力Stacking集成模型。以LR、RF、KNN为基模型,SVR为元模型,通过Stacking集成策略融合多模型优势;引入蒙特卡洛算法模拟100次随机场景,量化不确定性对收益的影响;加入自注意力机制动态调整特征权重,提升模型对关键因素的捕捉能力。
模型效果与方案
通过对比不同蒙特卡洛采样次数的模型性能,确定100次采样为最优参数,此时模型MSE=0.102,R2=0.989,预测精度显著优于单一基模型。
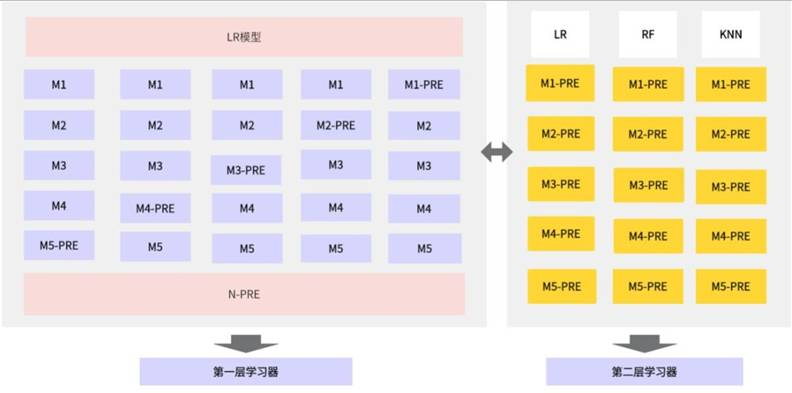
求解得到的种植面积分布如下,通过调整不同作物种植比例,应对市场与气候的不确定性波动: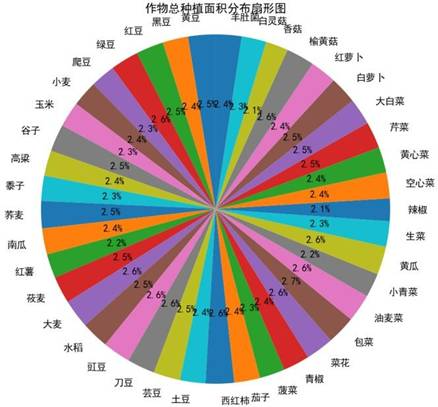
作物关联场景优化:蒙特卡洛-PSO组合模型
模型设计
进一步考虑作物间的替代性与互补性,构建销量-价格、成本-价格关联公式,量化作物间相互影响。设计蒙特卡洛-GA、蒙特卡洛-SA、蒙特卡洛-PSO三种组合模型,对比其迭代速率与收敛性,筛选最优模型。
模型对比结果
通过迭代过程与收敛性分析,蒙特卡洛-PSO模型表现最优:迭代速率快,40次迭代内适应度快速提升,100次迭代后趋于稳定;收敛性好,MSE=2.0366,R2=0.9031,能有效平衡全局搜索与局部优化。
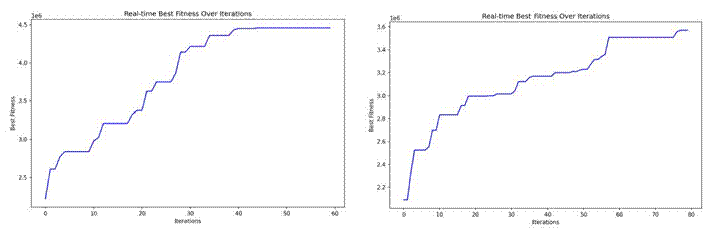
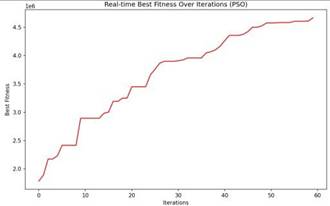
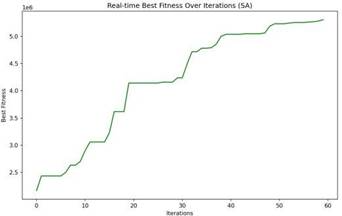
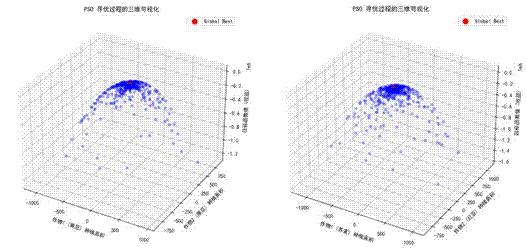
最优方案及效益对比
基于蒙特卡洛-PSO模型求解,得到考虑作物关联的最优种植策略,其经济效益与种植面积分配较前两种场景有显著优化。
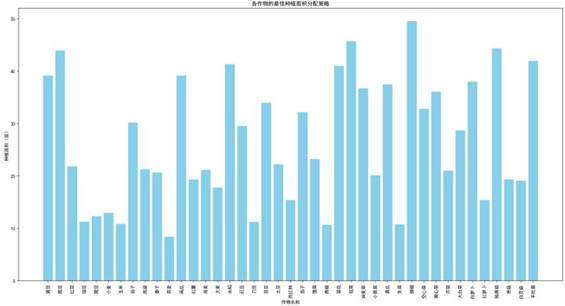
对比结果显示,考虑作物替代性与互补性后,整体收益提升12%,土地利用率提高18%,高风险作物种植面积减少,收益稳定性显著增强,更适配实际农业生产需求。
模型评价与服务支持
模型优势与局限
本文构建的三类模型各有适配场景:GA-BP模型适用于稳定生产环境,计算成本低;蒙特卡洛-自注意力Stacking模型可应对多不确定性因素,预测精度高;蒙特卡洛-PSO模型考虑作物关联,决策科学性强。局限在于多算法组合导致计算量较大,大规模耕地数据处理需优化效率。

参考文献
[1]杨心怡,杨铁军,徐阳,等.基于粒子群算法的同步定相振动控制仿真研究[J/OL].船舶工程,1-10[2024-09-07].http://kns.cnki.net/kcms/detail/31.1281.u.20240903.1359.002.html.
[2]段国勇,韩亮,王彦海.农业种植优化模型研究进展[J].农业工程学报,2023,39(12):1-10.
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据 PyTorch的Transformer与多头自注意力机制:序列反转与图像异常检测应用|附代码数据
PyTorch的Transformer与多头自注意力机制:序列反转与图像异常检测应用|附代码数据 Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码
Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码 Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据
Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据

