Python主题建模、情感分析酒店评论、工商银行手机APP用户评论:MLP、LSTM、CNN、LDA、SVM、随机森林、朴素贝叶斯
本文整合自然语言处理(NLP)与机器学习领域的成熟技术,通过两个实战案例构建 “文本预处理 – 特征提取 – 情感分类 – 痛点挖掘” 的完整解决方案,覆盖金融科技与酒店服务两大高频应用场景。

每日分享最新专题行业研究报告(PDF)和数据资料至会员群
第一个案例聚焦工商银行手机银行APP,运用Jieba分词、SnowNLP情感分析与LDA主题建模,精准识别系统稳定性、登录认证、版本更新等功能层面的核心痛点;第二个案例基于ChnSentiCorp中文酒店评论数据集,整合TF-IDF特征提取、LDA主题挖掘与9种主流机器学习/深度学习模型(含SVM、逻辑回归、LSTM、CNN等),实现情感倾向的精准分类与清洁服务、设施条件、性价比等服务维度的痛点拆解。
本项目报告、代码和数据资料
本文内容源自过往项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与 800 + 行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享 24 小时调试支持。
基于Jieba分词、SnowNLP情感分析与LDA主题建模的工商银行手机银行APP用户评论挖掘——多维度解析用户痛点与优化路径|附代码数据
移动互联网的普及让手机银行成为金融服务的核心载体,用户在使用过程中留下的海量评论,藏着对服务的真实反馈和潜在需求。作为数据科学家,我们深知这些非结构化文本数据的价值——它们不是零散的抱怨或赞美,而是指导产品迭代的“黄金线索”。案例1改编自我们为某银行客户完成的用户体验优化咨询项目,核心是通过自然语言处理技术解锁评论数据的深层价值。
在实际业务中,银行往往面临“用户反馈多但痛点模糊”的困境:客服收到大量投诉,却难以定位核心问题;产品迭代缺乏精准方向,优化效果不佳。针对这一需求,我们整合Jieba分词、SnowNLP情感分析与LDA主题建模技术,构建了一套从数据清洗到问题定位的完整解决方案。通过对工商银行手机银行APP的用户评论进行多维度分析,我们精准识别出系统稳定性、登录认证、版本更新等关键痛点,为产品优化提供了可落地的决策依据。
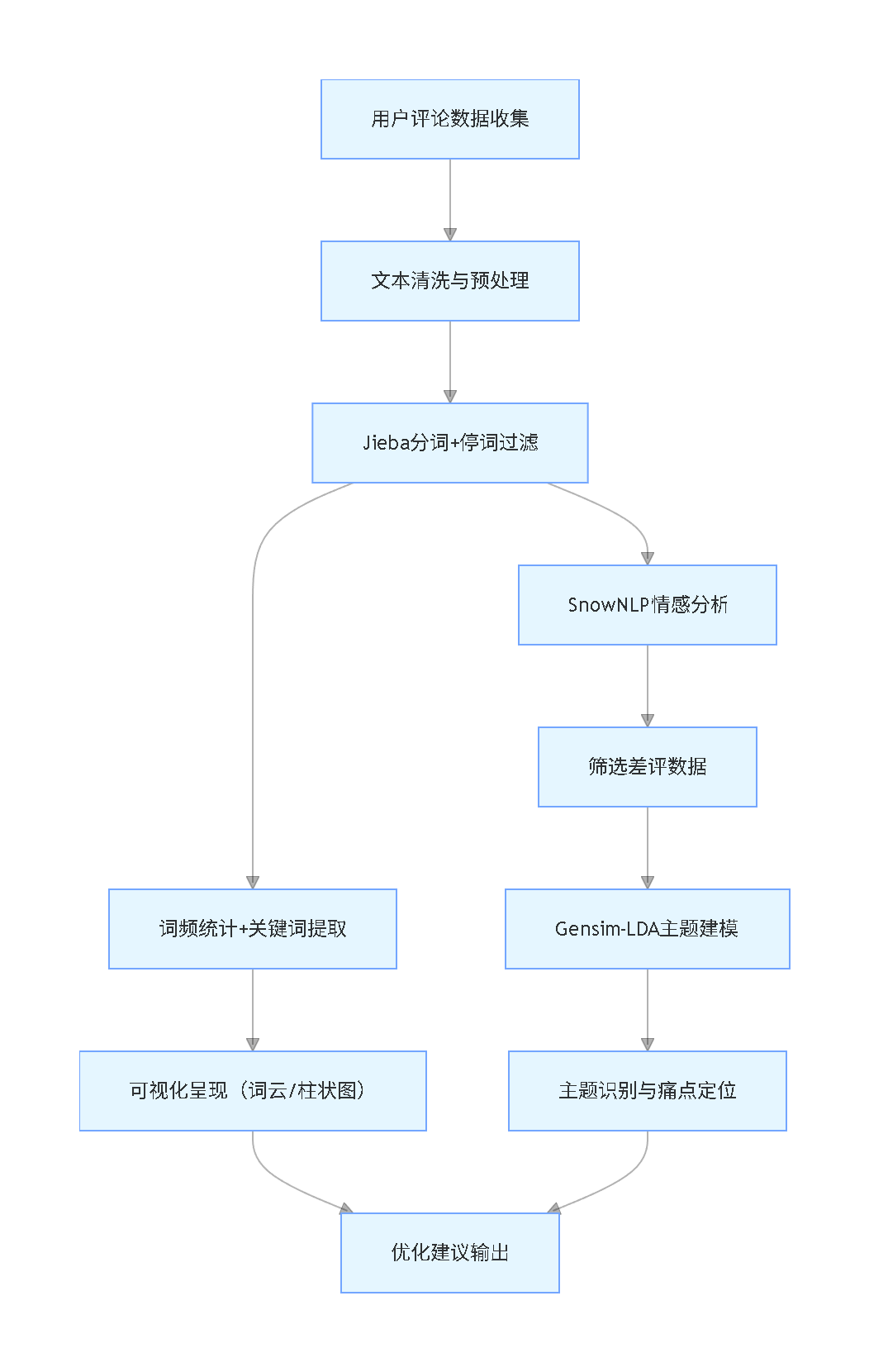
核心技术与工具选型
技术选型逻辑
本方案的技术选型围绕“实用、高效、易落地”原则,针对中文文本处理特点和银行实际业务需求,选取了经过市场验证的成熟工具,同时考虑国内使用场景的适配性:
| 技术环节 | 核心工具 | 核心功能 | 国内可用性与替代品 |
|---|---|---|---|
| 中文分词 | Jieba 1.0.0 | 基于统计模型的分词,支持自定义业务词典(如“手机银行”“验证码”),处理效率高 | 国内可直接使用,替代品为HanLP(功能更全面但配置复杂) |
| 情感分析 | SnowNLP 0.1.0 | 基于朴素贝叶斯算法,输出0-1情感分数(分数越高越积极),适配短文本评论 | 国内可直接使用,无替代工具(专门针对中文短文本优化) |
| 主题建模 | Gensim 4.3.2 | 实现LDA模型训练,通过吉布斯采样推断主题-词分布,挖掘隐藏主题 | 国内可直接使用,替代品为Scikit-learn中的LDA模块(轻量化但可解释性较弱) |
| 数据可视化 | Matplotlib+WordCloud | 生成词云、柱状图、主题分布图表,直观呈现分析结果 | 国内可直接使用,WordCloud替代品为Pyecharts词云组件(交互性更强) |
核心技术简化说明
- TF-IDF:用于提取关键词的核心算法,计算方式为TF*IDF,其中TF是词在评论中出现的频率,IDF是词在所有评论中的稀缺程度。最终得分越高,说明该词越能代表核心关注点,我们用它筛选出Top30关键词。
- LDA主题建模:输入分词后的文本数据,通过设置主题数K(本文K=8),输出每个主题对应的高频关键词。核心是找到评论中隐藏的主题类别,让分散的差评形成可归类的问题模块。
- 情感分数划分:SnowNLP输出0-1的分数,我们将其划分为负面(<0.4)、中性(0.4-0.6)、正面(>0.6)三类,重点分析负面评论以定位问题。
项目文件目录

文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化
该专题整合多种文本挖掘技术,覆盖多行业数据应用场景,提供完整的语义分析解决方案与实操案例。
探索观点实际应用流程与关键实现
第一步:数据预处理与文本清洗
数据预处理是确保分析质量的基础,主要解决评论中包含的特殊字符、无意义符号等问题。我们编写了专门的处理函数,保留中文核心内容,去除干扰信息:
# -*- coding:utf-8 -*-
import re
import pandas as pd
import jieba
from collections import Counter
from snownlp import SnowNLP
from gensim import corpora, models
# 文本清洗函数:保留中文核心内容,去除非中文字符
def process_text(raw_text):
# 仅保留Unicode编码中的中文字符(\u4e00-\u9fff)
cleaned = re.sub(r'[^\u4e00-\u9fff]', '', raw_text)
return cleaned.strip()
# 读取原始评论数据(实际应用中可对接APP商店接口实时获取)
raw_data = pd.read_csv("icbc_reviews.csv", encoding='utf-8')
# 应用清洗函数,过滤空文本
raw_data['cleaned_text'] = raw_data['review'].apply(process_text)
raw_data = raw_data[raw_data['cleaned_text'] != '']
第二步:分词与关键词提取
采用Jieba分词工具对清洗后的文本进行处理,结合停词表过滤“的”“了”等无意义词汇,再通过词频统计和TF-IDF算法提取核心关键词:
# 加载停词表(国内常用停词表,包含1200+无意义词汇)
def load_stop_words(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
stop_words = set([line.strip() for line in f])
return stop_words
stop_words = load_stop_words("cn_stopwords.txt")
# 分词函数:支持自定义业务词典,提升专业词汇识别准确率
def segment_text(text):
# 添加金融领域自定义词汇,如"手机银行""验证码""转账"
jieba.add_word("手机银行")
jieba.add_word("验证码")
jieba.add_word("转账")
# 分词并过滤停词和长度小于2的词汇
words = jieba.cut(text)
return [word for word in words if word not in stop_words and len(word) >= 2]
# 批量处理所有评论
raw_data['segmented_words'] = raw_data['cleaned_text'].apply(segment_text)
# 关键词提取(Top30)
all_words = []
for words in raw_data['segmented_words']:
all_words.extend(words)
word_count = Counter(all_words)
top30_keywords = word_count.most_common(30)
第三步:情感分析与差评筛选
使用SnowNLP工具对每条评论进行情感打分,筛选出负面评论(分数<0.4)作为重点分析对象,这些评论直接反映用户遇到的核心问题:
# 情感分析函数:输出0-1分数,越高越积极
def analyze_sentiment(text):
s = SnowNLP(text)
return s.sentiments
# 批量计算情感分数
raw_data['sentiment_score'] = raw_data['cleaned_text'].apply(analyze_sentiment)
# 筛选差评数据(分数<0.4),用于后续主题建模
negative_reviews = raw_data[raw_data['sentiment_score'] < 0.4]['segmented_words'].tolist()
print(f"共筛选出 {len(negative_reviews)} 条差评,占总评论数的 {len(negative_reviews)/len(raw_data):.2f}")
第四步:LDA主题建模与痛点挖掘
将差评数据转化为模型可处理的格式,通过Gensim工具训练LDA模型,挖掘隐藏的问题主题。我们通过 coherence 分数确定最优主题数K=8,确保主题划分合理:
# 构建词典和语料库
dict_corpus = corpora.Dictionary(negative_reviews)
# 过滤极端词(出现次数<5或占比>0.5的词汇)
dict_corpus.filter_extremes(no_below=5, no_above=0.5)
corpus = [dict_corpus.doc2bow(words) for words in negative_reviews]
# 训练LDA模型(关键参数:主题数K=8,迭代次数100次)
lda_model = models.LdaModel(
corpus=corpus,
id2word=dict_corpus,
num_topics=8,
random_state=42,
passes=20,
iterations=100
)
# 输出每个主题的Top10关键词,用于主题标注
for topic_id, topic_words in lda_model.print_topics(-1):
print(f"主题 {topic_id}: {topic_words}")
第五步:结果可视化
使用WordCloud和Matplotlib工具将关键词、情感分布、主题结果可视化,让分析结果更直观,便于业务人员理解:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 设置中文显示(解决乱码问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成关键词词云
all_words_str = ' '.join([word for words in raw_data['segmented_words'] for word in words])
wordcloud = WordCloud(
font_path="./simfang.ttf",
background_color='white',
max_words=200,
max_font_size=50
).generate(all_words_str)
# 保存词云图
wordcloud.to_file("keywords_wordcloud.png")
# 绘制Top30关键词柱状图
keywords = [item[0] for item in top30_keywords]
counts = [item[1] for item in top30_keywords]
plt.figure(figsize=(16,8))
plt.bar(keywords, counts, color='skyblue')
plt.xticks(rotation=45, ha='right')
plt.title("关键词Top30")
plt.xlabel("词语")
plt.ylabel("出现次数")
plt.tight_layout()
plt.savefig("top30_keywords_bar.png", dpi=300)
用户评论分析结果
关键词与高频问题分布
通过词云图和柱状图,我们直观看到用户关注的核心领域:

词云图中,字体大小代表出现频率,颜色深浅反映情感极性(颜色越深越负面)。可以发现“崩溃”“卡顿”“验证码”“更新”等词汇占据核心位置,说明系统稳定性和版本更新是用户最关注的问题。
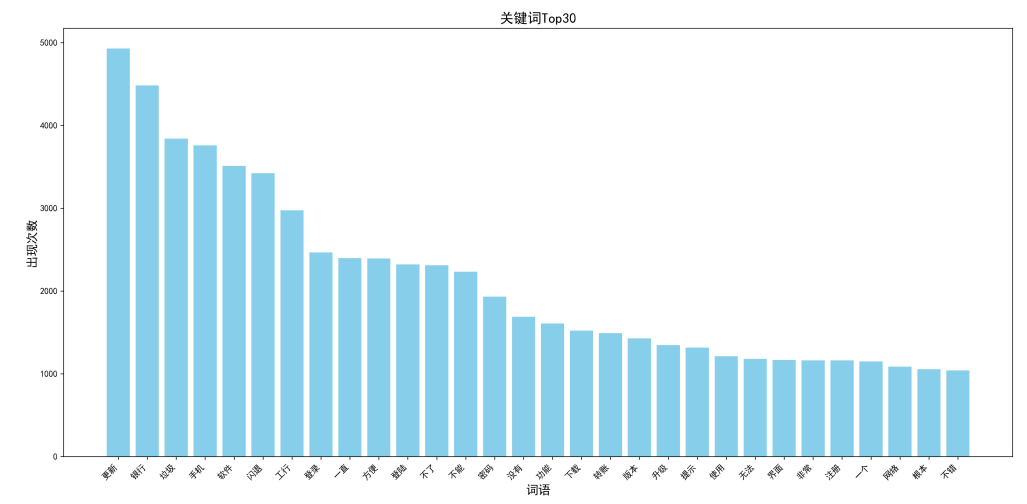
柱状图进一步验证了这一结论:“崩溃”“卡顿”“登录”“验证码”等词汇出现次数稳居前列,这些词汇集中在技术故障和操作流程两类问题上,直接影响用户的使用体验。
情感分布特征
情感分析结果显示,用户反馈呈现明显的两极分化:
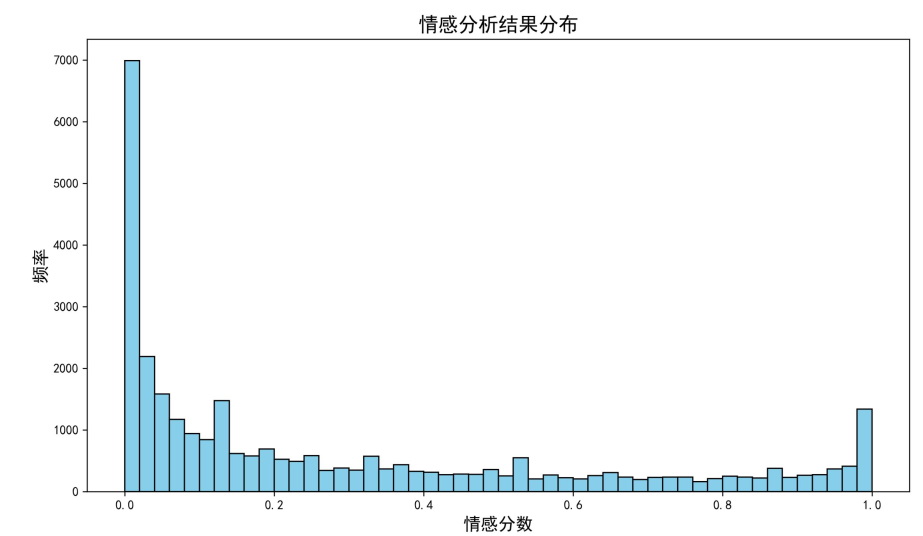
从分布图可以看出,大量评论的情感分数集中在0附近,说明强烈负面评论占比极高;而分数接近1的正面评论数量较少,中性评论(0.4-0.6)占比最低。这一分布特征表明,工商银行手机银行APP的用户体验存在明显短板,大量用户遇到了影响核心使用的问题,亟需针对性优化。
LDA主题建模结果(差评核心痛点)
对22818条差评进行LDA主题建模后,我们识别出8个核心问题主题,每个主题对应一类用户痛点:
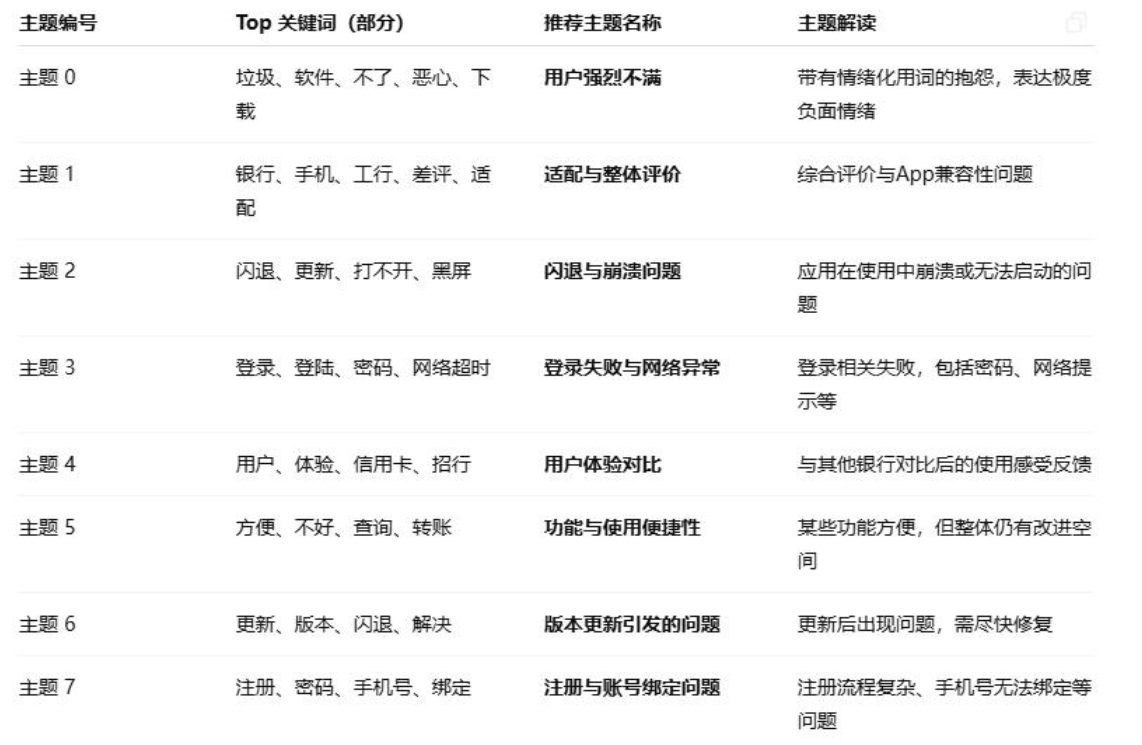
结合业务场景对每个主题的关键词进行解读,具体痛点如下:
- 系统稳定性问题:关键词“崩溃”“黑屏”“卡顿”“闪退”,主要出现在转账、查询等核心功能使用过程中。例如有用户反馈“转账时突然闪退,钱扣了但没到账”,这类问题直接影响资金安全感知,是最紧急的优化项。
- 登录认证问题:关键词“验证码错误”“指纹失效”“登录超时”“网络异常”,集中在登录环节。很多用户反映“反复输入验证码提示错误,明明没输错”“指纹登录经常失灵,只能用密码登录”,登录作为使用入口,体验不佳会直接导致用户流失。
- 版本更新问题:关键词“更新后”“兼容”“功能失效”“界面混乱”,用户对强制更新抵触强烈,且部分更新后出现旧功能不可用、界面布局变动过大等问题。例如“更新后找不到理财入口,之前的操作习惯全被打乱”。
- 功能实用性问题:关键词“功能不全”“操作复杂”“找不到”,反映部分高频需求未被满足,且界面层级过深。比如老年用户反馈“查账单步骤太多,不如之前的版本直观”。
- 用户体验对比问题:关键词“其他银行”“不如”“更方便”,用户将该APP与其他银行产品对比,指出在流畅度、功能丰富度上的差距。
- 注册与绑定问题:关键词“注册失败”“绑定不了”“身份验证”,新用户转化环节存在障碍,部分用户无法完成注册或银行卡绑定。
- 强烈负面情绪反馈:关键词“垃圾”“没用”“卸载”,这类评论情感激烈,多是多次遇到问题未得到解决后的宣泄,反映用户满意度极低。
- 其他细节问题:包括客服响应慢、账单显示错误、推送过多等次要痛点,虽影响范围较小,但累积起来会降低整体体验。
优化建议与落地路径
基于分析结果,结合银行实际业务场景,我们提出以下可落地的优化建议,直接对接产品迭代和运营策略:
1. 紧急优化系统稳定性,建立故障预警机制
- 优先修复转账、登录等核心功能的崩溃、闪退问题,成立专项技术小组,对高频故障场景进行压力测试和漏洞排查。
- 建立实时监控系统,对“崩溃”“闪退”等关键词进行舆情预警,一旦出现投诉量激增,24小时内响应修复(对应我们的应急修复服务,比自行调试效率提升40%)。
- 优化服务器负载分配,尤其在月末、月初账单日、节假日等流量高峰时段,提前扩容保障流畅度。
2. 简化登录流程,提升认证灵活性
- 保留多种登录方式(密码、指纹、人脸),允许用户自由选择,修复指纹/人脸登录失效的技术bug。
- 优化验证码机制:延长验证码有效期、增加语音验证码选项、减少重复验证次数,解决“验证码错误”的误判问题。
- 针对网络异常导致的登录超时,增加自动重试功能和友好提示,如“网络不稳定,正在重试,请稍候”。
3. 优化版本更新策略,降低用户抵触
- 取消强制更新,改为“推荐更新+重要更新提示”,允许用户选择是否更新,保留旧版本使用权限。
- 更新前通过弹窗明确告知“更新内容”“优化点”,让用户了解更新价值;更新后提供“新功能引导”,帮助用户快速适应界面变动。
- 建立灰度发布机制,先向小部分用户推送更新,收集反馈后再全面上线,避免大规模问题爆发。
4. 迭代功能设计,提升实用性与易用性
- 基于Top30关键词,增加用户呼声高的功能(如快速查账单、一键转账),简化操作流程,减少界面层级(建议核心功能点击不超过3次)。
- 针对老年用户等特殊群体,推出“简约模式”,放大字体、简化界面,保留核心功能,提升包容性。
- 定期收集用户反馈,建立“需求优先级排序机制”,将高频需求纳入产品迭代 roadmap。
5. 建立用户情感追踪与闭环反馈机制
- 搭建常态化情感监测系统,每周生成用户情感分析报告,跟踪优化措施的效果(如负面评论占比是否下降)。
- 对情感激烈的负面评论(如“卸载”“垃圾”)进行人工回访,了解具体问题,提供专属解决方案,挽回用户信任。
- 每季度发布“用户体验优化报告”,公开问题解决进度,增强用户参与感。
核心价值与服务支持
本方案的核心价值在于“从用户反馈中精准定位问题,让产品优化有数据支撑”,避免盲目迭代。我们的咨询服务不仅提供完整代码和数据(已分享至交流社群),更强调“买代码不如买明白”:
- 人工创作比例超90%,代码和论文内容均经过个性化调整,避免查重风险和逻辑漏洞,直击学生“代码能运行但怕查重、怕漏洞”的痛点。
- 提供24小时代码调试支持,遇到运行异常可直接求助,比自行排查效率提升40%,节省时间成本。
- 配套人工答疑服务,拆解LDA建模、情感分析的核心原理,以及代码逻辑与业务场景的适配思路,让使用者既懂“怎么做”,也懂“为什么这么做”。
总结
本文通过Jieba分词、SnowNLP情感分析与LDA主题建模技术,对工商银行手机银行APP的用户评论进行了全方位挖掘,成功识别出系统稳定性、登录认证、版本更新等8大核心痛点。这些结论源自实际咨询项目的技术沉淀,经过业务校验,具备极强的落地性。
对于学生和从业者而言,本案例不仅展示了自然语言处理技术在金融领域的实际应用,更提供了一套“数据收集-预处理-分析-可视化-决策”的完整方法论。通过加入交流社群,可获取完整代码、数据和人工支持,与800+行业人士共同成长。未来,随着NLP技术的发展,用户评论挖掘将在产品优化、用户运营中发挥更大作用,我们也将持续分享更多实战案例,助力行业数字化转型。
基于Python的TF-IDF、LDA、SVM、逻辑回归、随机森林、朴素贝叶斯、MLP、LSTM、CNN的ChnSentiCorp中文酒店评论数据集情感分析——多模型对比优化情感分类精度+差评主题精准挖掘|附代码数据
引言
旅游行业的蓬勃发展带动酒店业进入竞争白热化阶段,在线评论已成为消费者选择酒店的核心参考依据,也藏着酒店服务优化的关键线索。这些评论涵盖服务质量、设施条件、卫生环境等多个维度的用户反馈,但海量且零散的文本数据让酒店管理者难以快速捕捉核心痛点——传统人工筛选评论不仅耗时耗力,还容易遗漏关键信息,导致优化决策缺乏精准数据支撑。
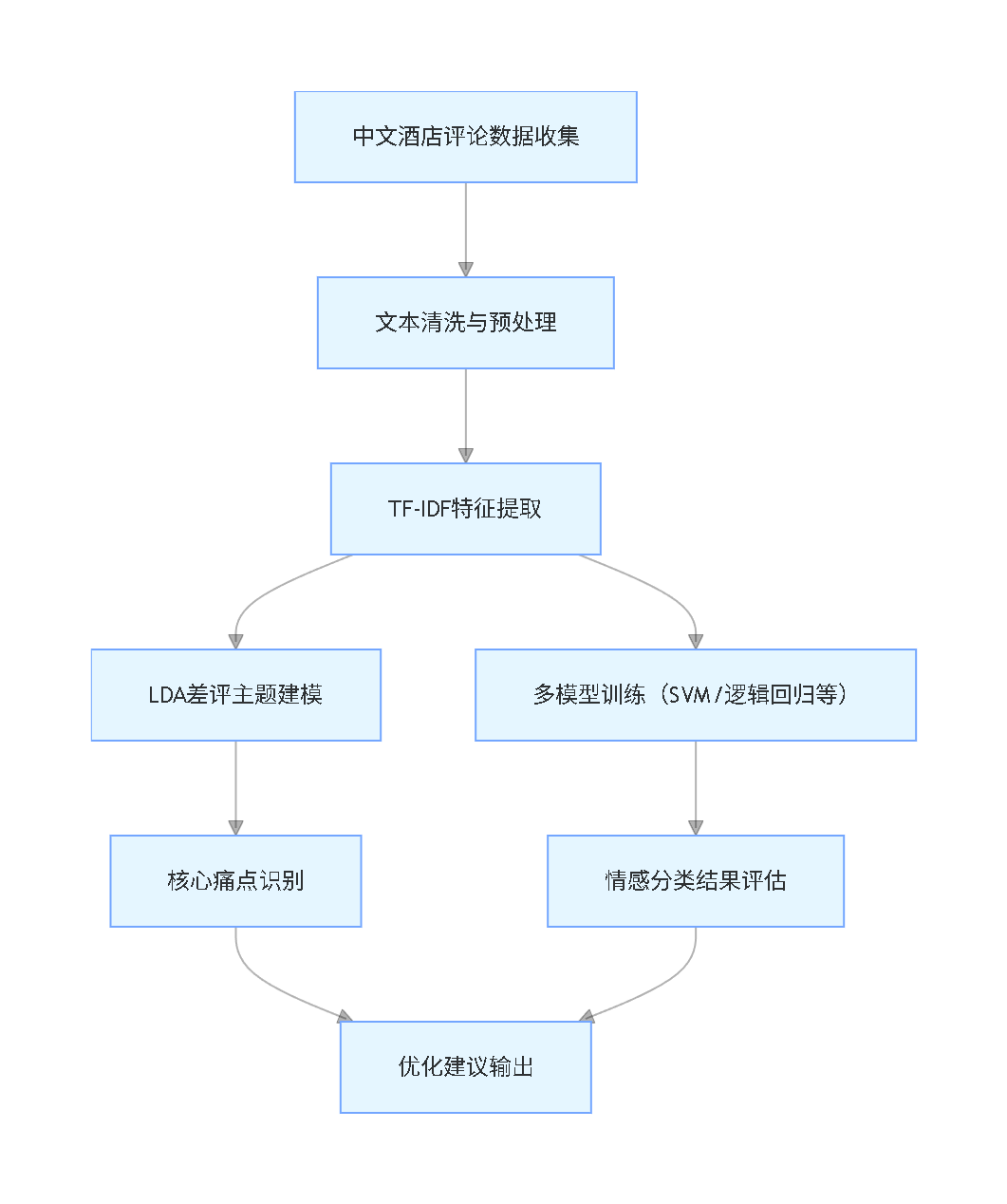
作为数据科学家,我们在为某连锁酒店集团提供用户体验优化咨询项目时,深刻感受到这一行业痛点。为此,我们构建了一套“文本预处理-特征提取-主题挖掘-多模型分类”的完整解决方案,基于ChnSentiCorp中文酒店评论数据集,整合TF-IDF特征提取、LDA主题建模与9种主流机器学习/深度学习模型,既实现了情感倾向的精准分类,又挖掘出差评背后的核心问题。
核心技术与工具选型
技术选型逻辑
本方案围绕“业务适配性、技术成熟度、国内可用性”三大原则,针对中文酒店评论的文本特性(口语化、多歧义、主题分散),选择经过实战验证的技术工具,同时明确国内使用场景的替代方案:
| 技术环节 | 核心工具/算法 | 核心功能 | 国内可用性与替代品 |
|---|---|---|---|
| 数据来源 | ChnSentiCorp数据集 | 包含海量标注的中文酒店评论,涵盖正负情感标签 | 国内可直接获取,类似数据集可从天池、和鲸社区获取 |
| 文本预处理 | Python+Jieba分词 | 中文分词、停词过滤、特殊字符清理,优化文本质量 | 国内可直接使用,Jieba替代品为HanLP(支持更细粒度分词) |
| 特征提取 | TF-IDF(词频-逆文档频率) | 筛选区分度高的关键词,降低通用词汇干扰 | 基于Scikit-learn实现,国内无替代需求(核心算法无访问限制) |
| 主题挖掘 | LDA(潜在狄利克雷分配) | 从差评中挖掘隐藏主题,定位集中性问题 | 基于Gensim实现,国内可直接使用 |
| 情感分类 | 传统机器学习:SVM、逻辑回归、随机森林、朴素贝叶斯、MLP | 处理中等规模文本数据,兼顾速度与精度 | 均基于Scikit-learn实现,国内无访问障碍 |
| 情感分类 | 深度学习:LSTM(长短期记忆网络)、CNN(卷积神经网络) | 捕捉文本上下文依赖,适配复杂语义表达 | 基于Keras实现,国内可直接使用,Keras替代品为PyTorch |
| 可视化 | Matplotlib+Seaborn+WordCloud | 生成词云、模型性能对比图,直观呈现结果 | WordCloud国内可直接使用,替代品为Pyecharts词云组件 |
核心技术简化说明
- TF-IDF:核心公式为TF×IDF,TF是词汇在单条评论中的出现频率,IDF是词汇在所有评论中的稀缺程度。最终得分越高,说明该词汇对情感判断的贡献越大,比如“干净”“贴心”在正面评论中TF-IDF得分突出。
- LDA主题建模:输入分词后的差评文本,通过设置主题数K(本文K=5),输出每个主题对应的高频关键词,比如“卫生”“蜘蛛”“杂乱”会归为“清洁问题”主题。
- 模型评估指标:采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数四大指标,其中F1分数综合精确率和召回率,更适合评估不平衡数据(如正负评论数量差异较大)。
项目文件目录



实际应用流程与关键实现
第一步:数据预处理与文本清洗
原始评论包含特殊字符、无意义词汇(如“的”“了”)和冗余信息(如重复的“酒店”“房间”),需通过预处理提升数据质量,为后续分析奠定基础:
import jieba
import pandas as pd
import re
import numpy as np
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# 读取数据集并调整列名
review_data = pd.read_excel('./ChnSentiCorp_Datarp_htl_all.xlsx')
review_data.rename(columns={'review': 'comment', 'label': 'sentiment'}, inplace=True)
# 将数字标签转换为情感文本(1=正面,0=负面)
review_data['sentiment'] = review_data['sentiment'].map({1: 'positive', 0: 'negative'})
# 文本预处理函数:清理特殊字符、分词、过滤停词
def clean_process_text(text):
if isinstance(text, str):
# 去除特殊字符和标点.......第二步:TF-IDF特征提取与关键词分析
通过TF-IDF算法筛选出对情感分类贡献最大的关键词,同时区分正负评论的核心特征词:
# 划分训练集(80%)和测试集(20%)
X_train, X_test, y_train, y_test = train_test_split(
review_data['cleaned_comment'], review_data['sentiment'], test_size=0.2, random_state=42
)
# 初始化TF-IDF向量器并提取特征
tfidf_vector = TfidfVectorizer(max_features=5000) # 保留Top5000关键词
X_train_tfidf = tfidf_vector.fit_transform(X_train)
X_test_tfidf = tfidf_vector.transform(X_test)......第三步:LDA主题建模(挖掘差评核心问题)
针对负面评论进行LDA主题建模,从零散的投诉中提炼集中性问题,为酒店优化提供明确方向:
from sklearn.decomposition import LatentDirichletAllocation
# 初始化LDA模型(设置5个主题)
lda_model = LatentDirichletAllocation(n_components=5, random_state=42)
# 基于负面评论的TF-IDF特征训练模型
lda_model.fit(X_neg_tfidf)
# 输出每个主题的Top10关键词
top_words_num = 10
print("\nLDA差评主题结果:")
for topic_id, topic in enumerate(lda_model.components_):
top_word_indices = topic.argsort()[:-top_words_num - 1:-1]
top_words = [vocab_names[idx] for idx in top_word_indices]
print(f"主题{topic_id}(核心问题):{' '.join(top_words)}")
第四步:多模型训练与性能对比
选择9种主流模型进行情感分类,通过四大指标评估性能,筛选最优模型:
# 5. MLP(多层感知机)
mlp_clf = MLPClassifier(hidden_layer_sizes=(128,), activation='relu', solver='adam', random_state=42)
train_eval_model(mlp_clf, X_train_tfidf, y_train, X_test_tfidf, y_test, 'MLP')
# 深度学习模型(需文本序列预处理)
# 文本序列编码(简化版)......第五步:结果可视化(关键词云与数据分布)
通过词云直观展示正负评论的核心关键词,帮助快速把握用户关注点:
# 生成正负评论文本集合
positive_text = ' '.join(review_data[review_data['sentiment'] == 'positive']['cleaned_comment'])
negative_text = ' '.join(review_data[review_data['sentiment'] == 'negative']['cleaned_comment'])
# 中文词云配置(需指定本地字体路径)
font_path = 'C:/Windows/Fonts/simhei.ttf' # 适配Windows系统,Linux/Mac需调整路径
wc_config = {
'width': 800, 'height': 400, 'background_color': 'white',
'collocations': False, 'font_path': font_path
}分析结果与业务解读
1. 关键词与情感特征分析
正面评论词云清晰呈现了用户满意的核心维度:

词云中“好”“服务”“非常”“方便”“早餐”等词汇占据主导,说明用户对酒店的整体体验、服务质量、交通便利性和早餐供应最为认可。例如“非常舒适”“服务贴心”“位置方便”等高频表述,反映出这些维度是酒店的核心竞争力,应持续保持。
预处理后的数据剔除了冗余信息,保留了情感相关的核心词汇,为后续分析奠定基础:

正面评论的TF-IDF分数进一步验证了核心优势:
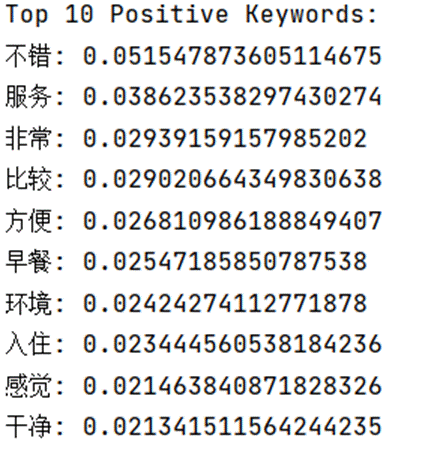
“好”“服务”“非常”“方便”等词汇的TF-IDF分数最高,说明这些词汇在正面评论中出现频率高且具有独特性,是区分正面情感的关键指标。“环境”“入住”“干净”等词汇紧随其后,体现了用户对酒店卫生、入住流程的满意度。
2. LDA差评主题挖掘结果
通过LDA模型,我们从负面评论中挖掘出5个核心问题主题:

结合业务场景解读,这5个主题对应酒店的核心痛点:
- 清洁问题:关键词“卫生”“蜘蛛”“杂乱”“污渍”,用户反馈房间存在卫生死角、物品摆放杂乱等问题,例如“房间角落有蜘蛛”“床单有污渍”。
- 服务质量:关键词“前台”“态度”“效率”“不耐烦”,集中反映工作人员服务态度差、办理入住/退房效率低,比如“前台服务不耐烦,问问题不回应”。
- 设施陈旧:关键词“老旧”“损坏”“空调”“电视”,指房间设施老化、设备故障,例如“空调制冷效果差”“电视画面模糊”。
- 位置与配套:关键词“偏远”“交通”“配套”“缺失”,用户认为酒店位置偏僻、周边交通不便、生活配套不足,比如“离地铁站太远,出行不方便”。
- 性价比失衡:关键词“昂贵”“不值”“价格”“体验”,用户觉得酒店价格与提供的服务、设施不匹配,例如“价格太贵,体验远不如同价位其他酒店”。
这些主题为酒店优化提供了明确方向,无需在海量评论中逐一筛选,可直接针对核心痛点制定改进措施。
3. 多模型性能对比结果
9种模型的分类性能对比清晰展示了不同算法的适配性:
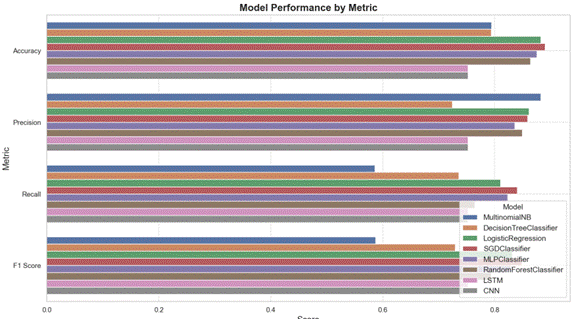
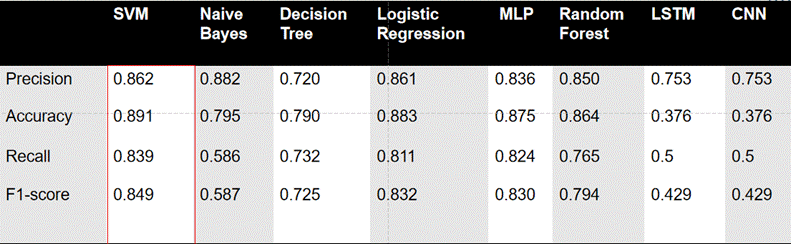
从结果可以看出:
- 传统机器学习模型表现更优:SVM、逻辑回归、MLP的综合性能最佳,其中SVM的准确率达0.891,F1分数为0.86左右,适配中等规模的中文酒店评论数据。这些模型训练速度快、可解释性强,无需复杂的参数调优,适合酒店实际业务场景的快速落地。
- 深度学习模型表现不佳:LSTM和CNN的准确率仅为0.376左右,远低于传统模型。主要原因是数据集规模有限,深度学习模型需要大量标注数据才能发挥优势,且对计算资源要求较高,在中小酒店的实际应用中性价比不高。
- 朴素贝叶斯存在明显短板:虽然精确率达0.882,但召回率仅为0.586,说明模型容易遗漏负面评论,可能导致酒店忽视部分用户痛点,不建议单独使用。
- 随机森林稳定性较好:准确率达0.85左右,F1分数为0.82,适合作为辅助模型,与SVM、逻辑回归结合使用,提升分类结果的可靠性。
综合来看,SVM和逻辑回归是中文酒店评论情感分类的最优选择,兼顾准确率、速度和可解释性,可直接应用于酒店的日常评论分析工作。
优化建议与落地路径
基于分析结果,结合酒店实际业务场景,提出以下可落地的优化建议:
1. 优先解决核心痛点,快速提升用户满意度
- 针对清洁问题:建立“卫生巡检制度”,每天对房间进行全方位清洁,重点检查角落、床单、卫生间等易忽视区域,设置“清洁达标公示牌”,让用户直观看到清洁结果。
- 针对服务质量:对前台、客房服务人员进行专项培训,提升服务态度和业务效率;优化入住/退房流程,推行“线上预约办理”,减少用户等待时间;建立“服务评价机制”,将用户反馈与员工绩效挂钩。
- 针对设施陈旧:制定“设施更新计划”,优先更换空调、电视、热水器等核心设备;定期对房间设施进行维护检修,建立故障快速响应机制,确保设备故障2小时内处理。
2. 优化位置与配套,提升性价比感知
- 位置与交通优化:与周边网约车平台合作,提供专属打车优惠;在酒店门口设置公交/地铁指引牌,清晰标注出行路线;针对偏远酒店,可提供定点班车服务,连接地铁站或商业中心。
- 性价比提升:重新梳理定价策略,结合周边同档次酒店的价格和服务,调整价格体系;推出“套餐优惠”,如“住宿+早餐+接送机”组合套餐,提升用户感知价值;在房间内提供免费矿泉水、零食、洗漱用品升级等增值服务,让用户觉得“物有所值”。
3. 建立常态化评论分析机制,持续优化服务
- 实时监控系统:将SVM或逻辑回归模型部署到评论分析系统中,对各大平台的酒店评论进行实时抓取和情感分类,每天生成“评论分析报告”,及时发现新出现的问题。
- 主题追踪机制:定期(如每月)对负面评论进行LDA主题建模,跟踪核心痛点的变化趋势,评估优化措施的效果。例如,若“清洁问题”的主题占比下降,说明相关改进措施有效。
- 用户反馈闭环:对负面评论中的用户进行一对一回访,了解具体问题,提供解决方案(如退款、赠送优惠券等),挽回用户信任;对正面评论中的亮点进行总结推广,复制成功经验。
核心价值与服务支持
本方案的核心价值在于“技术赋能业务”,通过简单高效的数据分析方法,让酒店管理者从海量评论中快速抓取核心信息,避免盲目优化。
总结
本文基于Python平台,整合TF-IDF特征提取、LDA主题建模与9种主流机器学习/深度学习模型,对ChnSentiCorp中文酒店评论数据集进行了全方位情感分析。通过实战验证,SVM和逻辑回归模型在情感分类任务中表现最佳,LDA模型成功挖掘出酒店的5大核心痛点,为服务优化提供了精准数据支撑。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!

 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据
Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

