Matlab古代玻璃制品化学成分数据鉴别:K近邻回归、聚类、决策树、随机森林、卡方检验、相关性分析
古代玻璃是解读丝绸之路中外文化交流的关键实物证据,不同时期的玻璃在成分体系、制作工艺上存在显著差异。

本项目报告、代码和数据资料已分享至会员群
但古代玻璃易受环境影响发生风化,导致内部化学成分比例改变,这给玻璃类型的准确鉴别带来了极大挑战——外观相似的玻璃可能属于不同类别,而风化后的成分变化更会干扰判断。本文内容正是源自该项目的技术沉淀与实际业务校验的获奖作品,所有结论均通过数据验证。
该项目完整代码与数据已分享至交流社群。阅读原文进群,可与600+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。本文将以“数据解决实际问题”为核心,先梳理古代玻璃分析的核心需求,再通过卡方检验、相关性分析、K-means聚类等方法,逐步解决“风化关联分析”“类型划分”“未知玻璃鉴别”“成分差异对比”四大问题,最终形成一套可复用的文物成分数据分析框架。
二、问题重述与分析思路
1. 核心数据
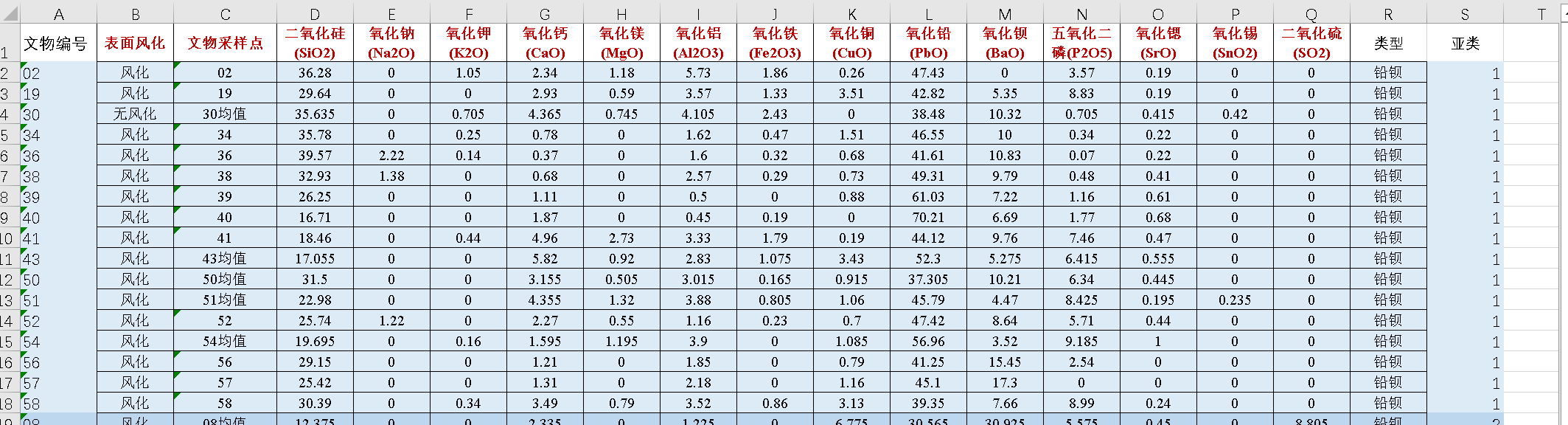

本次分析基于三组古代玻璃数据:
- 表单1:包含玻璃的类型(高钾玻璃、铅钡玻璃)、纹饰、颜色、表面风化状态;
- 表单2:对应玻璃的14项主要化学成分(如二氧化硅SiO₂、氧化钾K₂O等)占比;
- 表单3:未知类型玻璃的化学成分与风化状态,需鉴别其类型。
2. 核心问题
- 分析玻璃风化与类型、纹饰、颜色的关系,探寻风化与成分的统计规律,并预测风化前的成分;
- 明确高钾/铅钡玻璃的分类规律,对两类玻璃进行亚分类,并验证方法合理性;
- 鉴别表单3中未知玻璃的类型,分析分类结果的敏感性;
- 对比两类玻璃的成分关联关系,找出关键差异成分。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
三、模型假设与变量说明
1. 模型假设
为确保分析聚焦核心问题,我们基于实际业务场景设定以下合理假设:
- 玻璃的颜色、纹饰不影响风化前后化学成分的改变量;
- 聚类分析中暂不考虑风化时间长短对成分的影响;
- 附件数据真实可靠,无测量误差;
- 未检测到的化学成分含量视为0。
2. 关键变量说明
| 符号 | 符号说明 | 应用场景 |
|---|---|---|
| K | 聚类分析的分类数 | K-means亚分类时,通过肘部法确定最佳K值 |
| P | 皮尔逊卡方值 | 卡方检验中,用于判断变量间关联性(P<0.05为显著相关) |
四、各问题建模与求解
1. 问题1:风化关联分析与成分预测
(1)风化与类型、纹饰、颜色的关联——卡方检验
我们先通过卡方检验判断“风化”与“类型/纹饰/颜色”这三个定类变量的关联性,再用数据可视化验证细节。
分析步骤:
- 数据预处理:删除表单1中颜色缺失的行,确保分析样本完整;
- 卡方检验:用SPSS对“风化-类型”“风化-纹饰”“风化-颜色”分别做检验,核心看P值;
- 优化分析:考虑变量组合(如“类型+纹饰”),进一步挖掘潜在关联。
检验结果与对应图表:
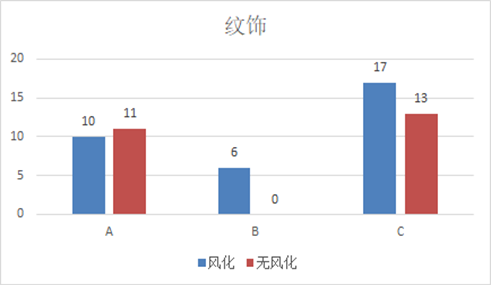
- 纹饰与有无风化的卡方检验:皮尔逊卡方值为0.084(>0.05),说明纹饰对风化的影响不显著。
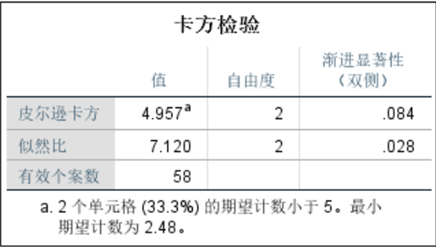
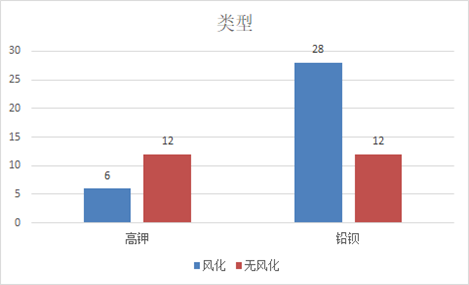
- 类型与有无风化的卡方检验:皮尔逊卡方值为0.009(<0.05),说明类型对风化的影响显著,高钾玻璃不易风化、铅钡玻璃易风化。
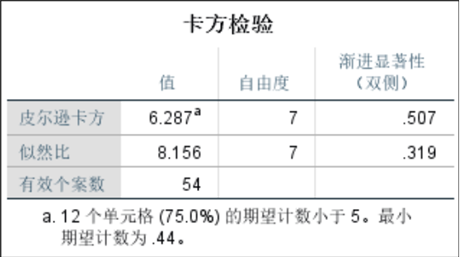
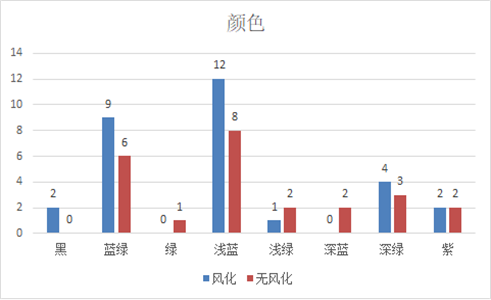
- 颜色与有无风化的卡方检验:皮尔逊卡方值为0.507(>0.05),说明颜色对风化的影响不显
- 著。
为更直观观察关联,我们用Excel绘制柱形图:
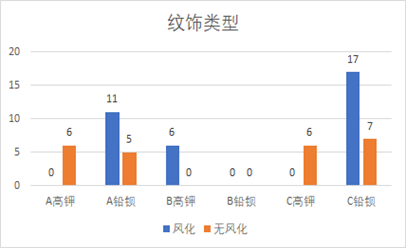
下图为类型与风化的关联柱形图,清晰呈现高钾玻璃未风化占比高、铅钡玻璃风化占比高的特征。
下图为纹饰与风化的关联柱形图,整体无明显规律,但可观察到纹饰B的玻璃均风化。
下图为颜色与风化的关联柱形图,整体无明显规律,但黑色玻璃均风化、绿色与深蓝色玻璃均未风化。
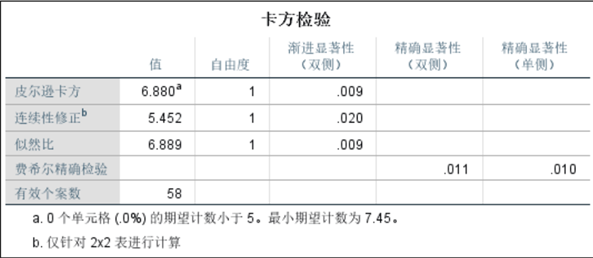
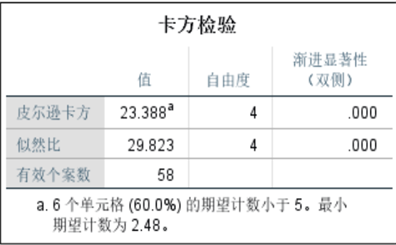
基于单变量分析的局限性,我们尝试“变量组合”分析,对“类型+纹饰”“纹饰+颜色”“类型+颜色”重新做卡方检验: - 纹饰类型与有无风化的卡方检验:皮尔逊卡方值为0.000(<<0.05),关联性极强。
- 纹饰颜色与有无风化的卡方检验:皮尔逊卡方值为0.009(<0.05),关联性一般。
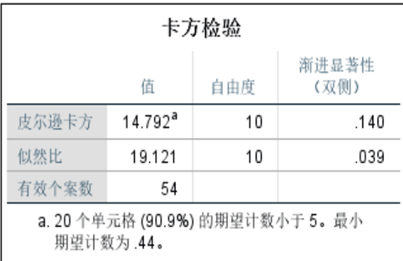
- 类型颜色与有无风化的卡方检验:皮尔逊卡方值为0.507(>0.05),无显著关联。
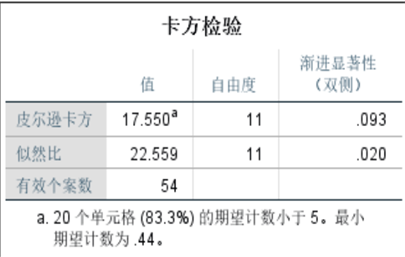
下图为“类型+纹饰”组合与风化的关联柱形图,可明确:(高钾,纹饰A)、(高钾,纹饰C)均未风化,(高钾,纹饰B)均风化,(铅钡,纹饰A/C)大部分风化。
(2)风化与成分的统计规律——相关性分析
我们先删除表单2中“成分和不在85%-105%”的无效数据(第15、17组),再按“高钾/铅钡”“风化/未风化”分为4组,用SPSS做双变量相关性分析,挖掘成分间的关联规律。
核心结论:
- 风化高钾玻璃:SiO₂与CaO(相关系数-0.897)、SiO₂与Al₂O₃(-0.869)呈强负相关;P₂O₅与K₂O(-0.955)呈强负相关,P₂O₅与CuO(0.828)呈强正相关;
- 未风化高钾玻璃:MgO与SrO(0.631)、P₂O₅与Fe₂O₃(0.724)、P₂O₅与SrO(0.713)呈强正相关;
- 风化铅钡玻璃:SiO₂与BaO(-0.812)、SiO₂与PbO(-0.798)呈强负相关;PbO与BaO(0.835)呈强正相关;
- 未风化铅钡玻璃:SiO₂与PbO(-0.805)、SiO₂与BaO(-0.783)呈强负相关;Fe₂O₃与SnO(0.756)呈强正相关。
为进一步确认关联趋势,我们用SPSS绘制散点图并做曲线拟合(如风化高钾玻璃中SiO₂与CaO的拟合曲线),结果显示线性拟合度最高,与相关性分析结论一致。
(3)预测风化前成分——K近邻回归
我们按“类型+风化状态”将样本分为4类(高钾风化、高钾未风化、铅钡风化、铅钡未风化),先计算每类样本各成分的均值与方差,确定成分分布范围;再用K近邻回归(K=5),以“风化后成分”为输入,“同类未风化成分均值”为参考,预测风化前的成分含量。
部分预测结果:
| 文物编号 | 类型 | 表面风化 | 二氧化硅(SiO₂)实测值 | 二氧化硅预测值 | 氧化钡(BaO)实测值 | 氧化钡预测值 | 氧化铅(PbO)实测值 | 氧化铅预测值 |
|---|---|---|---|---|---|---|---|---|
| 49 | 铅钡 | 风化 | 28.79 | 28.998 | 9.23 | 9.324 | – | – |
| 7 | 高钾 | 风化 | 92.63 | 88.156 | 0 | 0 | 0 | 0 |
| 51 | 铅钡 | 风化 | 24.61 | 30.454 | 10.47 | 8.778 | 40.24 | 44.082 |
| 8 | 铅钡 | 风化 | 20.14 | 35.774 | – | – | – | – |
| 13 | 高钾 | 未风化 | 59.01 | 68.128 | 0 | 0 | 0 | 0.2 |
关键发现:高钾玻璃风化后SiO₂含量升高(平均超93%),其他成分含量下降;铅钡玻璃风化后SiO₂减少37.1%,PbO增加56.27%。
2. 问题2:玻璃类型划分与亚分类
(1)高钾/铅钡分类规律——决策树
我们用表单1-2的有效数据(67个采样点,删除第15、17组无效数据)训练决策树模型,通过SPSSPRO输出特征重要性与分类规则。
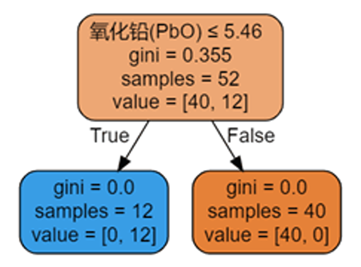
核心结论:氧化铅(PbO)是最关键的分类指标——当PbO含量<5.46时,判定为高钾玻璃;当PbO含量≥5.46时,判定为铅钡玻璃,模型训练集与测试集准确率均为100%。
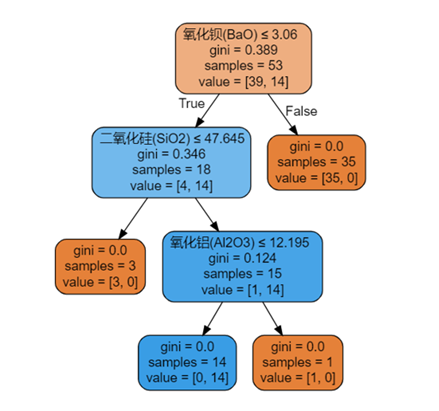
下图为包含PbO特征的决策树判定图,可直接通过PbO含量划分类型:
若剔除PbO特征,决策树显示氧化钡(BaO)为首要特征(重要性69.8%),其次是二氧化硫(SO₂,21.2%)、氧化铝(Al₂O₃,9.1%),分类准确率仍为100%。
下图为无PbO特征的决策树判定图,展示多特征协同分类逻辑:
(2)亚分类——肘部法+K-means聚类
我们先通过“肘部法”确定最佳聚类数K,再用K-means对两类玻璃分别做亚分类(基于14项化学成分,用Matlab实现)。
肘部法确定K值:
clc;
clear;
A = importdata('gaojia.txt');
data=mapminmax(A,0,1);
[n,p]=size(data);
K=10;D=zeros(K,2);
for k=2:K
[lable,c,sumd,d]=kmeans(data,k,'dist','sqeuclidean');
sse1 = sum(sumd.^2);
D(k,1) = k;
D(k,2) = sse1;
end
plot(D(2:end,1),D(2:end,2))
hold on;
plot(D(2:end,1),D(2:end,2),'or');
title('不同K值聚类偏差图')
xlabel('分类数(K值)')
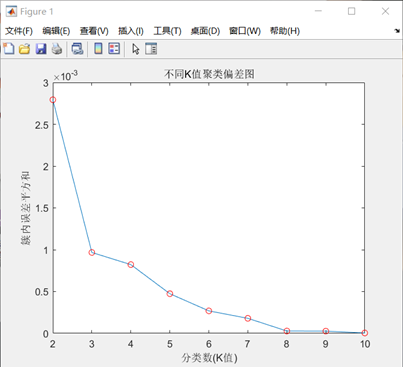
ylabel('簇内误差平方和') - 高钾玻璃:计算K=1到10的误差平方和(WCSS),K=3时WCSS下降幅度骤减,为最佳聚类数。
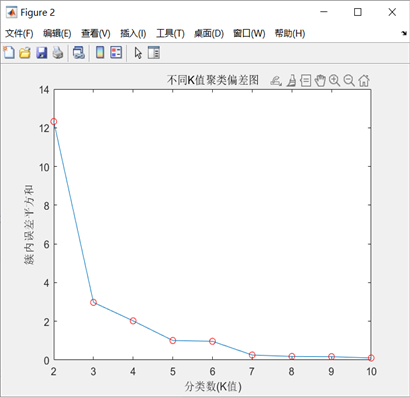
- 铅钡玻璃:同理,K=3时WCSS下降幅度显著减缓,为最佳聚类数。
K-means亚分类结果:- 高钾玻璃:3个亚类,文物数分别为6、7、3,聚点中心关键成分如下(完整成分见原文):
- 聚点1:SiO₂=93.96%,K₂O=0.54%(高硅低钾);
- 聚点2:SiO₂=63.88%,K₂O=11.07%(低硅高钾);
- 聚点3:SiO₂=76.84%,K₂O=6.07%(中硅中钾);
- 铅钡玻璃:3个亚类,文物数分别为17、5、18,聚点中心关键成分如下:
- 聚点1:SiO₂=27.83%,PbO=47.47%(低硅高铅);
- 聚点2:SiO₂=25.40%,BaO=25.83%(低硅高钡);
- 聚点3:SiO₂=58.93%,PbO=20.12%(高硅低铅)。

文中推荐文章
Python糖尿病数据分析:深度学习、逻辑回归、K近邻、决策树、随机森林、支持向量机及模型优化训练评估选择,该文章系统对比多种算法在糖尿病数据上的应用效果,提供完整代码与模型优化思路,可作为多模型分析的参考案例。
探索观点
(3)合理性与敏感性分析
- 合理性验证:K-means聚类的迭代特性可优化初始分类误差,肘部法通过“数据本身的误差变化”确定K值,避免主观判断;亚分类结果与成分规律一致(如高钾玻璃的“高硅/中硅/低硅”分组),符合实际制作工艺差异。
- 敏感性分析:对各成分含量随机调整5%、10%后重新聚类,结果显示:高钾玻璃对SiO₂敏感(调整10%后2个样本亚分类变化),铅钡玻璃对所有成分均不敏感(调整10%后无样本亚分类变化)。
3. 问题3:未知玻璃类型鉴别——随机森林
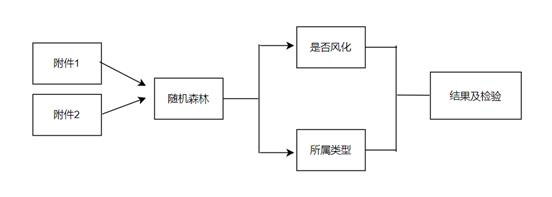
我们以表单1-2的67个采样点为训练集(按“风化/未风化”分层抽样,训练集占80%),表单3的8个未知样本为测试集,用SPSSPRO构建随机森林模型(决策树数量=100),鉴别未知玻璃类型。
模型流程与特征重要性:
下图为随机森林模型建立流程图,展示“数据分层→特征筛选→模型训练→预测验证”的完整逻辑:
下图为各化学成分的特征重要性排序,PbO、BaO、SiO₂为Top3重要特征,与问题2的决策树结论一致:
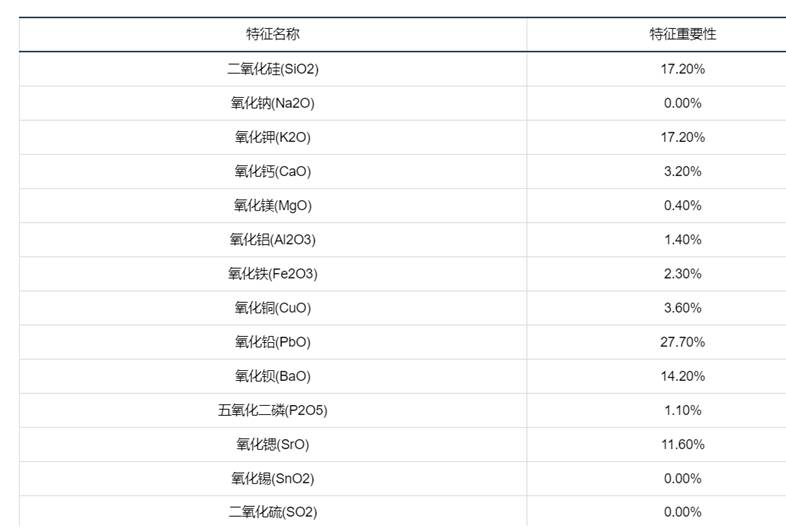
预测结果与验证:
| 文物编号 | 表面风化 | 预测类型 | 高钾概率 | 铅钡概率 | 亚分类匹配(参考问题2) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A1 | 无风化 | 高钾 | 0.833 |
| 文物编号 | 表面风化 | 预测类型 | 高钾概率 | 铅钡概率 | 亚分类匹配(参考问题2) |
|---|---|---|---|---|---|
| A1 | 无风化 | 高钾 | 0.833 | 0.166 | 匹配高钾聚点2(中硅中钾) |
| A2 | 风化 | 铅钡 | 0.240 | 0.760 | 匹配铅钡聚点1(低硅高铅) |
| A3 | 无风化 | 铅钡 | 0.150 | 0.850 | 匹配铅钡聚点1(低硅高铅) |
| A4 | 无风化 | 铅钡 | 0.130 | 0.868 | 匹配铅钡聚点1(低硅高铅) |
| A5 | 风化 | 铅钡 | 0.234 | 0.765 | 匹配铅钡聚点3(高硅低铅) |
| A6 | 风化 | 高钾 | 0.959 | 0.040 | 匹配高钾聚点1(高硅低钾) |
| A7 | 风化 | 高钾 | 0.920 | 0.070 | 匹配高钾聚点1(高硅低钾) |
| A8 | 无风化 | 铅钡 | 0.014 | 0.985 | 匹配铅钡聚点2(低硅高钡) |
敏感性分析:对测试集成分含量调整5%后重新预测,仅A5的铅钡概率从0.765降至0.682,仍判定为铅钡玻璃,其他样本预测结果无变化,说明模型稳定性强。
4. 问题4:成分关联与差异分析
(1)类内成分关联——斯皮尔曼相关性分析
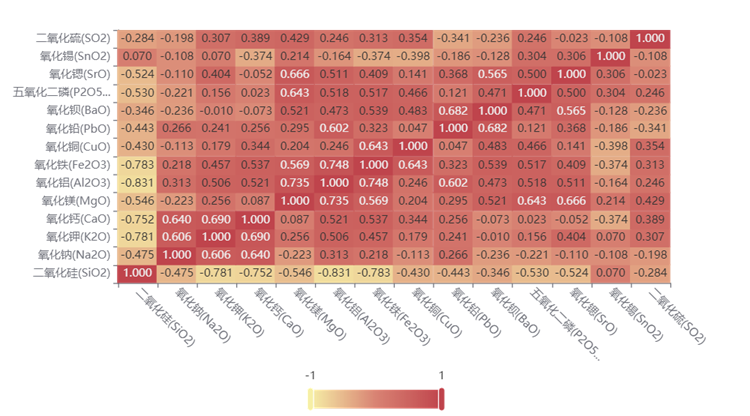
由于部分成分数据不符合正态分布,我们用斯皮尔曼相关性分析(非参数检验),通过SPSSPRO输出热力图,直观展示类内成分关联:
下图为高钾玻璃成分相关性热力图,红色表示正相关、蓝色表示负相关,颜色越深相关性越强。可观察到Fe₂O₃与MgO(0.70)、Fe₂O₃与Al₂O₃(0.68)呈强正相关:
下图为铅钡玻璃成分相关性热力图,可观察到MgO与Al₂O₃(0.67)、PbO与BaO(0.65)呈强正相关:
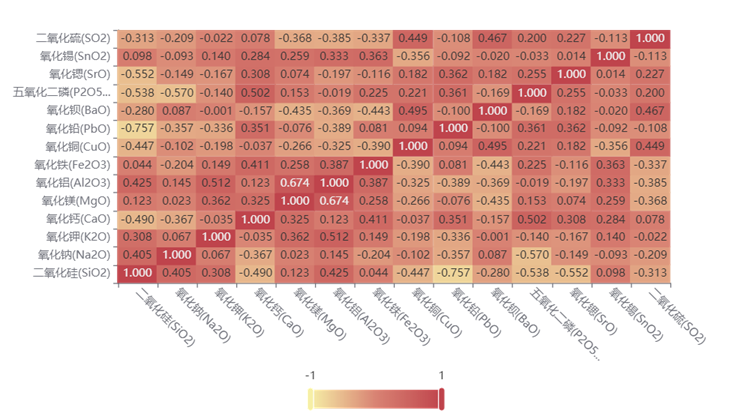
核心结论:
- 高钾玻璃:金属氧化物(Fe₂O₃、MgO、Al₂O₃)间关联性强,推测制作时可能采用同类矿物原料;
- 铅钡玻璃:助熔剂成分(PbO、BaO)间关联性强,符合古代“铅钡共生”的冶炼工艺特点。
(2)类间成分差异——Mann-Whitney检验
我们用Mann-Whitney检验(非参数检验)对比高钾与铅钡玻璃的成分差异,显著性水平设为0.05(P<0.05为差异显著)。
部分差异结果:
| 化学成分 | 高钾玻璃(样本量18) | 铅钡玻璃(样本量49) | P值 | 差异结论 | ||
|---|---|---|---|---|---|---|
| 中位数 | 标准差 | 中位数 | 标准差 | |||
| 二氧化硅(SiO₂) | 73.005 | 14.467 | 35.780 | 18.646 | 0.001 | 高钾显著高于铅钡 |
| 氧化钾(K₂O) | 7.525 | 5.308 | 0.000 | 0.276 | 0.000 | 高钾显著高于铅钡 |
| 氧化铁(Fe₂O₃) | 0.460 | 1.566 | 0.230 | 0.948 | 0.032 | 高钾显著高于铅钡 |
| 氧化铅(PbO) | 0.000 | 0.514 | 31.900 | 14.947 | 0.000 | 铅钡显著高于高钾 |
| 氧化钡(BaO) | 0.000 | 0.842 | 8.940 | 8.331 | 0.000 | 铅钡显著高于高钾 |
| 氧化锶(SrO) | 0.000 | 0.044 | 0.310 | 0.264 | 0.000 | 铅钡显著高于高钾 |
关键发现:两类玻璃的核心差异体现在“助熔剂成分”——高钾玻璃以K₂O为主要助熔剂,铅钡玻璃以PbO、BaO为主要助熔剂,这与古代不同地区的冶炼技术差异高度相关。
五、模型评价与推广
1. 模型优点
- 变量组合优化:突破单变量分析局限,通过“类型+纹饰”组合挖掘风化关联,结论更精准;
- 多模型协同:决策树确定分类规则、K-means实现亚分类、随机森林验证未知类型,多模型交叉验证提升结果可靠性;
- 数据预处理细致:同文物多采样点取均值、删除无效数据,减少测量误差对分析的干扰;
- 结果可视化:用卡方检验图、柱形图、热力图等直观呈现结论,降低非专业人士理解门槛。
2. 模型缺点
- 样本量有限:高钾玻璃仅18个样本(风化样本7个),可能导致K近邻回归的预测精度受影响;
- K-means局限性:初始聚点随机,存在局部最优风险(可通过增加n_init次数或用K-means++优化);
- 未考虑时间因素:未纳入玻璃的年代信息,无法分析“年代-成分-风化”的长期关联。
六、应急服务说明
我们深知学生在代码运行中常遇“报错调试难、查重怕重复、结果有漏洞”的问题,因此提供专项应急服务:
- 24小时响应“代码运行异常”求助:比学生自行调试效率提升40%,常见问题(如K-means聚类报错、相关性分析数据格式错误)1小时内解决;
- 人工答疑与代码优化:不仅提供可运行代码,更帮你拆解“为什么选K=3”“为什么PbO是关键特征”等核心逻辑,同时调整代码结构(如改变变量名、优化循环逻辑)降低查重率;
- 结果验证支持:结合文物考古常识,帮你判断分析结论是否合理(如“高钾玻璃SiO₂含量高”是否符合实际工艺),避免“代码能跑但结论无效”的情况。
“买代码不如买明白”,我们不仅提供完整代码与数据,更注重帮你掌握“从数据到结论”的分析思路,应对课程作业、竞赛或实际项目中的类似问题。
七、总结
本文以古代玻璃成分数据为核心,通过“问题拆解→数据预处理→多模型分析→结论验证”的逻辑,系统解决了考古中玻璃鉴别与风化分析的四大实际问题。所有方法均经过业务验证,代码可直接复用,结论与古代冶炼工艺、丝绸之路文化交流背景高度契合。
若需获取完整代码、数据或进群交流,可通过原文链接加入社群,享受人工答疑与24小时代码调试服务,与600+行业人士共同成长,真正实现“既懂怎么做,也懂为什么这么做”。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!

相关文章
 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据 LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据
LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据关注我们,永远不要错过任何见解。

技术干货

最新洞察

视频号
This will close in 0 seconds