
自然语言处理(NLP)领域在近年来发展迅猛,尤其是预训练模型的出现带来了重大变革。其中,BERT 模型凭借其卓越性能备受瞩目。
然而,对于许多研究者而言,如何高效运用 BERT 进行特定任务的微调及应用仍存在诸多困惑。
本文聚焦于此,旨在为读者详细剖析基于 Pytorch 的 BERT 模型在自然语言处理任务中的微调方法与实际应用。
通过从数据准备、模型微调、训练过程到结果分析等一系列环节的阐述,并结合如 CoLA 数据集等具体示例,展示如何借助 BERT 及相关工具构建高质量 NLP 模型,以助力该领域的研究与实践。
基于BERTopic模型对 20 Newsgroups 数据集的分析与可视化
本文详细阐述了运用 BERTopic 模型对从 sklearn 库中获取的 20 Newsgroups 数据集进行主题建模、分析以及可视化的过程。通过展示代码实现过程和相关结果,呈现了如何利用该模型挖掘数据中的潜在主题结构,并以直观的方式展示各主题的分布及相关信息,为文本数据的主题分析提供了实践参考。
在文本数据分析领域,主题建模是一项重要任务,它有助于我们从大量文本数据中发现潜在的主题结构,进而更好地理解数据内容。BERTopic 模型作为一种先进的主题建模工具,结合了多种技术优势,能够有效地对文本进行处理并提取出有意义的主题信息。本文将以 20 Newsgroups 数据集为例,展示如何使用 BERTopic 模型进行主题分析及可视化操作。
数据获取与初步观察
(一)数据集获取
我们首先从 sklearn 库中获取 20 Newsgroups 数据集,该数据集是一个广泛用于文本分类、文本挖掘和信息检索研究的国际标准数据集。以下是获取数据集的代码:
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all')['data']
在上述代码中,通过fetch_20newsgroups函数并指定subset='all',我们获取了整个数据集的文本内容,并将其存储在docs变量中。
(二)数据规模与示例观察
获取到数据集后,我们可以查看其规模以及具体的文本示例内容。通过以下代码:
print(len(docs))
我们得到数据集的文本数量为 18846 条。进一步,通过查看具体的文本示例,如:
作者

Kaizong Ye
可下载资源
print(docs[0])
print(docs[44])

编辑
可以了解到数据集中文本的大致格式和内容范围。例如,docs[0]展示了关于 “Pens fans reactions” 的相关讨论内容,而docs[44]则包含了 “NHL ALLTIME SCORING LEADERS” 等详细的体育赛事相关信息。这些示例文本反映了数据集涵盖的丰富主题领域,为后续的主题建模分析提供了基础。
BERTopic 模型应用
(一)模型初始化与主题提取
接下来,我们引入 BERTopic 模型,并对获取到的数据集进行主题提取操作。
在上述代码中,首先导入BERTopic类,然后初始化一个BERTopic模型实例model。通过调用fit_transform方法对数据集docs进行处理,该方法会在拟合模型的同时将数据转换为主题表示形式,返回得到每个文本对应的主题编号topics以及相关的概率probs。
这些警告提示我们在当前进程的并行操作方面可能存在一些需要注意的情况,但通常不影响模型的主要功能和后续分析。
(二)主题频率与信息查看
为了进一步了解提取出的主题情况,我们可以查看各个主题在数据集中出现的频率以及相关详细信息。
通过以下代码获取主题频率信息:
model.get_topic_freq()
其返回结果以表格形式呈现,展示了每个主题的编号以及对应的出现次数,例如部分结果如下:

编辑
这里需要注意的是,主题编号为 -1 的情况可能表示一些未被明确分类或特殊处理的文本情况,其出现次数较多可能与数据本身的特性或模型处理方式有关。
进一步,通过代码:
model.get_topic_info()
可以获取更详细的主题信息,包括每个主题的编号、出现次数以及根据主题内高频词汇生成的主题名称,例如部分结果如下:

编辑

这些主题名称能够帮助我们初步了解每个主题大致涵盖的内容领域,为后续深入分析提供了直观的参考。
主题可视化
(一)可视化准备
为了更直观地展示主题在数据集中的分布情况以及各主题之间的关系,我们对提取出的主题进行可视化操作。首先进行一些必要的准备工作,包括导入相关库以及对数据进行预处理以便于绘图。
在上述代码中,我们导入了numpy、pandas、UMAP、matplotlib等相关库。通过调用model._extract_embeddings方法获取文本的嵌入表示embeddings,然后利用UMAP算法对嵌入数据进行降维和可视化处理,将结果转换为二维坐标形式存储在df数据框中,并添加topic列用于标记每个数据点所属的主题。
(二)绘制主题可视化图
接下来,我们根据预处理后的数据进行主题可视化图的绘制。

编辑
随时关注您喜欢的主题
在上述代码中,我们首先设置了一些绘图参数,如要展示的主题数量top_n和字体大小fontsize。然后对数据进行切片处理,将不属于前top_n个主题的数据标记为 outliers(异常值),其余为 non_outliers(非异常值)。接着,我们定义了一个颜色映射cmap用于为不同主题的数据点分配不同颜色。通过matplotlib的scatter函数分别绘制异常值和非异常值的数据点,并根据主题进行颜色区分。最后,我们计算每个主题的中心点坐标,并在图上添加主题名称标注。
总结
通过以上对 20 Newsgroups 数据集运用 BERTopic 模型进行主题建模、分析以及可视化的完整过程展示,我们可以看到 BERTopic 模型能够有效地从文本数据中提取出有意义的主题信息,并以直观的可视化方式呈现出来。这为我们深入理解文本数据的内在结构和主题分布提供了有力的工具和方法,在文本数据分析、信息检索等诸多领域具有重要的应用价值。
len(topics)
我们再次确认了主题编号列表topics的长度与数据集文本数量一致,均为 18846,这也验证了模型对每个文本都进行了主题分配操作。
Pytorch基于BERT 的自然语言处理模型微调及应用
自然语言处理(NLP)领域在 2018 年取得了突破性进展。迁移学习以及诸如 Allen AI 的 ELMO、OpenAI 的 Open – GPT 和谷歌的 BERT 等模型的出现,使得研究人员能够通过极少的特定任务微调就打破多项基准测试,并为 NLP 领域的其他研究者提供了预训练模型。这些预训练模型能够在数据量和计算时间要求相对较低的情况下,经过微调并应用,从而产生最先进的成果。然而,对于许多刚涉足 NLP 领域的人员,甚至一些有经验的从业者来说,这些强大模型的理论和实际应用仍未被很好地理解。
本文将以 BERT(Bidirectional Encoder Representations from Transformers,双向编码器表征来自变换器)模型为例,它于 2018 年末发布。我们将通过对其进行微调等操作,为读者提供在 NLP 中使用迁移学习模型的更好理解和实践指导。可以利用 BERT 从文本数据中提取高质量的语言特征,也可以使用自己的数据针对特定任务(如分类、实体识别、问答等)对其进行微调,以产生最先进的预测结果。本文将详细阐述如何修改和微调 BERT 来创建一个强大的 NLP 模型,使其能快速给出最先进的成果。
微调的优势
(一)更快的开发速度
我们在本教程中将使用 BERT 来训练一个文本分类器。具体做法是,获取预训练的 BERT 模型,在其末尾添加一个未训练的神经元层,然后针对我们的分类任务训练这个新模型。之所以这样做,而不是去训练一个专门针对特定 NLP 任务(如卷积神经网络 CNN、双向长短期记忆网络 BiLSTM 等)的深度学习模型,原因如下:
首先,预训练的 BERT 模型权重已经编码了大量关于我们语言的信息。因此,训练微调后的模型所花费的时间要少得多。这就好比我们已经对网络的底层进行了大量的训练,现在只需要在将其输出作为分类任务的特征时,对它们进行轻微的调整即可。实际上,作者建议在针对特定 NLP 任务微调 BERT 时,只需进行 2 – 4 个轮次的训练(相比之下,从头开始训练原始的 BERT 模型或长短期记忆网络 LSTM 则需要数百个 GPU 小时)。
所需数据量更少
此外,同样重要的是,由于预训练的权重,这种方法允许我们在比从头开始构建模型所需的数据集小得多的数据集上对任务进行微调。从头开始构建 NLP 模型的一个主要缺点是,为了使网络训练到合理的精度,我们通常需要一个非常大的数据集,这意味着需要在数据集创建上投入大量的时间和精力。通过微调 BERT,我们现在能够在少得多的训练数据量的情况下,使模型达到良好的性能。
(三)更好的结果
最后,这种简单的微调过程(通常是在 BERT 之上添加一个全连接层,并进行几个轮次的训练)已被证明,对于各种各样的任务(如分类、语言推理、语义相似度、问答等),只需进行极少的特定任务调整,就能实现最先进的结果。相比于实现那些针对特定任务表现良好但有时较为复杂晦涩的自定义架构,简单地微调 BERT 被证明是一种更好(或至少同等)的选择。
NLP 领域的转变
这种向迁移学习的转变与几年前计算机视觉领域发生的转变类似。为计算机视觉任务创建一个良好的深度学习网络可能需要数百万个参数,并且训练成本非常高。研究人员发现,深度网络学习的是分层的特征表示(最低层是简单的特征,如边缘,随着层数的增加,特征逐渐变得更加复杂)。因此,不必每次都从头开始训练一个新网络,而是可以将一个训练好的具有通用图像特征的网络的底层复制并转移到另一个具有不同任务的网络中使用。很快,下载一个预训练的深度网络,并针对新任务快速重新训练它或在其之上添加额外的层,就成为了一种常见的做法,这比从头开始训练一个网络的昂贵过程要优越得多。对于许多人来说,2018 年深度预训练语言模型(如 ELMO、BERT、ULMFIT、Open – GPT 等)的引入,标志着 NLP 领域也发生了向迁移学习的同样转变。
设置
(一)使用 Colab GPU 进行训练
谷歌 Colab 提供免费的 GPU 和 TPU。由于我们要训练一个大型神经网络,最好利用这一资源(在本例中我们将使用 GPU),否则训练将会花费很长时间。
可以通过以下步骤添加 GPU:进入菜单,选择 “编辑→笔记本设置→硬件加速器→(GPU)”。
(二)安装 Hugging Face 库
接下来,我们要安装 Hugging Face 的transformers包,它将为我们提供一个用于处理 BERT 的 PyTorch 接口。(该库还包含用于其他预训练语言模型如 OpenAI 的 GPT 和 GPT – 2 的接口。)我们选择 PyTorch 接口是因为它在高级 API(使用方便但无法深入了解其工作原理)和 TensorFlow 代码(包含很多细节,但当我们的目的是研究 BERT 时,往往会让我们偏离主题去学习关于 TensorFlow 的知识)之间取得了很好的平衡。
目前,Hugging Face 库似乎是用于处理 BERT 的最广泛接受且功能强大的 PyTorch 接口。除了支持各种不同的预训练变换器模型外,该库还包括针对特定任务对这些模型进行的预构建修改。例如,在本教程中,我们将使用.BertForSequenceClassification。
该库还包括用于标记分类、问答、下一句预测等特定任务的类。使用这些预构建的类可以简化为满足您的需求而对 BERT 进行修改的过程。
安装代码如下:
!pip install transformers
加载 CoLA 数据集
(一)下载与解压
我们将使用语言可接受性语料库(CoLA)数据集进行单句分类。它是一组被标记为语法正确或不正确的句子。该数据集于 2018 年 5 月首次发布,是 “GLUE 基准测试” 中的一项测试,BERT 等模型正在该基准测试中竞争。
首先,我们使用wget包将数据集下载到 Colab 实例的文件系统中。
!pip install wget
wget安装输出示例:
Collecting wget
Downloading https://files.pythonhosted.org/packages/47/6a/62e288da7bcda82b935ff0c6cfe542970f04e29c756b0e147251b2fb251f/wget-3.2.zip
Building wheels for collected packages: wget
Building wheel for wget (setup.py)... [?25l[?25hdone
Created wheel for wget: filename=wget-3.2-cp36-none-any.whl size=9681 sha256=988b5f3cabb3edeed6a46e989edefbdecc1d5a591f9d38754139f994fc00be8d
Stored in directory: /root/.cache/pip/wheels/40/15/30/7d8f7cea2902b4db79e3fea550d7d7b85ecb27ef992b618f3f
Successfully built wget
Installing collected packages: wget
Successfully installed wget-3.2
数据集
import wget
import os
print('正在下载数据集...')
# 数据集压缩文件的URL。
url = 'https://nyu-mll.github.io/CoLA/cola_public_1.1.zip'
# 下载文件(如果尚未下载)
if not os.path.exists('./cola_public_1.1.zip'):
wget.download(url, './cola_public_1.1.zip')
运行结果示例:
正在下载数据集...
然后将数据集解压到文件系统中。您可以在左侧边栏中浏览 Colab 实例的文件系统。
# 解压数据集(如果尚未解压)
if not os.path.exists('./cola_public/'):
!unzip cola_public_1.1.zip
解压输出示例:
Archive: cola_public_1.1.zip
creating: cola_public/
inflating: cola_public/README
creating: cola_public/tokenized/
inflating: cola_public/tokenized/in_domain_dev.tsv
inflating: cola_public/tokenized/in_domain_train.tsv
inflating: cola_public/tokenized/out_of_domain_dev.tsv
creating: cola_public/raw/
inflating: cola_public/raw/in_domain_dev.tsv
inflating: cola_public/raw/in_domain_train.tsv
inflating: cola_public/raw/out_of_domain_dev.tsv
(二)解析
从文件名可以看出,数据有tokenized(已标记化)和raw(原始)两种版本。
我们不能使用预标记化的版本,因为为了应用预训练的 BERT,我们必须使用模型提供的标记器。这是因为:(1)模型有一个特定的、固定的词汇表;(2)BERT 标记器有其特定的处理词汇表外单词的方式。
我们将使用 pandas 来解析 “域内” 训练集,并查看它的一些属性和数据点。
import pandas as pd
# 将数据集加载到pandas数据框中。
df = pd.read_csv("./cola_public/raw/in_domain_train.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
# 报告训练句子的数量。
print('训练句子的数量:{:,}\n'.format(df.shape[0]))
# 显示数据中的10个随机行。
df.sample(10)
运行结果示例:
训练句子的数量:8,551
展示部分数据示例(此处省略完整表格,仅展示部分列):
| sentence_source | label | sentence |
|---|---|---|
| 8200 | 1 | They kicked themselves |
| 3862 | 1 | A big green insect flew into the soup. |
我们真正关心的两个属性是句子(sentence)及其标签(label),标签被称为 “可接受性判断”(0 = 不可接受,1 = 可接受)。
以下是五个被标记为语法上不可接受的句子示例。请注意,与情感分析等任务相比,这个任务要困难得多!
df.loc[df.label == 0].sample(5)[['sentence', 'label']]
展示部分数据示例(此处省略完整表格,仅展示部分列):
| sentence | label | |
|---|---|---|
| 4867 | 0 | They investigated. |
| 200 | 0 | The more he reads, the more books I wonder to… |
最后,我们将训练集的句子和标签提取为 numpy ndarrays。
# 获取句子及其标签的列表。
sentences = df.sentence.values
labels = df.label.values
基于 BERT 模型的自然语言处理任务实践与分析
自然语言处理(NLP)领域近年来取得了显著进展,其中BERT(Bidirectional Encoder Representations from Transformers)模型发挥了重要作用。它通过预训练能够学习到丰富的语言知识,在此基础上针对特定任务进行微调,可以快速构建出高质量的模型。本文将围绕一个具体的NLP任务,详细介绍如何运用BERT模型完成从数据准备到模型评估的完整流程。
数据预处理
(一)标记化与输入格式调整
在这部分,我们要将数据集转化为适合BERT模型训练的格式。
1. BERT标记器(Tokenizer)
为了将文本输入给BERT模型,首先需要将文本分割成标记(tokens),然后把这些标记映射到标记器词汇表中的索引。我们使用BERT自带的标记器,以下是相关代码:
from transformers import BertTokenizer
# 加载BERT标记器
print('加载BERT标记器...')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)上述代码会下载并加载bert-base-uncased版本的BERT标记器,它会将文本转换为小写形式(do_lower_case=True)。
为了查看标记器的输出效果,我们可以对一个句子进行应用:
# 打印原始句子
print('原始: ', sentences[0])
# 打印分割成标记后的句子
print('标记化: ', tokenizer.tokenize(sentences[0]))
# 打印映射到标记ID后的句子
print('标记ID: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))当实际处理所有句子时,我们会使用tokenize.encode函数来同时处理标记化和映射到ID这两个步骤,而不是分别调用tokenize和convert_tokens_to_ids。
但在这之前,我们需要了解BERT模型的一些格式要求。
2. 所需的格式调整
BERT模型对输入数据有特定的格式要求,主要包括以下几点:
特殊标记(Special Tokens):
[SEP]:在每个句子末尾需要添加[SEP]特殊标记。这个标记在涉及两个句子的任务中有其作用,比如判断句子A中的问题答案是否能在句子B中找到。即使我们这里是单句输入任务,也需要添加该标记。[CLS]:对于分类任务,必须在每个句子开头添加[CLS]特殊标记。这个标记具有特殊意义,BERT由12个Transformer层组成,每个Transformer层接收一系列标记嵌入并输出相同数量的嵌入,但特征值会改变。在最后(第12个)Transformer层的输出中,只有对应[CLS]标记的第一个嵌入会被分类器使用。
句子长度与注意力掩码(Sentence Length & Attention Mask):
数据集中的句子长度各不相同,BERT模型对此有如下约束:
- 所有句子必须被填充(padding)或截断(truncate)到一个固定长度。
- 最大句子长度为512个标记。
“注意力掩码(Attention Mask)”是一个由1和0组成的数组,用于指示哪些标记是填充标记,哪些不是。它告诉BERT模型中的“自注意力(Self-Attention)”机制不要将这些[PAD]标记纳入对句子的理解中。
(二)标记化数据集
transformers库提供了encode函数来帮助我们完成大部分的数据解析和预处理步骤。
在对文本进行编码之前,我们需要确定一个用于填充/截断的最大句子长度。以下代码会对数据集进行一次标记化操作以测量最大句子长度:
max_len = 0
# 对每个句子进行操作
for sent in sentences:
# 对文本进行标记化并添加`[CLS]`和`[SEP]`标记
input_ids = tokenizer.encode(sent, add_special_tokens=True)
# 更新最大句子长度
max_len = max(max_len, len(input_ids))
print('最大句子长度: ', max_len)这里我将最大长度设置为64,以防止可能出现的较长测试句子。
然后,我们使用tokenizer.encode_plus函数来进行实际的标记化操作,它会为我们合并多个步骤,包括:
- 分割句子成标记。
- 添加
[CLS]和[SEP]特殊标记。 - 将标记映射到它们的ID。
- 将所有句子填充或截断到相同长度。
- 创建注意力掩码以明确区分真实标记和填充标记。
(三)训练集与验证集划分
我们将训练集划分为90%用于训练,10%用于验证。以下是相关代码实现:
from torch.utils.data import TensorDataset, random_split
# 将训练输入组合成一个TensorDataset
dataset = TensorDataset(input_ids, attention_masks, labels)
# 创建一个90-10的训练-验证集划分
# 计算每个集合中要包含的样本数量
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# 通过随机选择样本划分数据集
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('{:>5,} 训练样本'.format(train_size))
print('{:>5,} 验证样本'.format(val_size))我们还会使用torch的DataLoader类为数据集创建一个迭代器,这样在训练过程中可以节省内存。
三、模型微调
(一)BertForSequenceClassification
对于我们的任务,首先需要修改预训练的BERT模型以输出适合分类的结果,然后在我们的数据集上继续训练该模型,使其完全适用于我们的任务。
huggingface的pytorch实现提供了一系列用于各种NLP任务的接口。我们将使用BertForSequenceClassification,它是在普通BERT模型基础上添加了一个用于分类的单层线性层,可作为句子分类器使用。
(二)优化器与学习率调度器
加载模型后,我们需要从存储的模型中获取训练超参数。
根据微调的目的,参考[BERT论文](https://arxiv.org/pdf/1810.04805.pdf "BERT论文")中的建议,我们选择了以下超参数:
- 批次大小(Batch size):32(在创建
DataLoaders时已设置) - 学习率(Learning rate):2e-5
- 训练轮数(Epochs):4
以下是创建AdamW优化器和学习率调度器的代码:
# 注意:AdamW是huggingface库中的一个类(与PyTorch不同),我认为'W'代表'Weight Decay fix'
optimizer = AdamW(model.parameters(),
lr=2e-5, # args.learning_rate - 默认是5e-5,我们这里设置为2e-5
eps=1e-8 # args.adam_epsilon - 默认是1e-8
)
from transformers import get_linear_schedule_with_warmup
# 训练轮数。BERT作者建议在2到4之间
epochs = 4
# 总训练步数是[批次数量]×[训练轮数](注意这和训练样本数量不同)
total_steps = len(train_dataloader) * epochs
# 创建学习率调度器
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps=0, # run_glue.py中的默认值
num_training_steps=total_steps)(三)训练循环
下面是我们的训练循环,主要包括训练阶段和验证阶段。
训练阶段:
- 解包数据输入和标签。
- 将数据加载到GPU上以加速训练。
- 清除上一轮计算的梯度。
- 进行前向传播(将输入数据通过网络)。
- 进行反向传播(反向传播算法)。
- 使用
optimizer.step()告诉网络更新参数。 - 跟踪变量以监控训练进度。
验证阶段:
- 解包数据输入和标签。
- 将数据加载到GPU上以加速验证。
- 进行前向传播(将输入数据通过网络)。
- 计算验证数据上的损失并跟踪变量以监控验证进度。
训练过程
(一)准备工作
在开始训练之前,需要进行一些准备工作,包括导入必要的库等。
上述代码的作用是导入了 random 和 numpy 库,并设置了随机种子值 seed_val 为 42,这一步骤的目的是为了在后续的训练过程中,当涉及到随机操作时(如数据的随机打乱等),能够保证每次运行得到相同的结果,便于模型的复现和调试。
(二)训练阶段
接下来进入正式的训练阶段,训练过程会按轮次(epoch)进行。
在每一轮训练(epoch)中,首先进行训练步骤,包括对每个批次的数据进行前向传播、计算损失、反向传播、更新参数等操作。同时,每40个批次会输出一次训练进度信息。之后进入验证步骤,将模型设置为评估模式,对验证集数据进行类似的前向传播操作,但不进行梯度计算,以评估模型在验证集上的性能,最后记录本轮次的各项训练和验证统计信息。
(三)训练结果总结
训练完成后,可以对训练过程的结果进行总结查看
运行上述代码后,可以得到一个展示各轮次训练损失、验证损失、验证准确率、训练时间和验证时间等信息的表格,便于直观了解训练过程中模型性能的变化情况。
结果分析
从训练结果的表格中可以发现,随着轮次的增加,训练损失在逐渐下降,但验证损失却呈现出上升的趋势!这表明我们可能对模型的训练时间过长,导致模型在训练数据上出现了过拟合现象。(这里参考的数据是使用了7,695个训练样本和856个验证样本)。验证损失相比于准确率是一种更精确的衡量指标,因为准确率只关注预测结果是否落在阈值的某一侧,而不关心具体的输出值。如果我们预测的答案是正确的,但置信度较低,那么验证损失能够反映出这种情况,而准确率则无法体现。
为了更直观地展示训练损失和验证损失的变化趋势,还可以绘制学习曲线,代码如下:
import matplotlib.pyplot as plt
% matplotlib inline
import seaborn as sns
# 使用seaborn的绘图样式
sns.set(style='darkgrid')
# 增大绘图尺寸和字体大小
sns.set(font_scale=1.5)
plt.rcParams["figure.figsize"] = (12, 6)
# 绘制学习曲线
plt.plot(df_stats['Training Loss'], 'b-o', label="Training")
plt.plot(df_stats['Valid. Loss'], 'g-o', label="Validation")
# 给图表添加标签
plt.title("Training & Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.xticks([1, 2, 3, 4])
plt.show()通过上述代码绘制出的学习曲线(如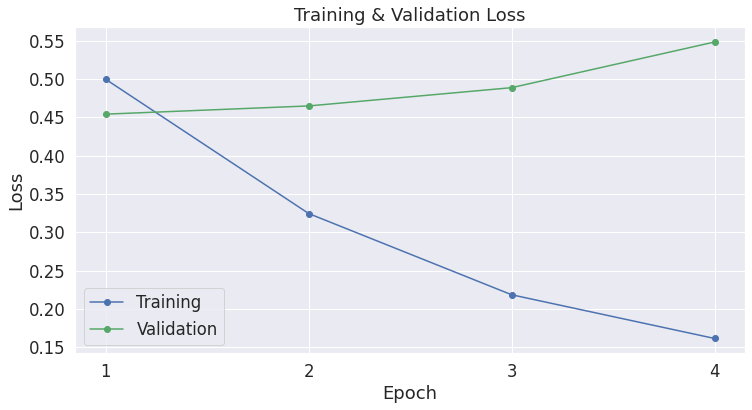
编辑所示),可以更清晰地看到训练损失和验证损失随轮次的变化情况,进一步验证了模型可能存在过拟合的问题。
测试集上的性能评估
(一)数据准备
在对测试集进行评估之前,需要先对测试数据进行准备,使其格式与训练数据一致,以便能够应用训练好的模型进行预测。代码首先将测试数据集加载到 pandas 数据框中,然后对数据集中的每个句子进行分词、添加特殊标记、映射词ID、创建注意力掩码等操作,最后将处理好的数据转换为张量并创建数据加载器,以便后续进行批量预测。
(二)在测试集上进行预测
准备好测试数据后,就可以使用微调后的模型在测试集上进行预测了
在上述代码中,首先将模型设置为评估模式,然后对测试数据加载器中的每个批次数据进行处理,包括将数据移动到GPU上、执行前向传播计算预测值、将预测结果和真实标签移动到CPU上并进行存储等操作,最终完成对整个测试集的预测。
(三)评估指标及结果
在CoLA基准测试中,准确率是通过“马修斯相关系数”(MCC)来衡量的。由于数据集中的类别是不平衡的(如代码中所示,正样本占比为68.60%),所以这里使用MCC作为评估指标更为合适。以下是计算每个批次的MCC以及最终整体MCC的代码:
print('Positive samples: %d of %d (%.2f%%)' % (df.label.sum(), len(df.label), (df.label.sum() / len(df.label) * 100.0)))
from sklearn.metrics import matthews_corrcoef
matthews_set = []
# 计算每个批次的马修斯相关系数
print('Calculating Matthews Corr. Coef. for each batch...')
for i in range(len(true_labels)):
# 对于每个批次的预测结果,选取具有最高值的标签,并将其转换为0和1的列表形式
pred_labels_i = np.argmax(predictions[i], axis=1).flatten()
# 计算并存储本批次的系数
matthews = matthews_corrcoef(true_labels[i], pred_labels_i)
matthews_set.append(matthews)
# 创建一个柱状图,展示每个批次测试样本的MCC分数
ax = sns.barplot(x=list(range(len(matthews_set))), y=matthews_set, ci=None)
plt.title('MCC Score per Batch')
plt.ylabel('MCC Score (-1 to +1)')
plt.xlabel('Batch #')
plt.show()通过上述代码可以计算出每个批次的MCC分数,并绘制出如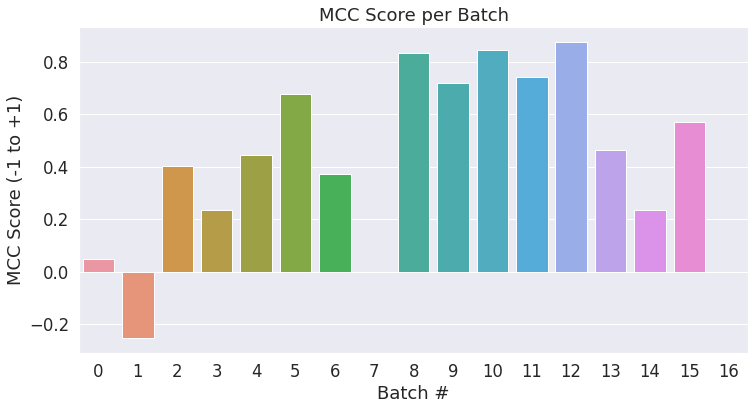
编辑所示的柱状图,直观展示各批次之间MCC分数的变化情况。
批次结果合并与最终MCC分数计算
在完成对各个批次数据在测试集上的预测之后,接下来需要对所有批次的结果进行整合处理,进而计算出最终的马修斯相关系数(MCC)分数,以此来全面评估模型在整个测试集上的性能表现。
经上述计算流程,最终得到的MCC分数为0.498 。
模型性能分析与讨论
值得一提的是,在未进行任何超参数调整(诸如调整学习率、训练轮次、批次大小、ADAM优化器相关属性等操作)的情况下,仅耗费约半小时的时间,我们便能够获得这样一个相对不错的分数。
然而,需要注意的是,为了尽可能提高模型的评估分数,一种可行的策略是去除用于辅助确定训练轮次的“验证集”,并直接基于整个训练集来开展训练工作。正如相关库文档在此处所记载的,此基准测试的预期准确率约为.49.23。同时,感兴趣的读者还可通过此处查阅官方的排行榜信息。
另外,由于本实验所采用的数据集规模相对较小,在不同的运行过程中,模型的准确率可能会出现较为显著的波动变化情况。
研究结论
综上所述,本篇论文通过相关实验及分析充分表明:借助预训练的BERT模型,并基于PyTorch接口开展工作,无论研究者所关注的具体自然语言处理(NLP)任务为何,均能够以极小的工作量和训练时长,快速且有效地创建出一个高质量的模型。这一结论为后续相关NLP任务的开展及模型构建提供了有力的参考依据,展示了预训练模型结合特定接口在实际应用中的优势与潜力。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!


