
我们在这里讨论所谓的“分段线性回归模型”,因为它们利用包含虚拟变量的交互项。
读取数据
可下载资源
data=read.csv("artificial-cover.csv")
查看部分数据
head(data)
## tree.cover shurb.grass.cover
## 1 13.2 16.8
## 2 17.2 21.8
## 3 45.4 48.8
## 4 53.6 58.7
## 5 58.5 55.5
## 6 63.3 47.2###########用lm拟合,主要注意部分是bs(age,knots=c(...))这部分把自变量分成不同部分
fit =lm(tree.cover~bs(shurb.grass.cover ,knots
############进行预测,预测数据也要分区
pred= predict (fit , newdata =list(shurb.grass.cover =data$shurb.grass.cover),se=T)
#############然后画图
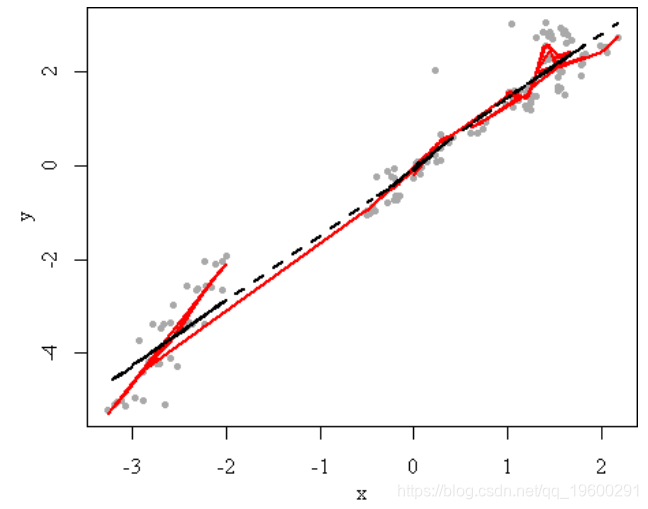
plot(fit)可以构造一个相对复杂的 LOWESS 模型(span参数取小一些),然后和一个简单的模型比较,如:

qplot(x, y) + geom_smooth() # 总趋势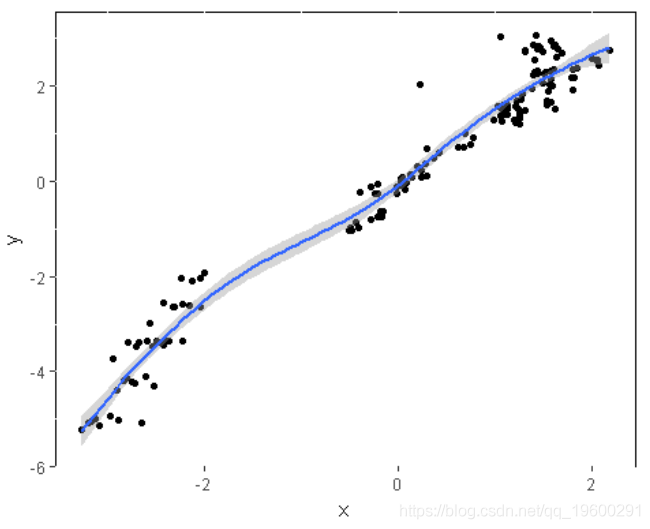
散点图分为两部分
我们可以将原始散点图分为两部分,并拟合两条单独但相连的线。估计的分段式函数连接,在描述数据趋势方面做得更好。
因此,让我们为这些数据建立一个分段线性回归模型并可视化:
0) + geom_smooth() +
theme(panel.background = element_rect(fill = 'white', colour = 'black')) 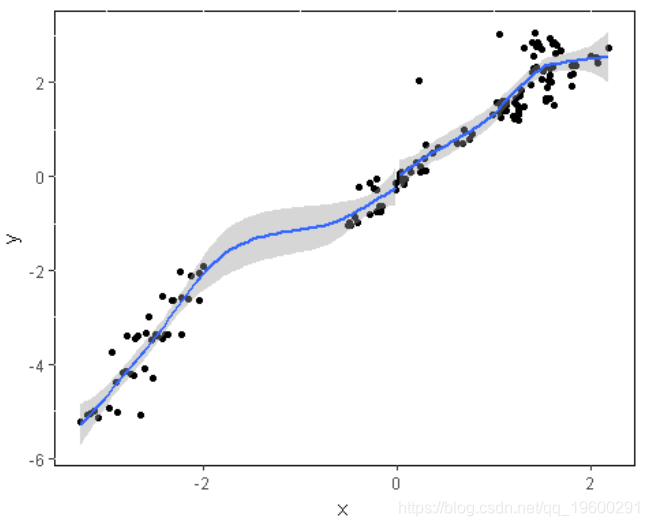
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据

