Twitter是一家美国社交网络及微博客服务的网站,致力于服务公众对话。
迄今为止,Twitter的日活跃用户达1.86亿。与此同时,Twitter也已成为突发紧急情况时人们的重要沟通渠道。由于智能手机无处不在,人们可以随时随地发布他们正在实时观察的紧急情况。
因此,越来越多的救灾组织和新闻机构对通过程序方式监视Twitter产生了兴趣。但是,我们并不清楚一个用户在推特上发布的推文是否是真实的正在发生的灾难。
举个例子,用户发送了“从正面看昨晚的天空,好像在燃烧一样。”作者明确使用了“ABLAZE”一词,但仅仅是为了形容火烧云,并非真正的火焰燃烧。
这对于人类来说是显而易见的,但是对于机器来说便很难分辨该用户是否正在预告真实发生的火灾。
解决方案
任务/目标
建立一个预测推文发布灾难真实性的机器学习模型,该模型可以预测哪些推文发布的是真实发生的灾难,哪些是虚假的灾难,从而为相关组织网络监测灾难发生及救援提供帮助。
数据源准备
数据集中包含的列:
列名 解释
id 每条推文的唯一标识符
text 推特的内容
location 推文发送的位置(可以为空白)
keyword 推文中的特定关键字(可以为空白)
target 仅在train.csv中存在,表示推文中描述灾难的真假,真实为1,虚假为0
其中,测试集包含7613个样本,训练集包含3263个样本。
加载数据并查看
运用pandas分别读取训练集,测试集等。
查看训练集前五行

Yunfan Zhang
本文分析的数据和代码分享至会员群
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
视频
支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
视频
LSTM神经网络架构和原理及其在Python中的预测应用
视频
K近邻KNN算法原理与R语言结合新冠疫情对股票价格预测
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
视频
Boosting集成学习原理与R语言提升回归树BRT预测短鳍鳗分布生态学实例
结果如下:
查看测试集前五行
结果如下:

数据可视化
首先,运用plotly绘制真实虚假灾难数量对比的饼图,该饼图描述了正例反例在训练样本中的占比,检验数据平衡性。
counts_train = train.target.value_counts(sort=False)
labels = counts_train.index
values_train = counts_train.values
#输入饼图数据
data = go.Pie(labels=labels, values=values_train ,pull=[0.03, 0]) 运行结果如下: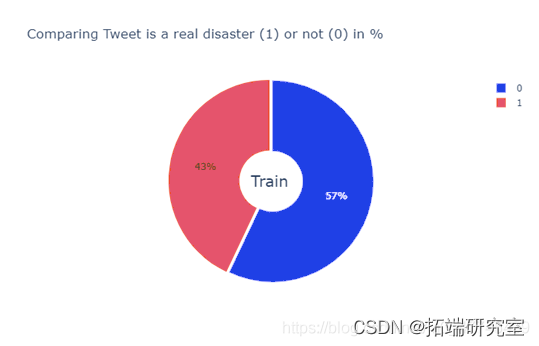
由饼图可知,在训练集中,灾难真实发生的样本(1)共有3271个,占总体的43%,非真实发生的样本(0)有4342个,占总体的57%。总体来说比例较为均衡,可以进行后续建模。
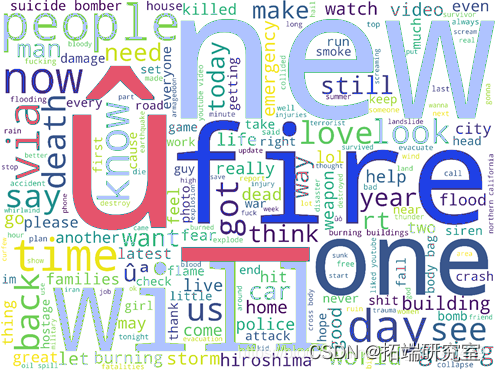
然后,为了进一步了解灾难推文的大致内容,本文利用wordcloud绘制推文的内容的词云。
首先自行将一些网络常用词加入停用词表。
然后定义绘制词云图的函数:
#设置词云格式并生成词云
wordcloud = WordCloud(width = 4000, height = 3000, #宽高
background_color ='white', #背景色
stopwords = stopwords, #停用词结果如下:
数据清洗
众所周知,在进行建模之前,我们必须首先进行数据的预处理,以便于后续进一步处理。因此,本文将进行一些基本的网络文本清理工作,例如去除网址,去除网络标签,删除标点符号,删除常用表情符号,拼写矫正等。
1. 删除网址
2. 删除HTML标签
3. 删除表情符号
首先,搜索推特中常用的表情符号,查询他们的代码点(https://emojipedia.org/relieved-face/),将需要删除的表情符号记录。
5. 拼写矫正

然后,查看text中独立词汇的数量
输出结果:Number of unique words: 14666
2. 嵌入GloVe字典
在这里我们将使用GloVe预训练的语料库模型来表示我们的单词。GloVe模型用于进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息。我们需要输入语料库,然后通过该模型输出词向量。该方法的原理是首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。GloVe语料库共有3种类型:50D,100D和200 D。在这里我们将使用100D。
3. 匹配GloVe向量
输出结果:
100%|██████████| 14666/14666 [00:00<00:00, 599653.57it/s]
(14667, 100)
随时关注您喜欢的主题
建立模型
从2014年起,NLP 的主流方法转移到非线性的神经网络方法,从而输入也从稀疏高维特征向量变为低位稠密特征向量。神经网络不仅像传统机器学习方法一样学习预测,同时也学习如何正确表达数据,即在处理输入输出对时,网络内部产生一系列转化以处理输入数据来预测输出数据。
因此,本次建模以神经网络为基础,设置了Embedding层,Dropout层,LSTM层,以及全连接层。
1. 定义模型函数
导入神经网络相关库后定义模型函数。
#嵌入层
model.add(Embedding(input_dim=num_words,
output_dim=100,
embeddings_initializer=initializers.Constant添加Embedding层以初始化GloVe模型训练出的权重矩阵。input_dim即词汇量,输入数组中的词典大小是14666,即有14666个不同的词,所以我的input_dim便要比14666要大1,output_dim是密集嵌入的尺寸,就如同CNN最后的全连接层一样,上面设置的100,便将每一个词变为用1×100来表示的向量,embeddings_initializer为嵌入矩阵的初始化的方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。输入序列的长度设置为序列长度20,将每个text表示为一个20×100的矩阵
由于文本数据的连续性,我们添加LSTM层。LSTM是作为短期记忆的解决方案而创建的长短期记忆模型,和RNN类似,只是当词向量作为输入进入神经元后,神经元会按照某种方式对该词向量的信息进行选择,存储成新的信息,输入到相邻的隐藏层神经元中去。

想了解更多关于模型定制、咨询辅导的信息?
输出结果:
2. 参数选择与调优
本文运用交叉验证的方法得到验证集精度,并以此为标准,使用网格搜索来确定最优超参数。
Scikit-Learn里有一个API 为model.selection.GridSearchCV,可以将keras搭建的模型传入,作为sklearn工作流程一部分。因此,我们运用此函数来包装keras模型以便在scikit-learn中使用keras。
3. 模型训练
输出结果:

输出结果:
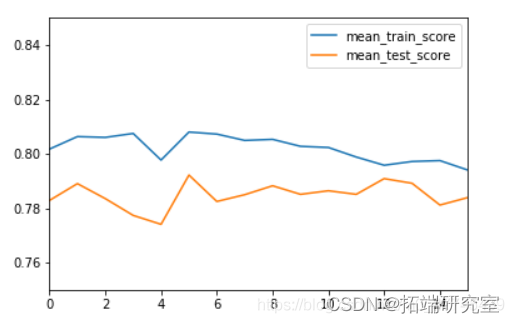
由训练过程可知,验证集准确率最高的参数组合为第五次训练时的参数,batch_size=10 ,epochs=10。
4. 模型评估
查看最终参数选择的结果和交叉验证的结果:
输出结果:
交叉验证平均准确率: 0.7921975544580065
最好的参数模型: {‘batch_size’: 10, ‘nb_epoch’: 10}
5. 与传统机器学习模型对比
将train中训练集数据划分为训练集和验证集,然后对比其在验证集上的准确率。
分别使用SVM,KNN,多层感知器,朴素贝叶斯,随机森林,GBDT等方法构建模型,与神经网络进行对比。
输出结果:
模型1验证集准确率: 0.6250820748522653
模型2验证集准确率: 0.5843729481286933
模型3验证集准确率: 0.5384110308601444
模型4验证集准确率: 0.4799737360472751
模型5验证集准确率: 0.6323046618516087
模型6验证集准确率: 0.6401838476690742
以上模型的验证集准确率与神经网络的验证集准确率相比差别较大,可见本文基于神经网络的文本预测模型是相对准确且可靠的。
结果预测
我们继续通过上述步骤构建的神经网络模型预测test测试集中的target列。
#预测
predictions = grid_result.predict(testing_padded)
submission['target'] = (predictions > 0.5).astype(int)输出结果:
项目结果
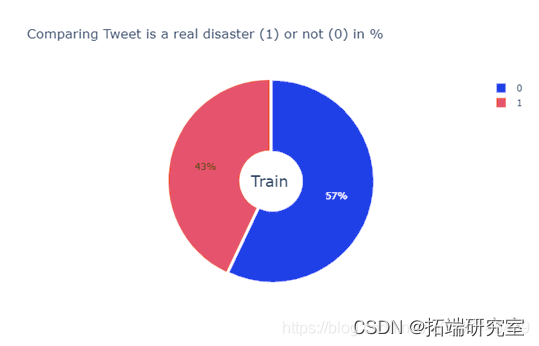
真实虚假样本比例接近1:1.
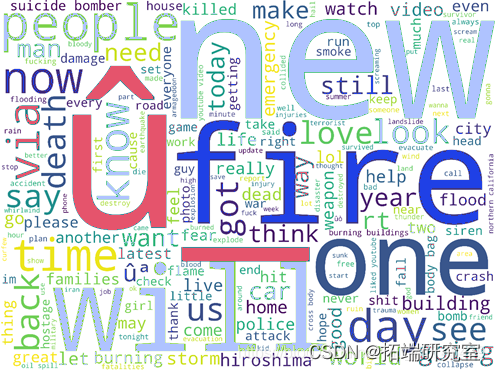
灾难相关推文中提到最多的词汇是fire。
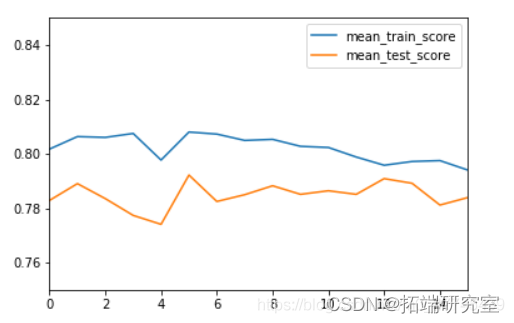
最好的参数组合是batch_size=10 ,epochs=10。

将测试集输入模型得到最终预测结果。
关于作者
Yunfan Zhang
在此对Yunfan Zhang 对本文所作的贡献表示诚挚感谢,她专长机器学习,概率论与数理统计。
 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据
Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据

