通过训练具有小型中心层的多层神经网络重构高维输入向量,可以将高维数据转换为低维代码。
最近我们被客户要求撰写关于神经网络的研究报告。这种神经网络被命名为自编码器_Autoencoder_。
自编码器是_非线性_降_维_ 技术用于特征的无监督学习,它们可以学习比主成分分析效果更好的低维代码,作为降低数据维数的工具。
自编码器是一种能够通过无监督学习,学到输入数据高效表示的人工神经网络。输入数据的这一高效表示称为编码(codings),其维度一般远小于输入数据,使得自编码器可用于降维。更重要的是,自编码器可作为强大的特征检测器(feature detectors),应用于深度神经网络的预训练。此外,自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型(generative model)。比如,可以用人脸图片训练一个自编码器,它可以生成新的图片。
自编码器通过简单地学习将输入复制到输出来工作。这一任务(就是输入训练数据, 再输出训练数据的任务)听起来似乎微不足道,但通过不同方式对神经网络增加约束,可以使这一任务变得极其困难。比如,可以限制内部表示的尺寸(这就实现降维了),或者对训练数据增加噪声并训练自编码器使其能恢复原有。这些限制条件防止自编码器机械地将输入复制到输出,并强制它学习数据的高效表示。简而言之,编码(就是输入数据的高效表示)是自编码器在一些限制条件下学习恒等函数(identity function)的副产品。
异常心跳检测
如果提供了足够的类似于某种底层模式的训练数据,我们可以训练网络来学习数据中的模式。
异常测试点是与典型数据模式不匹配的点。自编码器在重建这些数据时可能会有很高的错误率,这表明存在异常。
该框架用于使用深度自编码器开发异常检测演示。该数据集是心跳的 ECG 时间序列,目标是确定哪些心跳是异常值。训练数据(20 个“好”心跳)和测试数据(为简单起见附加了 3 个“坏”心跳的训练数据),如下所示。每行代表一个心跳。
init()
PATH = os.path.expanduser("~/")
import_file(PATH + "train.csv") import_file(PATH + "test.csv")

探索数据集
tra.shape
# 将框架转置,将时间序列作为一个单独的列来绘制。 plot(legend=False); # 不显示图例
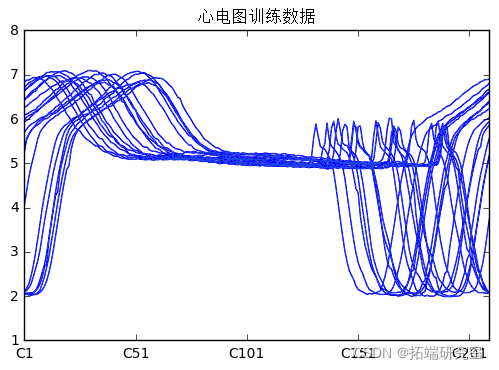
在训练数据中,我们有 20 个时间序列,每个序列有 210 个数据点。请注意,所有线条都很紧凑并且形状相似。重要的是要记住,在使用自编码器进行训练时,您只想使用 VALID 数据。应删除所有异常。
现在让我们训练我们的神经网络
Estimator( activation="Tanh", hidden=\[50\], ) model.train

model

随时关注您喜欢的主题
我们的神经网络现在能够对 时间序列进行 _编码_。
异常检测
现在我们尝试使用异常检测功能计算重建误差。这是输出层和输入层之间的均方误差。低误差意味着神经网络能够很好地对输入进行编码,这意味着是“已知”情况。高误差意味着神经网络以前没有见过该示例,因此是异常情况。
anomaly(test )
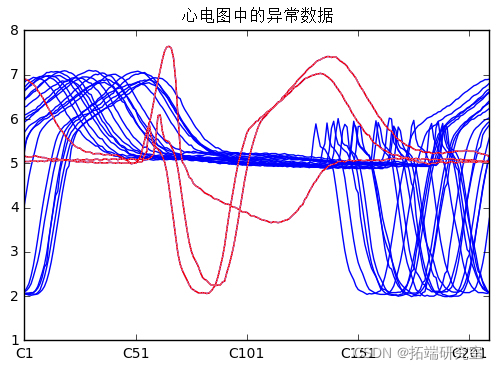
现在的问题是:哪个 test 时间序列最有可能是异常?
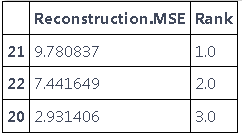
我们可以选择错误率最高的前 N 个
df\['Rank'\] = df\['MSE'\].rank
sorted
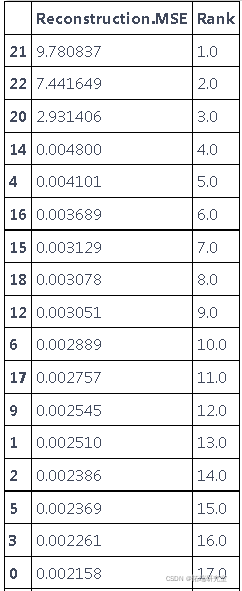
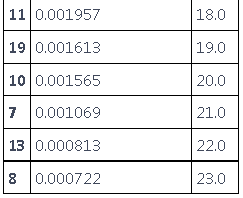
dfsorted\[MSE'\] > 1.0
datT.plot

daT\[anindex\].plot(color='red');
带监督微调的无监督预训练
有时,未标记的数据比标记的数据多得多。
在这种情况下,在未标记数据上训练自编码器模型,然后使用可用标签微调学习模型是有意义的。
结论
在本教程中,您学习了如何使用自编码器快速检测时间序列异常。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

