在本文中,我们描述了灵活的竞争风险回归模型。回归模型被指定为转移概率,也就是竞争性风险设置中的累积发生率。
该模型包含Fine和Gray(1999)的模型作为一个特例。这可以用来对次分布危险的比例假设做拟合度测试(Scheike和Zhang 2008)。
还可以为预测的累积发病率曲线构建置信区间。我们将这些方法应用于Pintilie(2007)的滤泡细胞淋巴瘤数据,其中竞争风险是疾病复发和没有复发的死亡。
在观察某一事件是否发生时,如果该事件受到其他事件的阻碍,在这种所谓的竞争风险研究中可能会有多个结果事件,有些结果会阻止感兴趣的事件发生或影响其发生的概率。所有形成竞争关系的结果事件,互为竞争的风险事件。
例如,有研究人员收集了本市2007年诊断为轻度认知障碍(MCI)的518例老年患者的临床资料,包括基本人口学特征、生活方式、体检、疾病信息等,并在2010-2013年完成6次随访调查,主要结果事件是这些老年患者会不会发生阿尔茨海默病(AD)。随访期内共发生AD 78例,这其中包括迁移28例,失访31例,死亡25例。影响MCI向AD过渡的因素有哪些?
在这种情况下,如果MCI患者在没有发生AD的观察期内死于癌症、心血管疾病、车祸等原因,则不能观察到AD的发病,也就是死亡终点与AD的发生产生了“竞争”。根据传统生存分析方法,个体死亡发生在AD之前,结局是死亡,而不是AD,被认为是删失数据,可能会导致偏差。对于死亡率较高的老年人群,当存在竞争风险事件时,传统生存分析方法(Kaplan-Meier方法、logrank检验、Cox比例风险回归模型)会高估感兴趣疾病的风险,从而导致竞争风险偏差。一些研究发现,大约46%的文献可能存在这样的偏差。
在这种情况下,竞争风险模型是适用的。所谓竞争风险模型是对生存数据的多个潜在结果进行处理的一种分析方法。早在1999年,Fine和Gray就提出了部分分布的半参数比例风险模型,常用的终点指标是累积发生率函数(CIF)。在这种情况下,AD前死亡可视为AD的竞争风险事件,并采用竞争风险模型进行统计分析。竞争风险的单变量分析通常被用来估计感兴趣的终点事件的发生率,多变量分析经常被用来探索预后因素和影响大小。
工作实例:滤泡细胞淋巴瘤研究
我们考虑Pintilie(2007)的滤泡细胞淋巴瘤数据。该数据集由541名疾病早期的滤泡细胞淋巴瘤(I或II)患者组成,并接受单纯放疗(化疗=0)或放疗和化疗的联合治疗(化疗=1)。
疾病复发或无反应和缓解期死亡是两个竞争风险。患者的年龄(年龄:平均=57,sd=14)和血红蛋白水平(hgb:平均=138,sd=15)也被记录。随访时间的中位数是5.5年。首先我们读取数据,计算死亡原因指标并对协变量进行编码。
R> table(cause)
cause
0 1 2
193 272 76
R> stage <- as.numeric(clinstg == 2)
R> chemo <- as.numeric(ch == "Y")
R> times1 <- sort(unique(time\[cause == 1\]))有272个(无治疗反应或复发)因疾病引起的事件,76个竞争性风险事件(无复发的死亡)和193个删减的个体。事件时间用dftime表示。变量times1给出了原因为 “1 “的事件时间。我们首先估计非参数累积发病率曲线进行比较。
我们指定事件时间并删减变量为cause == 0。回归模型只包含一个截距项(+1)。cause变量给出了与不同事件相关的原因。cause= 1指定我们考虑类型1的事件。计算/基于估计值的时间可以由参数times = times1给出。
图1(a)显示了估计的两种原因的累积发生率曲线。在图1(b)中,我们构建95%的置信区间(虚线)和95%的置信带。
risk(Surv(dftime, cause == 0) ~ + 1,
causeS = 1, n.sim = 5000, cens.code = 0, model = "additive")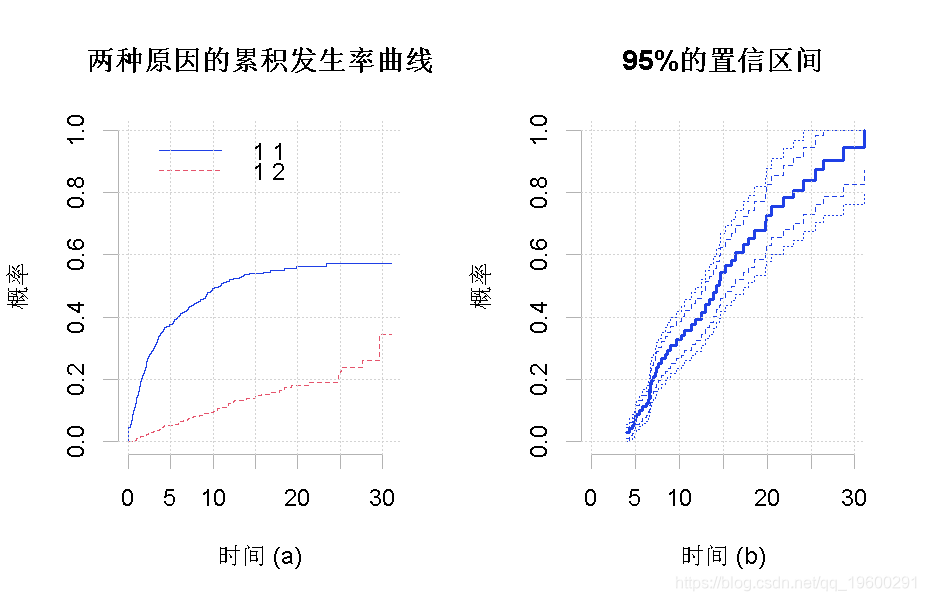
图1
R> fit <- cum(time, cause, group)
R> plot(fit)子分布危险法和直接二项式模型法都是基于反概率的删减加权技术。在应用这种权重时,关键是删减权重的估计不能有偏差,否则累积发病率曲线的估计也可能有偏差。

在这个例子中,我们发现删减分布明显取决于协变量血红蛋白、阶段和化疗,并可以由Cox的回归模型很好地描述。Cox模型的拟合是通过累积残差来验证的,进一步的细节见Martinussen和Scheike(2006)。因此,对剔除权重使用简单的KaplanMeier估计可能会导致严重的偏差估计。因此,我们在调用中加入了cens.model = “cox “的选项,这就使用了Cox模型中竞争风险模型的所有协变量作为剔除权数。一般来说,反概率删减权重的回归模型可以用来提高效率(Scheike等人,2008)。
现在我们来拟合模型
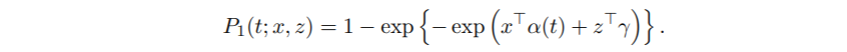
我们首先拟合一个一般比例模型,允许所有协变量具有时变效应。在下面的调用中,只有模型(6)中的协变量x被定义。模型(6)中的协变量z是由一个const操作符指定的。
summary(outf)
OUTPUT:
Competing risks Model
Test for nonparametric terms
Test for non-significant effects
Supremum-test of significance p-value H_0: B(t)=0
(Intercept) 3.29 0.0150
stage 5.08 0.0000
age 4.12 0.0002
chemo 2.79 0.0558
hgb 1.16 0.8890
Test for time invariant effects
Kolmogorov-Smirnov test p-value H_0:constant effect
(Intercept) 8.6200 0.0100
stage 1.0400 0.0682
age 0.0900 0.0068
chemo 1.7200 0.0004
hgb 0.0127 0.5040
Cramer von Mises test p-value H_0:constant effect
(Intercept) 3.69e+01 0.0170
stage 2.52e+00 0.0010
age 4.26e-03 0.0014
chemo 1.50e+00 0.0900
hgb 2.64e-04 0.4220随时关注您喜欢的主题
基于非参数检验的显著性检验显示,在非参数模型中,阶段和年龄是显著的,化疗是较显著的(p = 0.056),血红蛋白是不显著的(p = 0.889)。
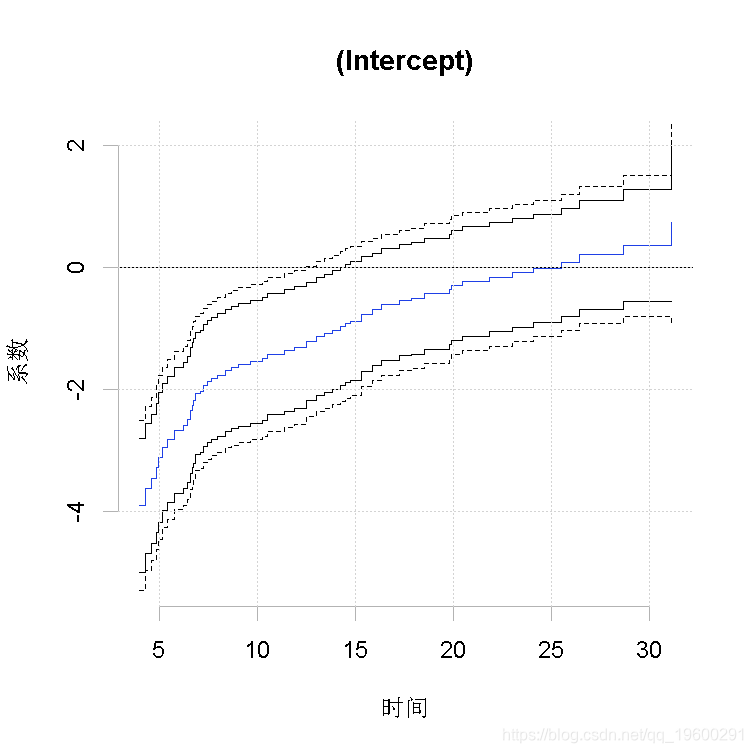
图2
绘制估计的回归系数αj (t)及其95%的置信带,并分别绘制常数效应的观察检验过程和空值下的模拟检验过程。
R> plot(outf, score = 1)图2显示了这些效应并不随时间变化而变化,在早期的时间段内效应相当明显。95%的指向性置信区间,以及95%的置信区间。
图3显示了相关的检验过程,用于决定时变效应是否具有显著的时变性,或者是否可以接受H0 : αj (t) = βj。这些图的摘要在输出中给出,我们看到阶段和化疗显然是时变的,因此与Fine-Gray模型不一致。Kolmogorov-Smirnov和Cramer von Mises检验统计数字对检验过程的两种不同总结是一致的,总的结论是三个变量都没有比例的Cox类型效应。
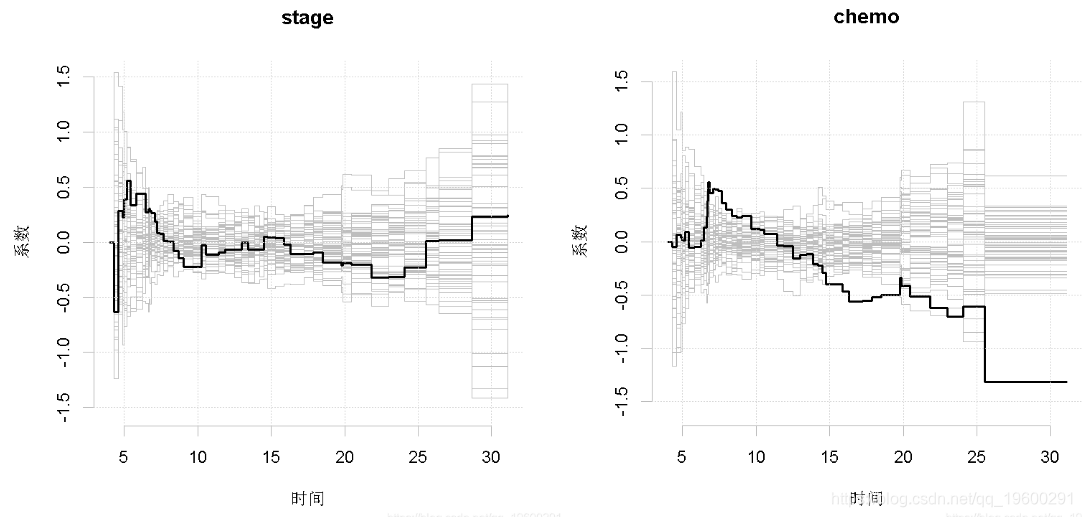
图3
我们看到血红蛋白被常数很好地描述,因此我们考虑用血红蛋白具有常数效应,其余协变量具有时变效应的模型。
R> summary(outf1)
OUTPUT:
Competing risks Model
Test for nonparametric terms
Test for non-significant effects
Supremum-test of significance p-value H_0: B(t)=0
(Intercept) 5.46 0
stage 5.18 0 age 4.20 0
chemo 3.89 0
Test for time invariant effects
Kolmogorov-Smirnov test p-value H_0:constant effect
(Intercept) 10.100 0.000
stage 1.190 0.048
age 0.101 0.004
chemo 1.860 0.000
Cramer von Mises test p-value H_0:constant effect
(Intercept) 79.90000 0.000
stage 1.84000 0.006
age 0.00583 0.000
chemo 2.53000 0.000
Parametric terms :
Coef. SE Robust SE z P-val
const(hgb) 0.00195 0.00401 0.00401 0.486 0.627Competing risks Model
Test for nonparametric terms
Test for non-significant effects
Supremum-test of significance p-value H_0: B(t)=0
(Intercept) 6.32 0
Test for time invariant effects
Kolmogorov-Smirnov test p-value H_0:constant effect
(Intercept) 1.93 0
Cramer von Mises test p-value H_0:constant effect
(Intercept) 14.3 0
Parametric terms :
Coef. SE Robust SE z P-val
const(stage) 0.45200 0.13500 0.13500 3.340 0.000838
const(age) 0.01450 0.00459 0.00459 3.150 0.001610
const(chemo) -0.37600 0.18800 0.18800 -2.000 0.045800
const(hgb) 0.00249 0.00401 0.00401 0.622 0.534000我们注意到,血红蛋白的影响与更合适模型(如上图所示)的影响几乎相等。但由于模型中其他协变量的不适合,估计值可能有严重的偏差,因此可能误导了数据的重要特征。
我们注意到,血红蛋白的影响与更合适模型(如上图所示)的影响几乎相等。但由于模型中其他协变量的不适合,估计值可能有严重的偏差,因此可能误导了数据的重要特征。
R> summary(outf1)
OUTPUT:
Competing risks Model
Test for nonparametric terms
Test for non-significant effects
Supremum-test of significance p-value H_0: B(t)=0
(Intercept) 5.46 0
stage 5.18 0 age 4.20 0
chemo 3.89 0
Test for time invariant effects
Kolmogorov-Smirnov test p-value H_0:constant effect
(Intercept) 10.100 0.000
stage 1.190 0.048
age 0.101 0.004
chemo 1.860 0.000
Cramer von Mises test p-value H_0:constant effect
(Intercept) 79.90000 0.000
stage 1.84000 0.006
age 0.00583 0.000
chemo 2.53000 0.000
Parametric terms :
Coef. SE Robust SE z P-val
const(hgb) 0.00195 0.00401 0.00401 0.486 0.627Competing risks Model
Test for nonparametric terms
Test for non-significant effects
Supremum-test of significance p-value H_0: B(t)=0
(Intercept) 6.32 0
Test for time invariant effects
Kolmogorov-Smirnov test p-value H_0:constant effect
(Intercept) 1.93 0
Cramer von Mises test p-value H_0:constant effect
(Intercept) 14.3 0
Parametric terms :
Coef. SE Robust SE z P-val
const(stage) 0.45200 0.13500 0.13500 3.340 0.000838
const(age) 0.01450 0.00459 0.00459 3.150 0.001610
const(chemo) -0.37600 0.18800 0.18800 -2.000 0.045800
const(hgb) 0.00249 0.00401 0.00401 0.622 0.534000最后,我们将FG模型的预测与半参数模型的预测进行比较,后者对效应的描述更为详细。我们考虑对下面由新数据分配定义的两种不同的病人进行预测。患者类型I:疾病I期(阶段=0),40岁,没有化疗治疗(化疗=0),患者类型II:疾病II期(阶段=1),60岁,放疗加化疗联合治疗(化疗=1)。
R> newdata <- data.frame(stage = c(0, 1), age = c(40, 60), chemo = c(0, 1),
+ hgb = c(138, 138))
R> predict(out, newdata)为了指定计算预测的数据,我们可以指定一个newdata参数。
基于该模型的预测可能不是单调的。我们绘制了没有点状置信区间(se = 0)和没有置信带(uniform = 0)的预测。图4(a)中的预测是基于灵活的模型,而图4(b)中的预测是基于FG模型的。I型和II型病人的复发累积发生率曲线分别用实线和虚线表示。图5(a)比较了基于灵活模型和FG模型对I型患者的预测结果。同样地,图5(b)比较了对II型病人的预测。两个预测值周围的断线代表了基于灵活模型的置信区。
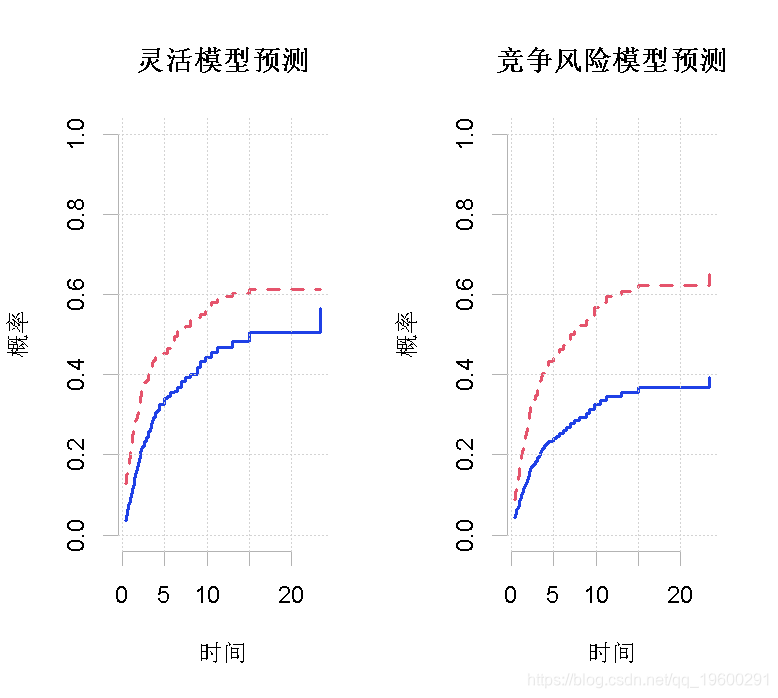
图4
R> par(mfrow = c(1, 2))
R> plot(f1, se = 0, uniform = 1, col = 1, lty = 1
R> plot(fg, new = 0, se = 0, uniform = 0, col = 2, lty = 2,较高的疾病阶段、较高的年龄和联合治疗会导致较高的累积发病率,其影响在时间段的早期更为明显(图4(a)和图2)。另一方面,化疗在时间段的最初增加了累积发病率,随后降低了发病率(图4(a)和图2)。图5显示,FG模型不能准确地模拟时变效应。尽管有这些差异,在这种情况下,总体预测有些类似,特别是当考虑到估计的不确定性。然而,协变量的时变行为显然是重要的。
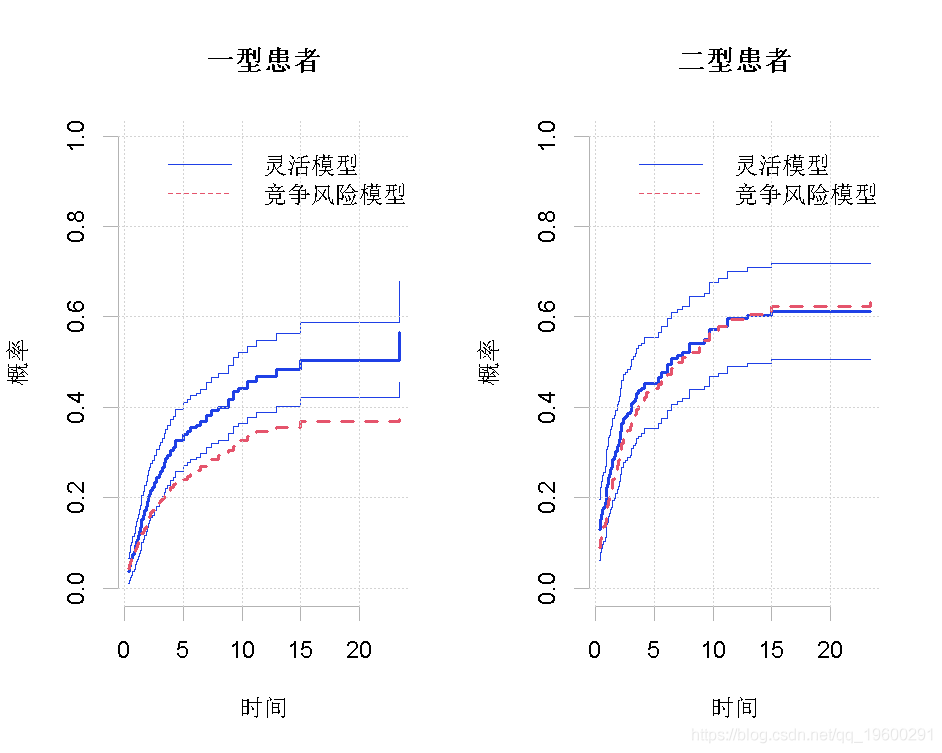
图5
讨论
本文实现了累积发病率曲线的灵活竞争风险回归模型,可以详细分析协变量效应如何预测累积发病率,并允许协变量的时间变化效应。可以检查较简单的模型的拟合度,同时可以产生带有置信区间和置信带的预测结果,这对研究人员很有用。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 多状态马尔可夫链、生存分析心脏同种异体移植血管病变(CAV)数据可视化|附数据代码
多状态马尔可夫链、生存分析心脏同种异体移植血管病变(CAV)数据可视化|附数据代码 R语言生存分析模型因果分析:非参数估计、IP加权风险模型、结构嵌套加速失效(AFT)模型分析流行病学随访研究数据
R语言生存分析模型因果分析:非参数估计、IP加权风险模型、结构嵌套加速失效(AFT)模型分析流行病学随访研究数据 R语言使用限制平均生存时间RMST比较两条生存曲线分析肝硬化患者
R语言使用限制平均生存时间RMST比较两条生存曲线分析肝硬化患者 R语言样条曲线、泊松回归模型估计女性直肠癌患者标准化发病率(SIR)、标准化死亡率(SMR)
R语言样条曲线、泊松回归模型估计女性直肠癌患者标准化发病率(SIR)、标准化死亡率(SMR)



