本文从实践角度讨论了季节性单位根。
我们考虑一些时间序列 Xt,例如道路上的交通流量,
可下载资源
> plot(T,X,type="l")
> reg=lm(X~T)
> abline(reg,col="red")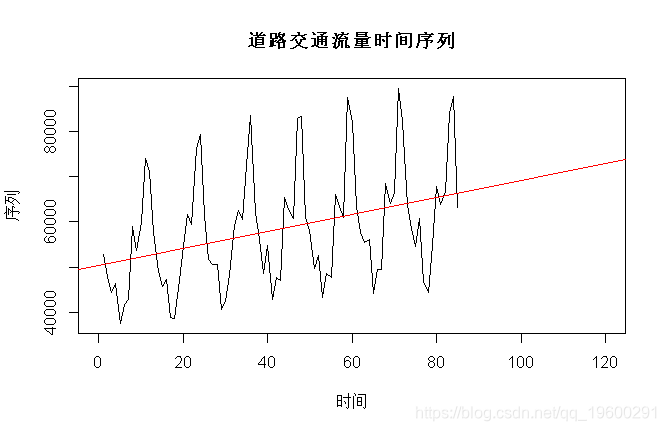
如果存在趋势,我们应该将其删除,然后处理残差
> Y=residuals(reg)
> acf(Y,lag=36,lwd=3)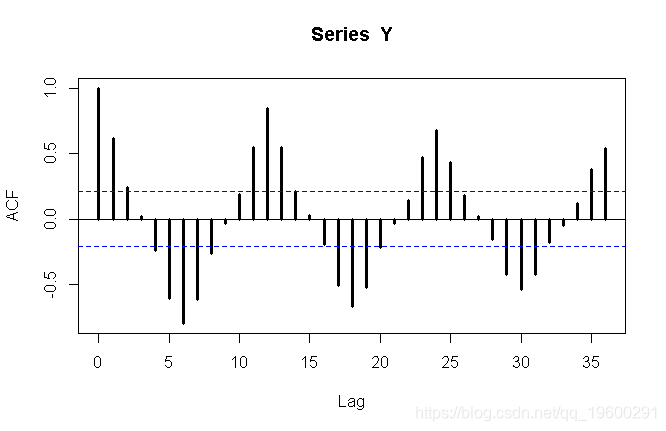
我们可以看到这里有一些季节性。第一个策略可能是假设存在季节性单位根,因此我们考虑 Y_t)
,我们尝试找到ARMA模型。考虑时间序列的自相关函数,
> Z=diff(Y,12)
> acf(Z,lag=36,lwd=3)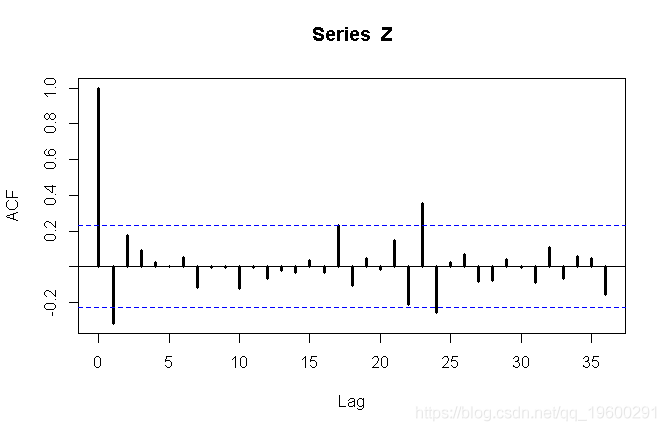
或偏自相关函数
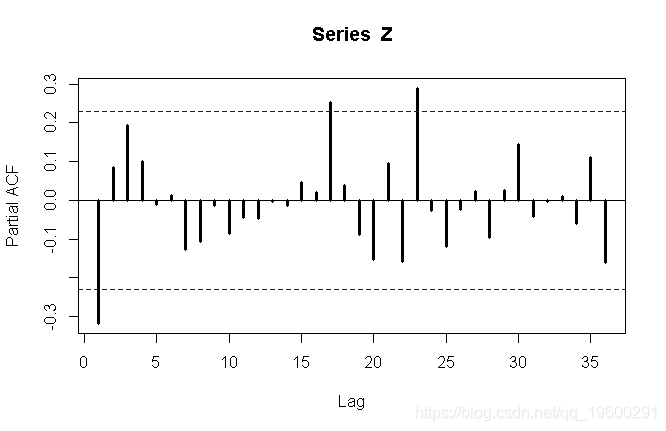
第一个图可能建议MA(1),而第二个图可能建议AR(1)时间序列。我们都尝试。
arima
Coefficients:
ma1 intercept
-0.2367 -583.7761
s.e. 0.0916 254.8805
sigma^2 estimated as 8071255: log likelihood = -684.1, aic = 1374.2 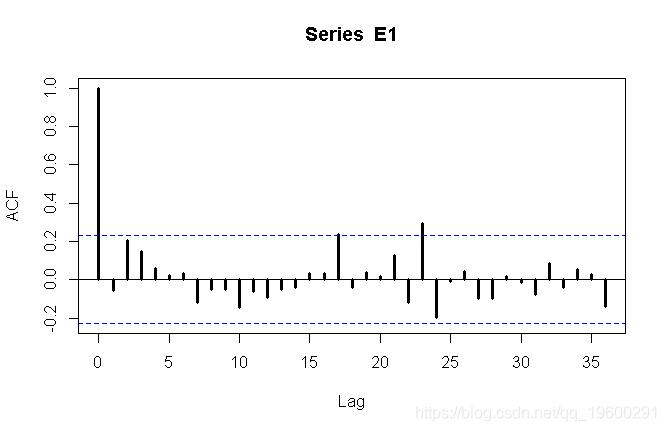
可以认为是白噪声(如果您不确定,请尝试 Box-Pierce或Ljung-Box 测试)。
arima
Coefficients:
ar1 intercept
-0.3214 -583.0943
s.e. 0.1112 248.8735
sigma^2 estimated as 7842043: log likelihood = -683.07, aic = 1372.15 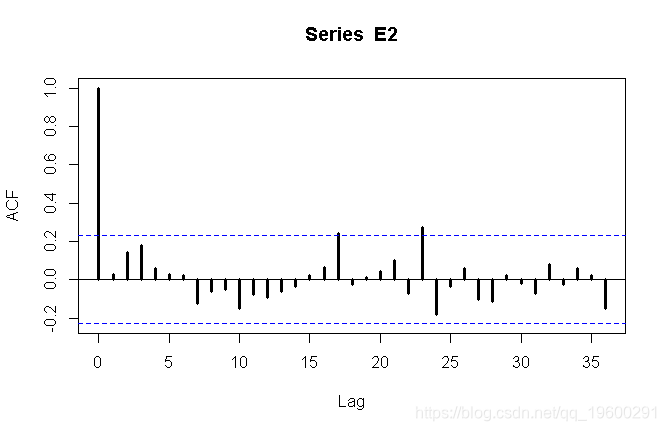
也可以视为白噪声。到目前为止,我们有
![]()
对于一些白噪声 )
。这表明以下的SARIMA结构
)
,
arima
Coefficients:
ar1
-0.2715
s.e. 0.1130
sigma^2 estimated as 8412999: log likelihood = -685.62, aic = 1375.25随时关注您喜欢的主题
现在,如果我们认为我们没有季节性单位根,而在AR结构中只是一个大的自回归系数。让我们尝试类似
![]()
自然而然的猜测是该系数应该(可能)接近于1。让我们尝试一下
arima
Coefficients:
ar1 sar1 intercept
-0.1629 0.9741 -684.9455
s.e. 0.1170 0.0115 3064.4040
sigma^2 estimated as 8406080: log likelihood = -816.11, aic = 1640.21这与我们先前(以某种方式)获得的结果具有可比性,因此我们可以假设该模型是一个有趣的模型。我们将进一步讨论:第一个系数可能是不重要的。
这两个模型有什么区别?
从(非常)长期的角度来看,模型是完全不同的:一个模型是平稳的,因此预测将趋向于平均值,而另一个模型则是按季节的,因此置信区间将增加。
我们得到
> pre(model2,600,b=60000)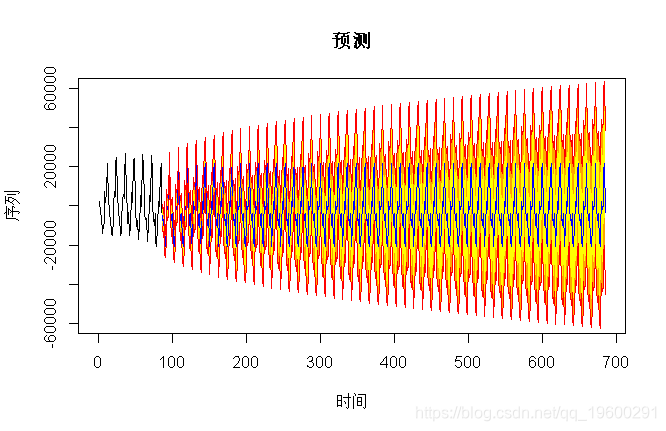
对于平稳的
> prev(model3,600,b=60000)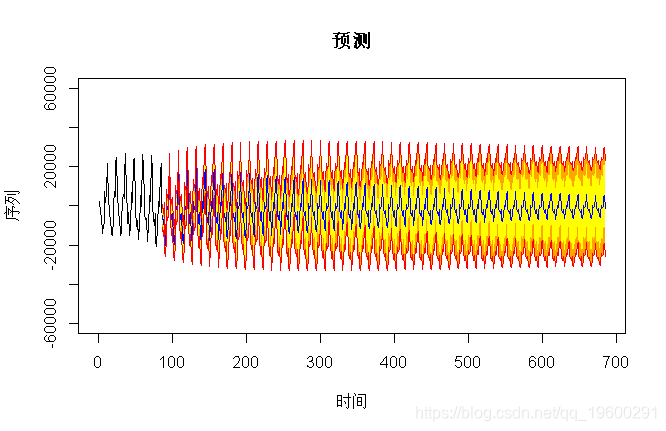
但是,使用这些模型进行的预测仅适用于短期范围。在这种情况下,这里的预测几乎相同,
> pre(model2,36,b=60000)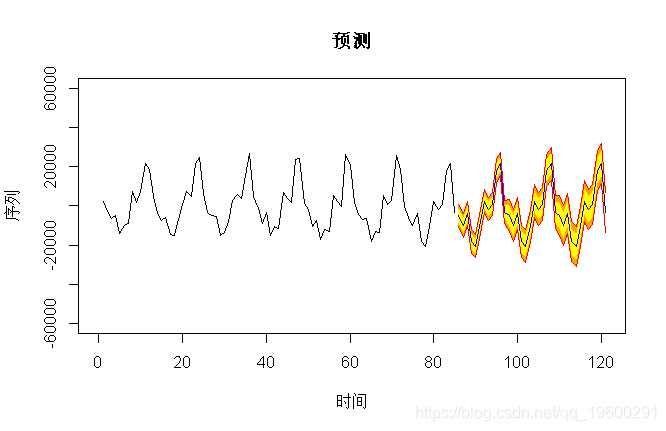
> pre(model3,36,b=60000)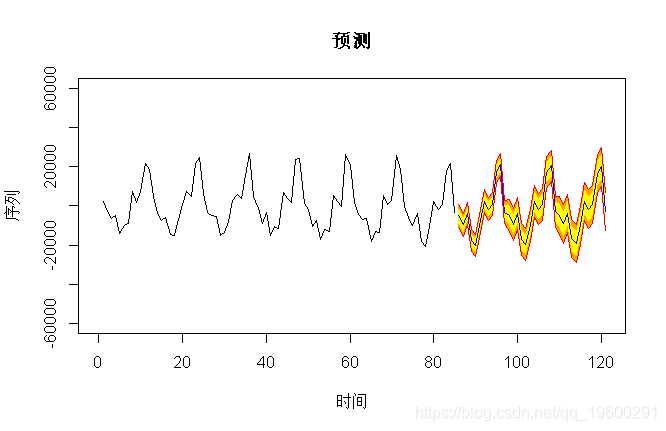
现在,如果我们回到第二个模型,自回归系数可能被认为是不重要的。如果我们将其删除怎么样?
Call:
seasonal = list(order = c(1, 0, 0)
Coefficients:
sar1 intercept
0.9662 -696.5661
s.e. 0.0134 3182.3017
sigma^2 estimated as 8918630: log likelihood = -817.03, aic = 1640.07如果我们看一下(短期)预测,我们得到
> pre(model,36,b=32000)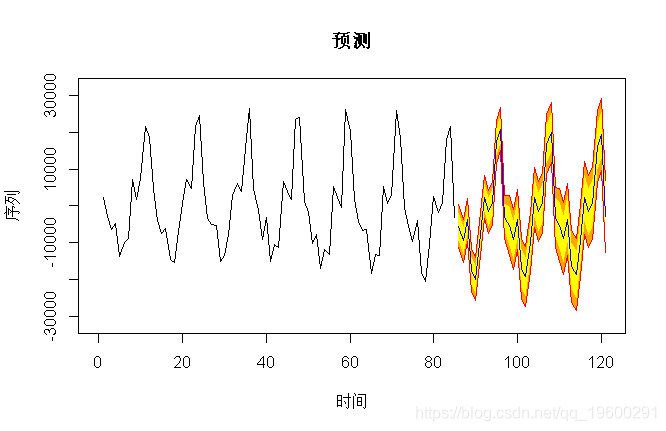
有什么区别吗?如果我们看一下预测结果数字,我们会得到

数字不同,但差异不大(请注意置信区间的大小)。这可以解释为什么在R中,当我们在自回归过程时 ,得到一个模型要估计的参数,即使其中不重要,我们通常也会保留它们来预测。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python梯度提升树GBT、随机森林、决策树对链家多城市二手房价格数据预测与区域差异可视化分析——基于数据爬取与特征工程优化|附代码数据
Python梯度提升树GBT、随机森林、决策树对链家多城市二手房价格数据预测与区域差异可视化分析——基于数据爬取与特征工程优化|附代码数据 Python基于ARIMA-LSTM模型的广州市新能源汽车销量预测
Python基于ARIMA-LSTM模型的广州市新能源汽车销量预测



