本示例说明如何使用长短期记忆(LSTM)网络对序列数据进行分类。
要训练深度神经网络对序列数据进行分类,可以使用LSTM网络。LSTM网络使您可以将序列数据输入网络,并根据序列数据的各个时间步进行预测。
本示例使用日语元音数据集。“日语元音数据集” 是一个特定的数据集。它用于与日语元音相关的研究或应用中,其中包含了关于日语元音的时间序列数据等信息,比如有九位发言人的时间序列数据,每个序列具有 12 个特征且长度不同,还包括 270 个训练观察和 370 个测试观察。此示例训练LSTM网络来识别给定时间序列数据的说话者,该时间序列数据表示连续讲话的两个日语元音。训练数据包含九位发言人的时间序列数据。每个序列具有12个特征,并且长度不同。数据集包含270个训练观察和370个测试观察。
LSTM 网络即长短期记忆网络(Long Short-Term Memory),是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟非常长的重要事件。它能够在较长的序列中有效地保留和传递信息,克服了传统循环神经网络在处理长序列时可能出现的梯度消失和梯度爆炸问题。LSTM 网络由多个重复的模块组成,每个模块包含遗忘门、输入门和输出门等结构,通过这些门控机制来控制信息的流动和更新,从而实现对序列数据的高效学习和处理。例如在自然语言处理任务中,LSTM 网络可以用于文本生成、机器翻译、情感分析等;在时间序列预测任务中,可用于股票价格预测、气象预测等。

加载序列数据
加载日语元音训练数据。 XTrain 是包含长度可变的维度12的270个序列的单元阵列。 Y 是标签“ 1”,“ 2”,…,“ 9”的分类向量,分别对应于九个扬声器。中的条目 XTrain 是具有12行(每个要素一行)和不同列数(每个时间步长一列)的矩阵。
自提出后,传统神经网络架构一直没法解决一些基础问题,比如解释依赖于信息和上下文的输入序列。这些信息可以是句子中的某些单词,我们能用它们预测下一个单词是什么;也可以是序列的时间信息,我们能基于时间元素分析句子的上下文。
简而言之,传统神经网络每次只会采用独立的数据向量,它没有一个类似“记忆”的概念,用来处理和“记忆”有关各种任务。
为了解决这个问题,早期提出的一种方法是在网络中添加循环,得到输出值后,它的输入信息会通过循环被“继承”到输出中,这是它最后看到的输入上下文。这些网络被称为递归神经网络(RNN)。虽然RNN在一定程度上解决了上述问题,但它们还是存在相当大的缺陷,比如在处理长期依赖性问题时容易出现梯度消失。
这里我们不深入探讨RNN的缺陷,我们只需知道,既然RNN这么容易梯度消失,那么它就不适合大多数现实问题。在这个基础上,Hochreiter&Schmidhuber于1997年提出了长期短期记忆网络(LSTM),这是一种特殊的RNN,它能使神经元在其管道中保持上下文记忆,同时又解决了梯度消失问题。
XTrain(1:5)
ans=5×1 cell array
{12x20 double}
{12x26 double}
{12x22 double}
{12x20 double}
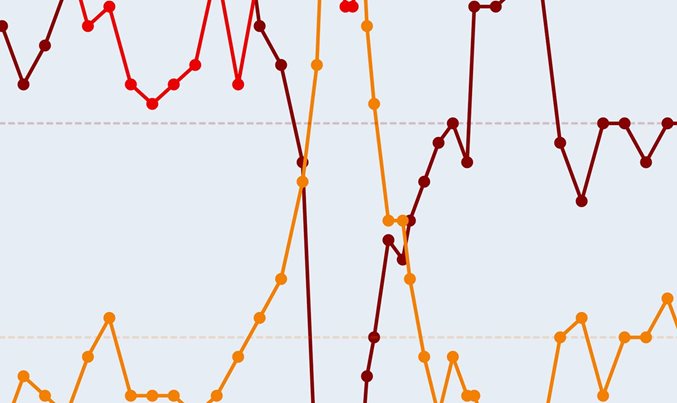
{12x21 double}可视化图中的第一个时间序列。每行对应一个特征。
figure
plot(Train')
xlabel("时间步长")
title("训练样本 1")
numFeatures = size(XTrain{1},1);
legend("特征 "准备填充数据
在训练过程中,默认情况下,该软件默认将训练数据分成小批并填充序列,以使它们具有相同的长度。太多的填充可能会对网络性能产生负面影响。
为防止训练过程增加太多填充,您可以按序列长度对训练数据进行排序,并选择小批量的大小,以使小批量中的序列具有相似的长度。下图显示了对数据进行排序之前和之后的填充序列的效果。
获取每个观察的序列长度。
按序列长度对数据进行排序。
在条形图中查看排序的序列长度。
figure
bar(sequenceLengths)
ylim([0 30])
xlabel("序列")
ylabel("长度")
title("排序后数据")选择大小为27的小批量可均匀划分训练数据并减少小批量中的数量。下图说明了添加到序列中的填充量。
定义LSTM网络架构
定义LSTM网络体系结构。将输入大小指定为大小为12的序列(输入数据的大小)。指定具有100个隐藏单元的双向LSTM层,并输出序列的最后一个元素。最后,通过包括大小为9的完全连接层,其后是softmax层和分类层,来指定九个类。
如果可以在预测时使用完整序列,则可以在网络中使用双向LSTM层。双向LSTM层在每个时间步都从完整序列中学习。例如,如果您无法在预测时使用整个序列,比如一次预测一个时间步长时,请改用LSTM层。
随时关注您喜欢的主题
layers =
5x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' BiLSTM BiLSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmax
5 '' Classification Output crossentropyex现在,指定训练选项。将优化器指定为 'adam',将梯度阈值指定为1,将最大历元数指定为100。要减少小批量中的填充量,请选择27的小批量大小。与最长序列的长度相同,请将序列长度指定为 'longest'。为确保数据仍按序列长度排序,请指定从不对数据进行随机排序。
由于批处理的序列短,因此训练更适合于CPU。指定 'ExecutionEnvironment' 为 'cpu'。要在GPU上进行训练(如果有),请将设置 'ExecutionEnvironment' 为 'auto' (这是默认值)。
训练LSTM网络
使用指定的训练选项来训练LSTM网络 trainNetwork。
测试LSTM网络
加载测试集并将序列分类为扬声器。
加载日语元音测试数据。 XTest 是包含370个长度可变的维度12的序列的单元阵列。 YTest 是标签“ 1”,“ 2”,…“ 9”的分类向量,分别对应于九个扬声器。
XTest(1:3)
ans=3×1 cell array
{12x19 double}
{12x17 double}
{12x19 double}LSTM网络 net 是使用相似长度的序列进行训练的。确保测试数据的组织方式相同。按序列长度对测试数据进行排序。
分类测试数据。要减少分类过程引入的数据量,请将批量大小设置为27。要应用与训练数据相同的填充,请将序列长度指定为 'longest'。
计算预测的分类准确性。
acc = sum(YPred == YTest)./numel(YTest)
acc = 0.9730参考文献
UCI机器学习存储库:日语元音数据集。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码
Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码 Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据
Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据 Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据
Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据 DeepSeek与LangGraph共享单车需求数据预测:LSTM与XGBoost多模型融合方法及Streamlit可视化应用 | 附代码数据
DeepSeek与LangGraph共享单车需求数据预测:LSTM与XGBoost多模型融合方法及Streamlit可视化应用 | 附代码数据