统计学中传统的数据类型有截面数据和时间序列数据。
这两者都只能在某一纵向或横向上探究数据,且部分前提条件又很难满足。
而函数型数据连续型函数与离散型函数长期以来的分离状态,实现了离散和连续的过度。
它很少依赖于模型构建及假设条件。通过使用函数型数据,我们可以发掘新冠疫情数据中更多的信息。

Mingji Tang
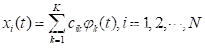
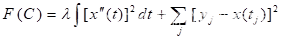
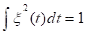
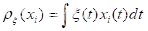
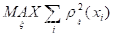
项目结果

随时关注您喜欢的主题
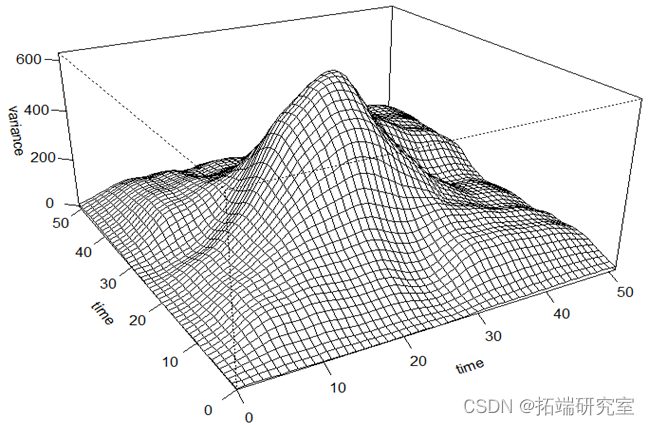
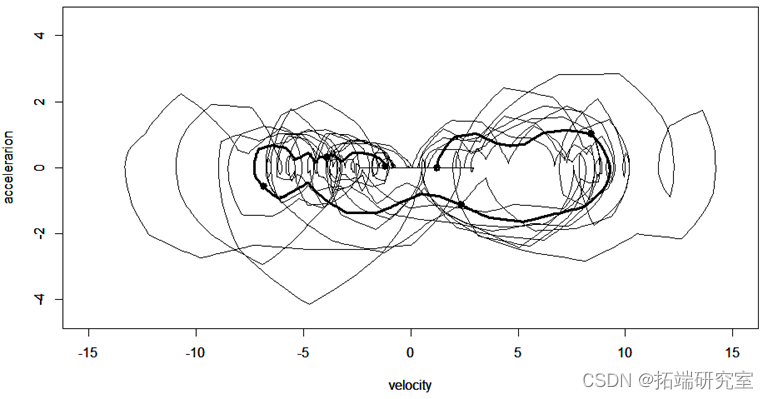
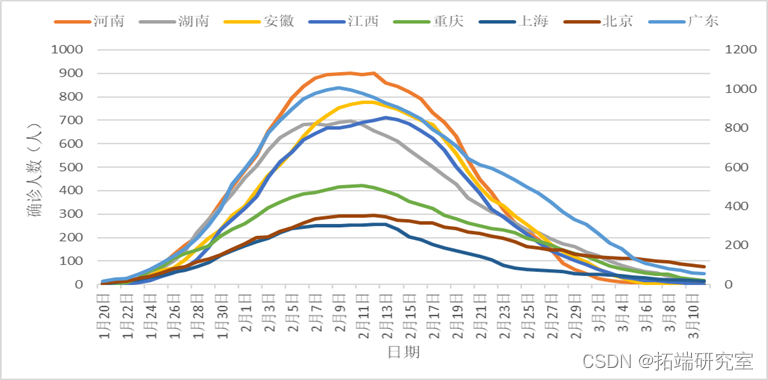
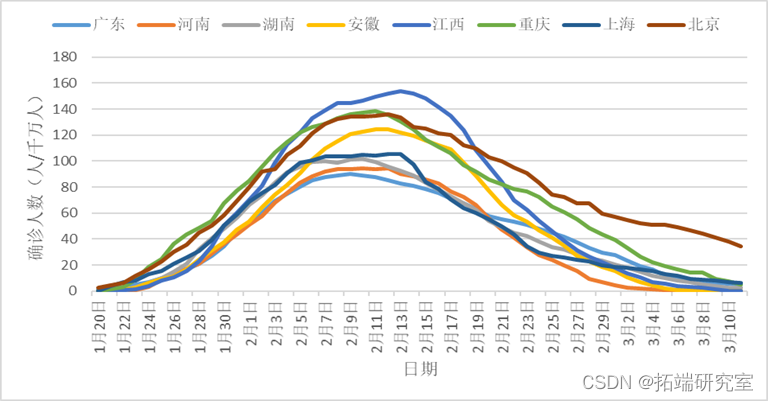
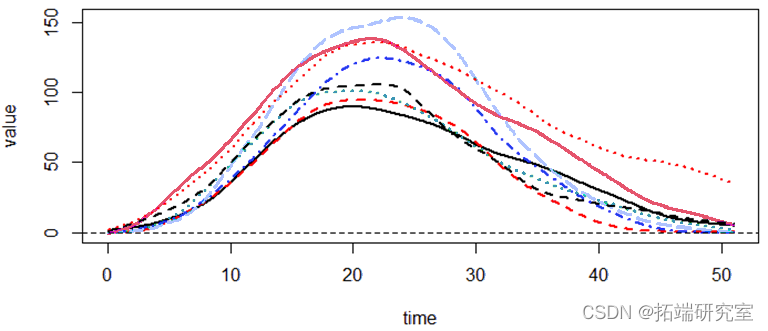
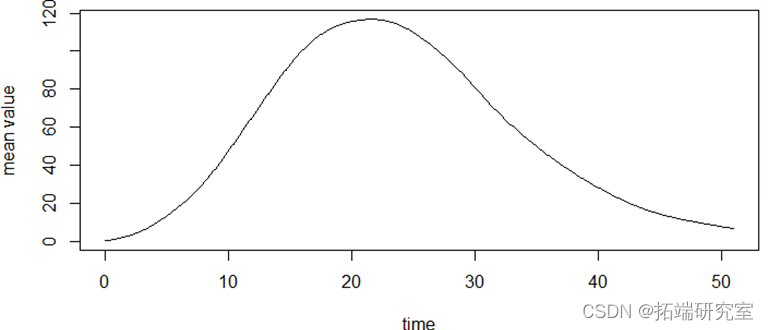
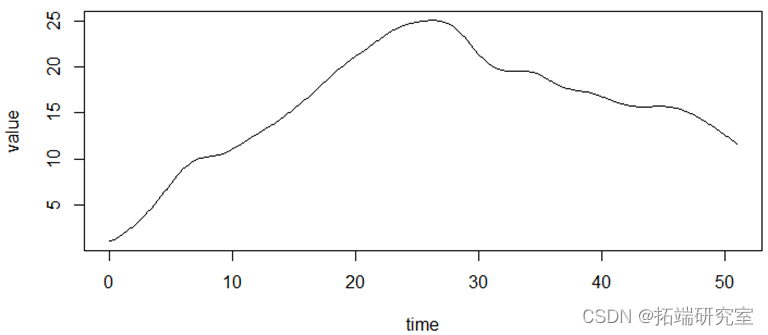
以上分别为函数型数据的均值,方差,协方差以及相位图。(其中粗线部分是由均值绘制的相位图。)疫情的发展可以看作一个由平稳态逐渐发展为不平稳态,最后再回到平稳态的过程。相位图中,我们通常把加速度称为势能,而把速度称为动能。在第一象限阶段,病毒的传播自身的传播力度为主要势能,人们的防疫措施尚未建立完全,因此势能为正,不断转化为动能;在第12天左右的位置,势能由正变成负,函数的凹凸性发生了变化,也就是说人们的防疫管控力度已经成为了主要势能,疫情的传播达到了拐点,增长速度得到了控制;在第22天左右的位置,动能由正变成负,函数的单调性发生了变化,疫情的传播达到了极值点,感染人数从增长变为了减少;轨迹进入三四象限之后,疫情就逐渐缓解,当感染人数逐渐接近0的时候,减少的速度也会逐渐放缓,也就是加速度会回到一个较小的正值,最终当动能回到0时,也就意味着疫情的基本结束。
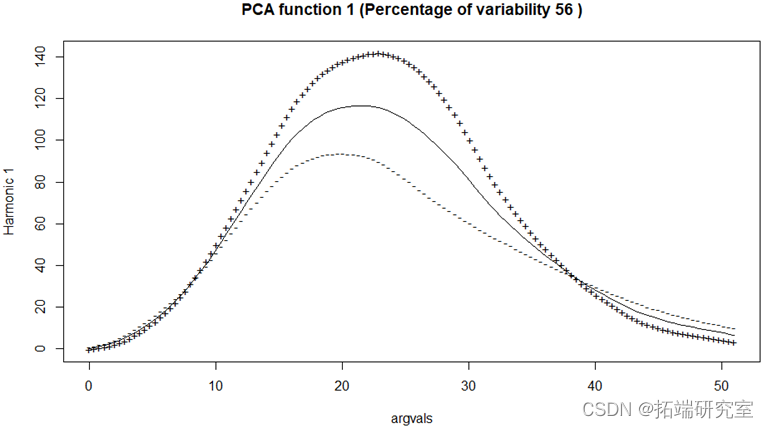
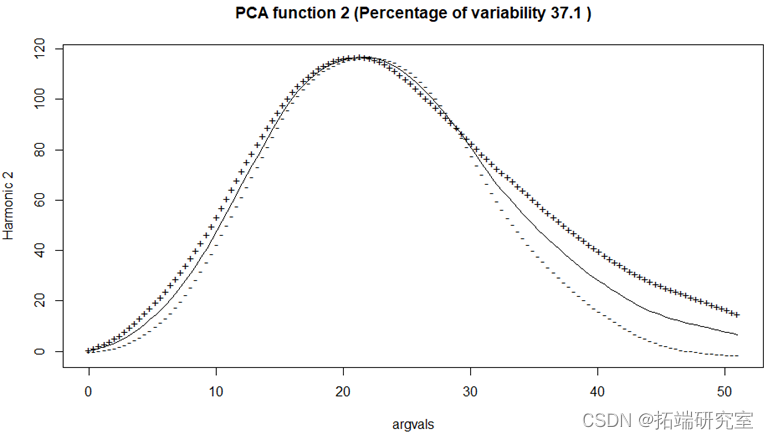
以上为前两个主成分,并可以绘制二维的主成分得分图。可以看到前两个主成分包含的数据信息已经超过了92%。
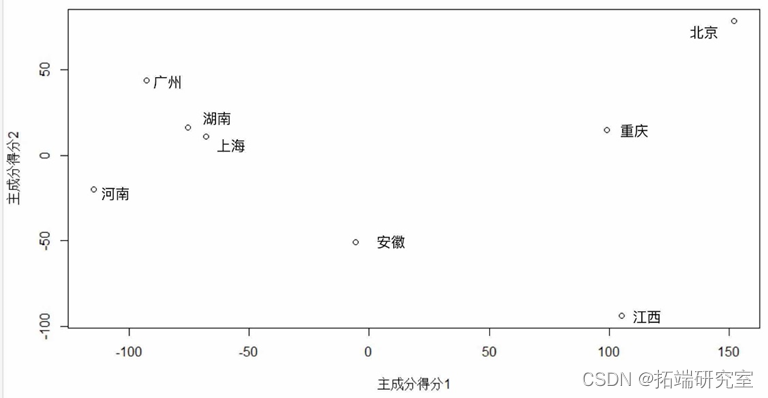
可以看到,从横坐标来看,右侧的北京,重庆,江西三省市的第一主成分得分较高,也就意味着和第一主成分函数正向吻合,在中期的值较大,即疫情巅峰时期的感染人口比例较大;反之,河南,广东,湖南,上海四省市第一主成分得分较低,疫情巅峰时期感染人口比例较小。再观察纵坐标,主要反映了后期即3月之后的疫情感染人口比例,可以发现北京,广东两地仍处于较高的水平,这也与两地人口密度大,人口流量大有关。而广西,安徽等地感染人口比例已经基本趋于0。
关于作者
Mingji Tang
在此对Mingji Tang对本文所作的贡献表示诚挚感谢,他专长时间序列、机器学习、回归分析。
 Python、Flask、ECharts及MySQL疫情数据可视化系统设计与实现——多模块联动实时展示优化|附代码数据
Python、Flask、ECharts及MySQL疫情数据可视化系统设计与实现——多模块联动实时展示优化|附代码数据 疫情期间航空网络演变复杂网络可视化
疫情期间航空网络演变复杂网络可视化 上海、国际新冠疫情数据分析可视化
上海、国际新冠疫情数据分析可视化



