Keras实现MLP和CNN模型和RNN模型
在本文中,您将发现如何使用标准深度学习模型(包括多层感知器(MLP),卷积神经网络(CNN)和递归神经网络(RNN))开发,评估和做出预测。
多层感知器模型(简称MLP)是标准的全连接神经网络模型。
可下载资源
它由节点层组成,其中每个节点连接到上一层的所有输出,每个节点的输出连接到下一层节点的所有输入。
通过一个或多个密集层创建MLP 。此模型适用于表格数据,即表格或电子表格中的数据,每个变量一列,每个变量一行。您可能需要使用MLP探索三个预测建模问题;它们是二进制分类,多分类和回归。
让我们针对每种情况在真实数据集上拟合模型。
对于深层学习领域的初学者来说,知道使用哪种类型的网络可能是困难的。每天都有那么多类型的网络可供选择,并且有新的方法被公布和讨论。更糟糕的是,大多数神经网络足够灵活,即使用于错误的数据类型或预测问题,它们也能够工作(进行预测)。
要关注什么神经网络?
深度学习是使用现代硬件的人工神经网络的应用。
它允许开发、训练和使用比先前认为可能更大(更多层)的神经网络。
研究人员提出了成千上万种特定的神经网络作为对现有模型的修改或调整。有时完全是新的方法。
作为一名实践者,我建议等到模型变得普遍适用时再进行操作。从每天或每周发布的大量出版物的噪音中,很难弄清楚什么工作正常。
一般来说,我建议您关注三类人工神经网络。他们是:
多层感知器(MLP)
卷积神经网络(CNN)
递归神经网络(RNN)
这三类网络提供了很大的灵活性,并且经过几十年的实践证明,它们在广泛的问题中是有用的和可靠的。它们也有许多子类型来帮助专门针对预测问题的不同框架和不同数据集的特性。
现在我们已经知道了应该关注哪些网络,让我们看看何时可以使用每类神经网络。
何时使用多层感知器?
多层感知器,简称MLP,是神经网络的经典类型。
它们由一层或多层神经元组成。数据被馈送到输入层,可能存在一个或多个提供抽象级别的隐藏层,并且在输出层(也称为可见层)上进行预测。
MLP适用于分类预测问题,其中输入被分配一个类或标签。
它们也适用于回归预测问题,其中给定一组输入对实值量进行预测。数据通常以表格格式提供,如您在CSV文件或电子表格中看到的那样。
使用MLP用于:
表格式数据集
分类预测问题
回归预测问题
它们非常灵活,通常可用于学习从输入到输出的映射。
这种灵活性允许将它们应用于其他类型的数据。例如,可以将图像的像素减少到一长行数据,并将其输入给MLP。文档的单词也可以减少为一长行数据,并输入给MLP。即使时间序列预测问题的滞后观测值也可以减少为长数据行并输入给MLP。
因此,如果您的数据不是表格式数据集,例如图像、文档或时间序列,那么我建议至少测试一个MLP。这些结果可以用作比较基准点,以确认其他可能看起来更适合增值的模型。
尝试MLPs 在:
图像数据
文本数据
时间序列数据
其他类型的数据
何时使用卷积神经网络?
卷积神经网络(CNN)被设计成将图像数据映射到输出变量。
它们被证明是如此的有效,以至于对于涉及图像数据作为输入的任何类型的预测问题,它们都是可行的方法。
使用CNN的好处是它们开发二维图像的内部表示的能力。这允许模型学习数据中不同结构中的位置和比例,这对于处理图像非常重要。
使用CNN用于:
图像数据
分类预测问题
回归预测问题
更一般地,CNN能够很好地处理具有空间关系的数据。
CNN输入传统上是二维的,字段或矩阵,但也可以改变为一维,允许它开发一维序列的内部表示。
这允许CNN更一般地用于具有空间关系的其他类型的数据。例如,文本文档中的单词之间存在顺序关系。时间序列的时间步长是有序的关系。
尽管没有专门针对非图像数据开发,CNN在诸如情感分析中使用的文档分类和相关问题方面取得了最先进的结果。
试试CNN:
文本数据
时间序列数据
序列输入数据
何时使用递归神经网络?
递归神经网络(RNNs)被设计成处理序列预测问题。
序列预测问题有多种形式,最好用所支持的输入和输出类型来描述。
序列预测问题的一些示例包括:
一对多:作为输入的观察映射到多个步骤的输出序列。(也就是用一步观测值往后预测多步)
多对一:作为输入映射到类或数量预测的多个步骤的序列。(多步观测值预测一个类别或一步)
多对多:作为输入的多个步骤的序列,映射到具有多个步骤作为输出的序列。(多步观测值预测多步)
多对多问题通常被称为序列对序列,或简称seq2seq。
传统上,递归神经网络很难训练。
长短期记忆网络,或者LSTM,网络可能是最成功的RNN,因为它克服了训练循环网络的问题,并且反过来已经在广泛的应用中使用。
一般来说,RNN和LSTM在处理单词和段落序列(通常称为自然语言处理)时获得了最大的成功。
这包括文本序列和以时间序列表示的口语序列。它们也被用作需要序列输出的生成模型,不仅用于文本,还用于生成手写等应用程序。
使用RNN用于:
文本数据
语音数据
分类预测问题
回归预测问题
生成模型
如您在CSV文件或电子表格中看到的,递归神经网络不适合于表格式数据集。它们也不适合于图像数据输入。
不要使用RNN用于:
表格数据
图像数据
RNN和LSTM已经在时间序列预测问题上进行了测试,但至少可以说结果很差。自回归方法,甚至线性方法通常表现得更好。LSTM常常被应用于相同数据的简单MLP所超越。
然而,它仍然是一个活跃的领域。
也许试试RNNs:
时间序列数据
混合网络模型
CNN或RNN模型很少单独使用。
这些类型的网络在更广泛的模型中用作层,该模型还具有一个或多个MLP层。从技术上讲,这是一种混合型的神经网络结构。
也许最有趣的工作来自于将不同类型的网络混合到混合模型中。
例如,考虑一个模型,该模型使用一个层堆栈,在输入端有一个CNN,在中间有一个LSTM,在输出端有一个MLP。这样的模型可以读取图像输入序列,例如视频,并生成预测。
网络类型还可以堆叠在特定的体系结构中以解锁新功能,例如使用非常深的CNN和MLP网络的可重用图像识别模型,这些网络可以添加到新的LSTM模型中,并用于照片的标题。此外,编码器-解码器LSTM网络,可用于具有不同长度的输入和输出序列。
首先要清楚地考虑您和您的团队从项目中需要什么,然后寻找满足您特定项目需求的网络体系结构(或开发网络体系结构)。
我们将使用LabelEncoder将字符串标签编码为整数值0和1。该模型将适合67%的数据,其余的33%将用于评估,请使用train_test_split()函数进行拆分。
最好将’ relu ‘激活与’ he_normal ‘权重初始化一起使用。在训练深度神经网络模型时,这种组合可以大大克服梯度消失的问题。
该模型预测1类的可能性,并使用S型激活函数。
下面列出了代码片段。
# mlp二分类包
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# 加载数据
path = 'osph.csv'
df = read_csv(path, header=None)
# 分割输入和输出
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# 文本转换数字变量
y = LabelEncoder().fit_transform(y)
# 分割训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 定义输入变量维度
n_features = X_train.shape[1]
#定义模型
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 拟合模型
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0)
在这种情况下,我们可以看到该模型实现了约94%的分类准确度,然后预测单行数据属于1类的概率为0.9。
(235, 34) (116, 34) (235,) (116,)
Test Accuracy: 0.940
Predicted: 0.991用于多类分类的MLP
我们将使用鸢尾花多类分类数据集来演示用于多类分类的MLP。
该问题涉及在给定花的度量的情况下预测鸢尾花的种类。
数据集将使用Pandas自动下载,但您可以在此处了解更多信息。
- 鸢尾花数据集(csv)
- 鸢尾花数据集描述(csv)
鉴于它是一个多类分类,因此该模型在输出层中的每个类必须具有一个节点,并使用softmax激活函数。损失函数是’ sparse_categorical_crossentropy ‘,它适用于整数编码的类标签(例如,一个类为0,下一类为1,等等)
下面列出了在鸢尾花数据集上拟合和评估MLP的代码片段。
# 预测
row = [5.1,3.5,1.4,0.2]
yhat = model.predict([row])
print('Predicted: %s (class=%d)' % (yhat, argmax(yhat)))运行示例将首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单行数据进行预测。
鉴于学习算法的随机性,您的具体结果会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到该模型实现了约98%的分类精度,然后预测了属于每个类别的一行数据的概率,尽管类别0的概率最高。
(100, 4) (50, 4) (100,) (50,)
Test Accuracy: 0.980
Predicted: [[0.8680804 0.12356871 0.00835086]] (class=0)回归的MLP
我们将使用波士顿住房回归数据集来演示用于回归预测建模的MLP。
这个问题涉及根据房屋和邻里的属性来预测房屋价值。
数据集将使用Pandas自动下载,但您可以在此处了解更多信息。
这是一个回归问题,涉及预测单个数值。因此,输出层具有单个节点,并使用默认或线性激活函数(无激活函数)。拟合模型时,均方误差(mse)损失最小。
# 预测
row = [0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]
yhat = model.predict([row])
print('Predicted: %.3f' % yhat)运行示例首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单行数据进行预测。
鉴于学习算法的随机性,您的具体结果会有所不同。尝试运行该示例几次。
在这种情况下,我们可以看到该模型实现了约60的MSE,即约7的RMSE。然后,对于单个示例,预测值约为26。
(339, 13) (167, 13) (339,) (167,)
MSE: 60.751, RMSE: 7.794
Predicted: 26.983开发卷积神经网络模型
卷积神经网络(简称CNN)是一种专为图像输入而设计的网络。
它们由具有卷积层的模型组成,这些卷积层提取特征(称为特征图),并汇集将特征分解为最显着元素的层。
尽管CNN可以用于将图像作为输入的各种任务,但它们最适合图像分类任务。
流行的图像分类任务是MNIST手写数字分类。它涉及成千上万个手写数字,必须将其分类为0到9之间的数字。
tf.keras API提供了便捷功能,可以直接下载和加载此数据集。
下面的示例加载数据集并绘制前几张图像。
pyplot.subplot(5, 5, i+1)
# 绘制原始像素
pyplot.imshow(trainX[i], cmap=pyplot.get_cmap('gray'))
# 显示图片
pyplot.show()运行示例将加载MNIST数据集,然后汇总默认的训练和测试数据集。
Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)然后创建一个图,显示训练数据集中的手写图像示例网格。

MNIST数据集中的手写数字图
我们可以训练CNN模型对MNIST数据集中的图像进行分类。
注意,图像是灰度像素数据的阵列;因此,在将图像用作模型的输入之前,必须向数据添加通道维度。原因是CNN模型期望图像采用通道最后格式,即网络的每个示例均具有[行,列,通道]的尺寸,其中通道代表图像数据的彩色通道。
训练CNN时,将像素值从默认范围0-255缩放到0-1也是一个好主意。
下面列出了在MNIST数据集上拟合和评估CNN模型的代码片段。
# 预测
image = x_train[0]
yhat = model.predict([[image]])
print('Predicted: class=%d' % argmax(yhat))运行示例将首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单个图像进行预测。
首先,报告每个图像的形状以及类别数;我们可以看到每个图像都是28×28像素,并且我们有10个类别。
在这种情况下,我们可以看到该模型在测试数据集上实现了约98%的分类精度。然后我们可以看到该模型预测了训练集中的第一幅图像的5类。
(28, 28, 1) 10
Accuracy: 0.987
Predicted: class=5开发递归神经网络模型
递归神经网络(简称RNN)旨在对数据序列进行操作。
事实证明,它们对于自然语言处理问题非常有效,在自然语言处理问题中,将文本序列作为模型的输入。RNN在时间序列预测和语音识别方面也取得了一定程度的成功。
RNN最受欢迎的类型是长期短期记忆网络,简称LSTM。LSTM可用于模型中,以接受输入数据序列并进行预测,例如分配类别标签或预测数值,例如序列中的下一个值或多个值。
我们将使用汽车销售数据集来证明LSTM RNN用于单变量时间序列预测。
这个问题涉及预测每月的汽车销售数量。
数据集将使用Pandas自动下载,但您可以在此处了解更多信息。
我们将用最近五个月的数据窗口作为问题的框架,以预测当月的数据。
为了实现这一点,我们将定义一个名为split_sequence()的新函数,该函数会将输入序列拆分为适合拟合监督学习模型(如LSTM)的数据窗口。
例如,如果顺序是:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10然后,用于训练模型的样本将如下所示:
Input Output
1, 2, 3, 4, 5 6
2, 3, 4, 5, 6 7
3, 4, 5, 6, 7 8
...我们将使用最近12个月的数据作为测试数据集。
LSTM期望数据集中的每个样本都具有两个维度。第一个是时间步数(在这种情况下为5),第二个是每个时间步的观测数(在这种情况下为1)。
因为这是回归型问题,所以我们将在输出层中使用线性激活函数(无激活函数)并优化均方误差损失函数。我们还将使用平均绝对误差(MAE)指标评估模型。
下面列出了针对单变量时间序列预测问题拟合和评估LSTM的示例。
# lstm 时间序列预测库
from numpy import sqrt
from numpy import asarray
from pandas import read_csv
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
# 分割样本
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
# find the end of this pattern
end_ix = i + n_steps
if end_ix > len(sequence)-1:
break
#合并输入和输出
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return asarray(X), asarray(y)
# 加载数据
path = 'sales.csv'
df = read_csv(path, header=0, index_col=0, squeeze=True)
values = df.values.astype('float32')
#定义窗口大小
n_steps = 5
运行示例将首先报告数据集的形状,然后拟合模型并在测试数据集上对其进行评估。最后,对单个示例进行了预测。
鉴于学习算法的随机性,您的具体结果会有所不同。尝试运行该示例几次。
在这种情况下,模型的MAE约为2,800,并从测试集中预测序列中的下一个值为13,199,其中预期值为14,577(非常接近)。
(91, 5, 1) (12, 5, 1) (91,) (12,)
MSE: 12755421.000, RMSE: 3571.473, MAE: 2856.084
Predicted: 13199.325注意:优良作法是在拟合模型之前对数据进行差分和使其稳定。
如何使用高级模型功能
在本节中,您将发现如何使用一些稍微高级的模型功能,例如查看学习曲线并保存模型以备后用。
如何可视化深度学习模型
深度学习模型的架构可能很快变得庞大而复杂。
因此,对模型中的连接和数据流有一个清晰的了解非常重要。如果您使用功能性API来确保确实按照预期的方式连接了模型的各层,那么这一点尤其重要。
您可以使用两种工具来可视化模型:文本描述和绘图。
文字说明
可以通过在模型上调用summary()函数来显示模型的文本描述。
下面的示例定义了一个三层的小模型,然后总结了结构。
# 定义模型
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(8,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='sigmoid'))
# 摘要
model.summary()运行示例将打印每个层的摘要以及总摘要。
这是用于检查模型中输出形状和参数(权重)数量的诊断。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 90
_________________________________________________________________
dense_1 (Dense) (None, 8) 88
_________________________________________________________________
dense_2 (Dense) (None, 1) 9
=================================================================
Total params: 187
Trainable params: 187
Non-trainable params: 0
_________________________________________________________________模型架构图
您可以通过调用plot_model()函数来创建模型图。
这将创建一个图像文件,其中包含模型中各层的方框图和折线图。
下面的示例创建一个小的三层模型,并将模型体系结构的图保存到包括输入和输出形状的’ model.png ‘。
# 可视化摘要
plot_model(model, 'model.png', show_shapes=True)运行示例将创建一个模型图,该图显示具有形状信息的每个图层的框,以及连接图层的箭头,以显示通过网络的数据流。
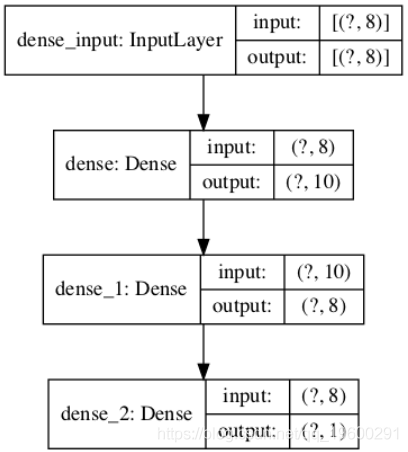
神经网络架构图
如何绘制模型学习曲线
学习曲线是神经网络模型随时间变化的曲线图,例如在每个训练时期结束时计算的曲线。
学习曲线图可洞悉模型的学习动态,例如模型是否学习得很好,模型是否适合训练数据集或模型是否适合训练数据集。
您可以轻松地为您的深度学习模型创建学习曲线。
首先,您必须更新对fit函数的调用,以包括对验证数据集的引用。这是训练集的一部分,不用于拟合模型,而是用于在训练过程中评估模型的性能。
您可以手动拆分数据并指定validation_data参数,也可以使用validation_split参数并指定训练数据集的拆分百分比,然后让API为您执行拆分。后者目前比较简单。
fit函数将返回一个历史对象,其中包含在每个训练时期结束时记录的性能指标的痕迹。这包括选择的损失函数和每个配置的度量(例如准确性),并且为训练和验证数据集计算每个损失和度量。
学习曲线是训练数据集和验证数据集上的损失图。我们可以使用Matplotlib库从历史对象创建此图。
下面的示例将小型神经网络适合于合成二进制分类问题。在训练期间,使用30%的验证比例来评估模型,然后使用折线图绘制训练和验证数据集上的交叉熵损失。
# 绘制学习曲线
pyplot.title('Learning Curves')
pyplot.xlabel('Epoch')
pyplot.ylabel('Cross Entropy')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='val')
pyplot.legend()
pyplot.show()运行示例使模型拟合数据集。运行结束时,将返回历史对象,并将其用作创建折线图的基础。
可以通过“ 损失 ”变量访问训练数据集的交叉熵损失,并通过历史对象的历史记录属性上的“ val_loss ”访问验证数据集的损失。
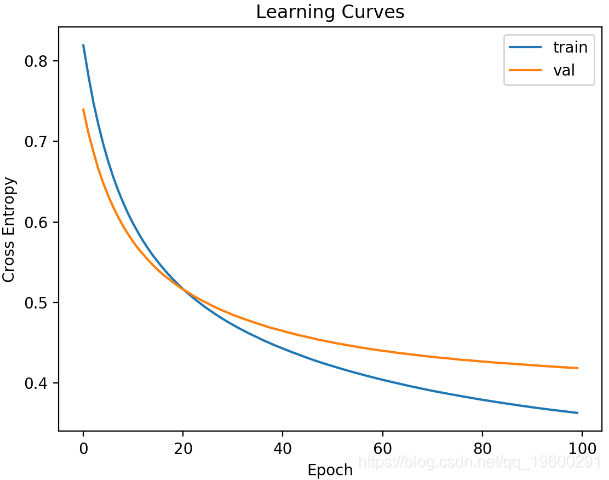
深度学习模型的交叉熵损失学习曲线
如何保存和加载模型
训练和评估模型很棒,但是我们可能希望稍后使用模型而不必每次都对其进行重新训练。
这可以通过将模型保存到文件中,然后加载它并使用它进行预测来实现。
这可以通过使用模型上的save()函数来保存模型来实现。稍后可以使用load_model()函数加载它。
模型以H5格式(一种有效的阵列存储格式)保存。因此,您必须确保在工作站上安装了h5py库。这可以使用pip来实现;例如:
pip install h5py
下面的示例将一个简单模型拟合为合成二进制分类问题,然后保存模型文件。
# 保存模型样例
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# 数据集
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1)
n_features = X.shape[1]
# 定义模型
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
sgd = SGD(learning_rate=0.001, momentum=0.8)
model.compile(optimizer=sgd, loss='binary_crossentropy')
# 拟合
model.fit(X, y, epochs=100, batch_size=32, verbose=0, validation_split=0.3)
# 保存
model.save('model.h5')运行示例将适合模型,并将其保存到名为“ model.h5 ”的文件中。
然后,我们可以加载模型并使用它进行预测,或者继续训练它,或者用它做我们想做的任何事情。
下面的示例加载模型并使用它进行预测。
# 加载保存的模型
from sklearn.datasets import make_classification
from tensorflow.keras.models import load_model
# 数据
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1)
# 加载模型
model = load_model('model.h5')
# 预测
row = [1.91518414, 1.14995454, -1.52847073, 0.79430654]
yhat = model.predict([row])
print('Predicted: %.3f' % yhat[0])运行示例将从文件中加载图像,然后使用它对新的数据行进行预测并打印结果。
Predicted: 0.831
如何获得更好的模型性能
在本部分中,您将发现一些可用于改善深度学习模型性能的技术。
改善深度学习性能的很大一部分涉及通过减慢学习过程或在适当的时间停止学习过程来避免过度拟合。
如何减少过度拟合:Dropout
这是在训练过程中实现的,在训练过程中,一些图层输出被随机忽略或“ 掉线 ”。
您可以在要删除输入连接的图层之前,在新模型中将Dropout添加为模型。
这涉及添加一个称为Dropout()的层,该层接受一个参数,该参数指定前一个输出的每个输出下降的概率。例如0.4表示每次更新模型都会删除40%的输入。
您也可以在MLP,CNN和RNN模型中添加Dropout层,尽管您也可能想探索与CNN和RNN模型一起使用的Dropout的特殊版本。
下面的示例将一个小型神经网络模型拟合为一个合成二进制分类问题。
在第一隐藏层和输出层之间插入一个具有50%滤除率的滤除层。
# dropout样例
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from matplotlib import pyplot
# 数据
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# 模型
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy')
# 拟合模型
model.fit(X, y, epochs=100, batch_size=32, verbose=0)如何通过批量归一化来加速训练
某一层的输入的规模和分布会极大地影响该层的训练程度。
这通常就是为什么在使用神经网络模型进行建模之前先标准化输入数据是一个好主意的原因。
批处理规范化是一种用于训练非常深的神经网络的技术,该技术可将每个输入标准化。这具有稳定学习过程并显着减少训练深度网络所需的训练时期的数量的效果。
您可以在网络中使用批量归一化,方法是在希望具有标准化输入的层之前添加一个批量归一化层。您可以对MLP,CNN和RNN模型使用批标准化。
下面的示例定义了一个用于二进制分类预测问题的小型MLP网络,在第一隐藏层和输出层之间具有批处理归一化层。
# 标准化
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import BatchNormalization
from matplotlib import pyplot
# 数据
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# 输入特征定义
n_features = X.shape[1]
# 定义模型
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(BatchNormalization())
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy')
#拟合模型
model.fit(X, y, epochs=100, batch_size=32, verbose=0)如何在适当的时间停止训练并尽早停止
神经网络具有挑战性。
训练太少,模型不适合;训练过多,模型过度适合训练数据集。两种情况都导致模型的有效性降低。
解决此问题的一种方法是使用提前停止。这涉及监视训练数据集和验证数据集(训练集的子集未用于拟合模型)的损失。一旦验证集的损失开始显示过度拟合的迹象,训练过程就可以停止。
通过首先确保您具有验证数据集,可以对模型使用提前停止。您可以通过fit()函数的validation_data参数手动定义验证数据集,也可以使用validation_split并指定要保留以进行验证的训练数据集的数量。
然后,您可以定义EarlyStopping并指示它监视要监视的性能度量,例如“ val_loss ”以确认验证数据集的损失,以及在采取措施之前观察到的过度拟合的时期数,例如5。
然后,可以通过采用回调列表的“ callbacks ”参数将已配置的EarlyStopping回调提供给fit()函数。
这使您可以将时期数设置为大量,并确信一旦模型开始过度拟合,训练就会结束。您可能还想创建一条学习曲线,以发现更多有关跑步和停止训练的学习动态的见解。
下面的示例演示了有关合成二进制分类问题的小型神经网络,该问题在模型开始过度拟合后(约50个历元后)立即使用停止功能停止训练。
#停止训练
es = EarlyStopping(monitor='val_loss', patience=5)
# 拟合模型
history = model.fit(X, y, epochs=200, batch_size=32, verbose=0, validation_split=0.3, callbacks=[es])
 Python遗传算法GA对长短期记忆LSTM深度学习模型超参数调优分析司机数据
Python遗传算法GA对长短期记忆LSTM深度学习模型超参数调优分析司机数据 Python中Keras微调Google Gemma:定制化指令增强大型语言模型LLM
Python中Keras微调Google Gemma:定制化指令增强大型语言模型LLM Python用线性回归和TensorFlow非线性概率神经网络不同激活函数分析可视化
Python用线性回归和TensorFlow非线性概率神经网络不同激活函数分析可视化 SPSS多层感知器 (MLP)神经网络预测全国污染物综合利用量数据
SPSS多层感知器 (MLP)神经网络预测全国污染物综合利用量数据


