2017 年年中,R 推出了 Keras 包 ,这是一个在 Tensorflow 之上运行的综合库,具有 CPU 和 GPU 功能。本文将演示如何在 R 中使用 LSTM 实现时间序列预测。
时间序列涉及按时间顺序收集的数据。
RNN(循环神经网络)是一种具有循环结构的神经网络,
它能够处理序列数据,例如时间序列数据、自然语言等。
RNN 的特点是可以利用前面的信息来影响后面的输出,具有记忆能力。
LSTM(长短期记忆网络)是一种特殊的 RNN,它能够更好地处理长期依赖问题。
LSTM 通过引入门控机制,
可以控制信息的流动和遗忘,从而有效地保存长期的信息,同时避免梯度消失和梯度爆炸问题。

简单的介绍
我用 xt∈R 表示单变量数据,其中 t∈T 是观察数据时的时间索引。时间 t 在 T=Z 的情况下可以是离散的,或者在 T=R 的情况下是连续的。为简化分析,我们将仅考虑离散时间序列。
长短期记忆 (LSTM) 网络是一种特殊的循环神经网络 (RNN),能够学习长期依赖关系。在常规的 RNN 中,小权重通过几个时间步一遍又一遍地相乘,并且梯度逐渐减小到零——这种情况称为梯度消失问题。
LSTM 网络通常由通过层连接的内存块(称为单元)组成。单元中的信息同时包含在单元状态 Ct 和隐藏状态 ht 中,并由称为门的机制通过 sigmoid 和 tanh 激活函数进行调节。
sigmoid 函数/层输出 0 到 1 之间的数字,其中 0 表示 没有通过 , 1 表示 全部通过。因此,LSTM 能够有条件地从单元状态中添加或删除信息。
一般来说,门将前一时间步 ht-1 和当前输入 xt 的隐藏状态作为输入,并将它们逐点乘以权重矩阵 W,并将偏差 b 添加到乘积中。
三个主要门:
- 遗忘门:
- 这决定了哪些信息将从单元状态中删除。
- 输出是一个介于 0 和 1 之间的数字,0 表示 全部删除 ,1 表示 全部记住

- 更新门:
- 在这一步中, tahn 激活层创建一个潜在候选向量,如下所示:

- sigmoid 层创建一个更新过滤器,如下所示:

- 接下来,旧单元状态 Ct-1 更新如下:

- 输出门:
- 在这一步中,sigmoid 层过滤将要输出的单元状态。

- 然后将单元状态 Ct 通过 tanh 函数将值标准化到范围 [-1, 1]。
- 最后,标准化后的单元格状态乘以过滤后的输出,得到隐藏状态 ht 并传递给下一个单元格:
加载必要的库和数据集
# 加载必要的包
library(keras)或者安装如下:
# 然后按如下方式安装 TensorFlow :
install_keras()
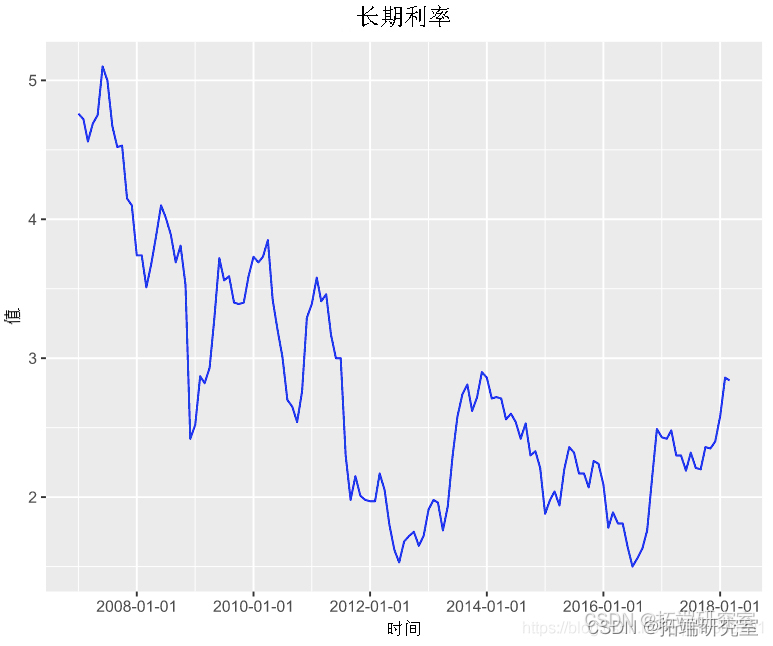
我们将使用可用的长期利率数据 ,这是从 2007 年 1 月到 2018 年 3 月的月度数据。
前五个观察样本
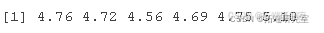
数据准备
将数据转换为平稳数据
这是通过获取系列中两个连续值之间的差异来完成的。这种转换(通常称为差分)会删除数据中与时间相关的成分。
此外,使用差分而不是原始值更容易建模,并且生成的模型具有更高的预测能力。
#将数据转换为平稳性
did = diff
head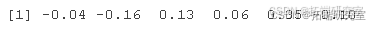

滞后数据集
LSTM 期望数据处于监督学习模式。也就是说,有一个目标变量 Y 和预测变量 X。为了实现这一点,我们通过滞后序列来变换序列,并将时间 (t−k)的值作为输入,将时间 t 的值作为输出,用于 k 步滞后数据集。
sps= laorm
head(sps)随时关注您喜欢的主题

将数据集拆分为训练集和测试集
与大多数分析中训练和测试数据集是随机抽样的不同,对于时间序列数据,观察的顺序确实很重要。以下代码将系列的 前 70% 作为训练集,其余 30% 作为测试集。
## 分成训练集和测试集
N = nrow
n = round
tran = sud[1:n, ]
tt = sud[(n+1):N, ]标准化数据
就像在任何其他神经网络模型中一样,我们将输入数据 X 重新标准化到激活函数的范围。如前所述,LSTM 的默认激活函数是 sigmoid 函数,其范围为 [-1, 1]。下面的代码将有助于这种转换。
请注意,训练数据集的最小值和最大值是用于标准化训练和测试数据集以及预测值的标准化系数。这确保了测试数据的最小值和最大值不会影响模型。
## 标准化数据
Sad = scaa(trin, et, c(-1, 1))
y_in = Sed$slrn[, 2]
x_tn = Scd$sldin[, 1]
y_st = Sald$sleet[, 2]
x_st = Saed$sett[, 1]
想了解更多关于模型定制、咨询辅导的信息?
将需要以下代码将预测值恢复为原始比例。
## 逆变换
invtg = function(sle, slr, fue = c(0, 1))我们设置参数 stateful = TRUE 以便在处理一批样本后获得的内部状态被重新用作下一批样本的初始状态。
定义
定义模型
由于网络是有状态的,我们必须从当前 [ samples , features ] 中以 [ samples , timesteps , features ]形式的 3 维数组提供输入批次,其中:
样本:每批中的观察数,也称为批大小。
时间步长:给定观察的单独时间步长。在此示例中,时间步长 = 1
特征:对于单变量情况,如本例所示,特征 = 1

批量大小必须是训练样本和测试样本大小的共同因素。可以找到 LSTM 输入的一个很好的解释
# 将输入重塑为 3-维
# 指定所需的参数
bahse = 1 # 必须是训练样本和测试样本的公因子
ni = 1 # 可以调整这个,在模型调整阶段
#====================
keras_model_sequential
layer_lstm%>%
layer_dense
编译模型
在这里,我将 mean_squared_error指定 为损失函数,将自适应矩估计 Adam指定为优化算法,并在每次更新时指定学习率和学习率衰减。最后,我使用 准确性 作为评估模型性能的指标。
compile(
optimizer = optimizer_adam
)模型汇总
summary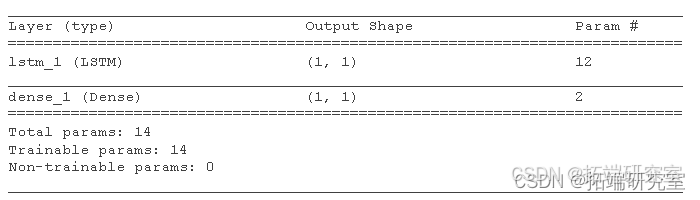
拟合模型
我们设置参数 shuffle = FALSE 以避免打乱训练集并保持 xixi 和 xi+txi+t 之间的依赖关系。LSTM 还需要在每个 epoch 之后重置网络状态。为了实现这一点,我们在 epoch 上运行一个循环,在每个 epoch 中我们拟合模型并通过参数 reset_states()重置状态。
for(i in 1:phs ){
model %>% fit
model %>% reset_states
}作出预测
for(i in 1:L){
# 反转缩放
yhat = invert_scaling
# 逆差分
yhat = yhat + Sis[(n+i)]
}绘制值
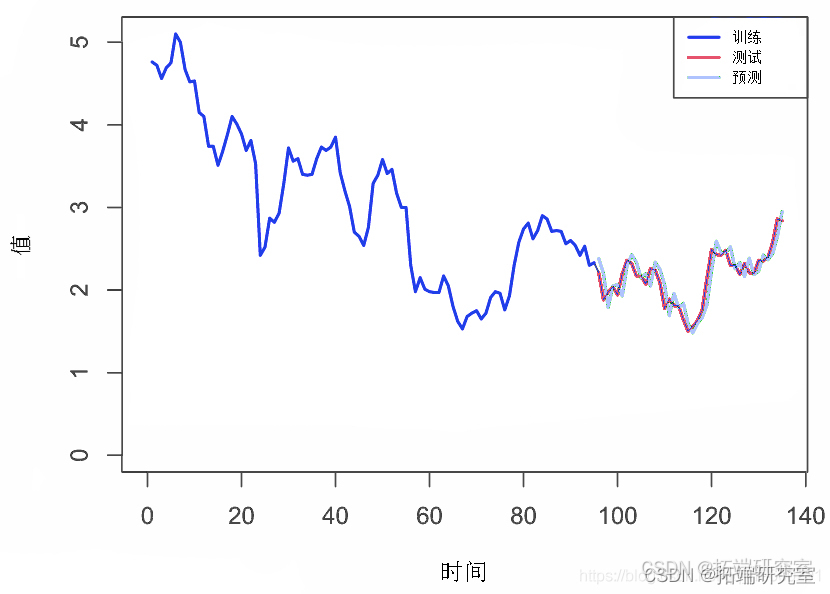

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码
Python熵权法、CUSUM与PSO-BP组合模型在网球竞技动量实时监控与胜负预测研究|附数据代码 Python梯度提升树、SHAP与递归特征消除构建血栓风险分级预测模型|附代码数据
Python梯度提升树、SHAP与递归特征消除构建血栓风险分级预测模型|附代码数据 Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据
Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据 Python随机矩阵理论RMT算法实现ADRB1受体药物虚拟筛选高精度AUC预测|附数据代码
Python随机矩阵理论RMT算法实现ADRB1受体药物虚拟筛选高精度AUC预测|附数据代码

