本文回答了关于逻辑回归的问题:它与线性回归有什么不同,如何在R中用glm()函数拟合和评估这些模型等等?
Logistic回归是机器学习从统计学领域的一种技术。它是用一个或多个解释变量对二项式结果进行建模的一种强大的统计方法。它通过使用逻辑函数估计概率来衡量分类因变量和一个或多个自变量之间的关系,这就是逻辑分布。
本R教程将指导你完成逻辑回归的简单执行。
- 你将首先探索逻辑回归背后的理论:你将了解更多关于与线性回归的区别以及逻辑回归模型的样子。你还会发现多指标和序数逻辑回归。
- 接下来,你将解决R中的逻辑回归问题:你不仅要探索一个数据集,还要使用R中强大的glm()函数拟合逻辑回归模型,评估结果并解决过拟合问题。
可下载资源
提示:如果你有兴趣将你的线性回归技能提高到一个新的水平,也可以考虑参加我们的R语言课程!
概率是我们需要掌握的重要知识,导致认知偏差的重要原因就是相信直觉,而忽视概率。
当我们运用概率知识,了解到这件事情的真实难度,就会知道有些事情不在我们的能力范围之内,早早地避开它们,显然是明智的选择。
金融学里,有一个假说,叫“随机漫步假说”(Random walk hypothesis):
这个假说认为,股票市场的价格,是随机漫步模式,因此它是无法被预测的。
这是什么意思呢?
就是说无论你是谁,预测出股票价格的概率是无穷趋近于50%,
50%是什么意思呢?意思就是“你实际上根本猜不准”,预测正确与否,实际上完全靠运气。跟抛硬币一样。
根据随机漫步假设,对于短期价格预测,预测下一分钟,或者下一小时,甚至第二天的价格,本质上来看,无论用什么样的理论和工具,最终的结果不会优于“抛硬币撞大运”的结果。
到这来,你是不是很悲伤?本来想的股票可以预测,你却告诉我无法预期。
但是,好消息来了!
虽然短期股票无法预测。但是,对于长期价格的预测,实际上是很容易的,因为“基本面”就放在那里:股价最终体现的是企业价值的增长。
1. 短期价格预测是不可能的;
2. 长期价格预测是很可能的;
3. 预测时间期限越长,预测难度越低……
这里的长期是指你至少持有该股票5年以上才算长期,一切不属于“长期价值”的东西,都可以算作是“诱惑”。可以说短期的都是投机,而长期的才是投资。
现在我们已经知道股票长期可以预测,那么一个显然的问题是:市面上有那么多家上市公司,而你的资金又是有限的,究竟该买哪几家公司的股票,才能让你未来5年赚钱的概率最大?
回归分析:简介
逻辑回归是一种回归分析技术。回归分析是一套统计过程,你可以用它来估计变量之间的关系。更具体地说,你用这套技术来模拟和分析一个因变量和一个或多个自变量之间的关系。
回归分析帮助你了解当一个自变量被调整而其他变量被固定时,因变量的典型值如何变化。
正如你已经读到的,有各种回归技术。你可以通过观察三个方面来区分它们:自变量的数量、因变量的类型和回归线的形状。
线性回归
线性回归是最广为人知的建模技术之一。简而言之,它允许你使用线性关系来预测Y的(平均)数值,对于X的一个给定值,用一条直线。这条线被称为 “回归线”。
因此,线性回归模型是y=ax+b。该模型假设因变量y是定量的。然而,在许多情况下,因变量是定性的,或者换句话说,是分类的。例如,性别是定性的,取值为男性或女性。
预测一个观察值的定性反应可以被称为对该观察值进行分类,因为它涉及到将观察值分配到一个类别或等级。另一方面,经常用于分类的方法首先预测定性变量的每个类别的概率,作为进行分类的基础。
线性回归不能够预测概率。例如,如果你使用线性回归为二元因变量建模,所产生的模型可能不会将预测的Y值限制在0和1之内。 这里就是逻辑回归发挥作用的地方,你可以得到一个反映事件发生概率的概率分数。
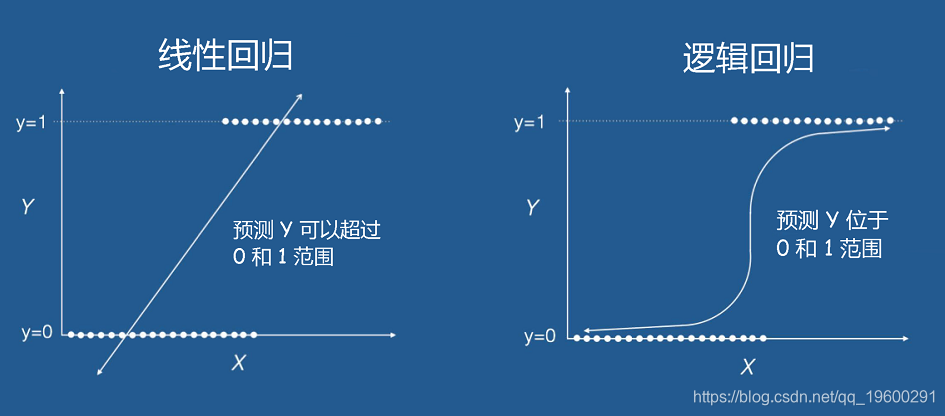
Logistic逻辑回归
逻辑回归是分类技术的一个实例,你可以用它来预测一个定性的反应。更具体地说,逻辑回归是对性别属于某个特定类别的概率建模。
这意味着,如果你想做性别分类,其中反应性别属于男性或女性这两个类别中的一个,你将使用逻辑回归模型来估计性别属于某个特定类别的概率。
例如,给定长头发的性别的概率可以写成:。

Pr(gender=female|longhair)(缩写为p(longhair))的值将在0和1之间。那么,对于任何给定的longhair值,可以对性别进行预测。
鉴于X是解释变量,Y是因变量,那么你应该如何建立p(X)=Pr(Y=1|X)和X之间的关系模型?线性回归模型表示这些概率为。
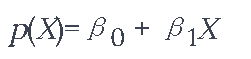
这种方法的问题是,任何时候对编码为0或1的二元因变量进行直线拟合,原则上我们总是可以预测X的某些值的p(X)<0,其他值的p(X)>1。
为了避免这个问题,你可以使用logistic函数来建立p(X)的模型,对于X的所有值,它的输出在0和1之间。
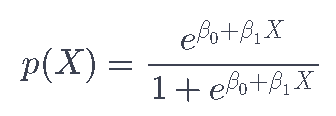
对数函数总是会产生一个S型曲线,所以无论X的值是多少,我们都会得到一个合理的预测。
上述方程也可以重构为:
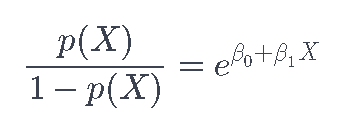

数量
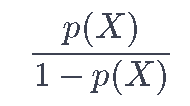
被称为几率比,可以在0和∞之间取任何值。接近0和∞的几率值分别表示p(X)的概率非常低和非常高。
通过从上式中对两边取对数,你可以得到。
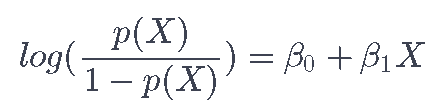
左手边被称为Logit。在一个逻辑回归模型中,增加一个单位的X会使对数改变β0。但无论X的价值如何,如果β1是正的,那么增加X将与增加P(X)相关,如果β1是负的,那么增加X将与减少P(X)相关。
系数β0和β1是未知的,必须根据现有的训练数据来估计。对于逻辑回归,你可以使用最大似然,一种强大的统计技术。让我们再来看看你的性别分类的例子。
随时关注您喜欢的主题
你寻求β0和β1的估计值,将这些估计值插入p(X)的模型中,对于所有的女性样本,产生一个接近于1的数字,对于所有的非女性样本,产生一个接近于0的数字。
可以用一个叫做似然函数的数学方程来正式化。
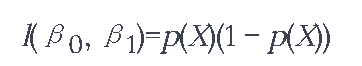
选择估计值β0和β1是为了使这个似然函数最大化。一旦系数被估计出来,你就可以简单地计算出在任何长发的情况下是女性的概率。总的来说,最大似然法是拟合非线性模型的一个非常好的方法。
多项式Logistic回归
到目前为止,本教程只关注了二项式逻辑回归,因为你是将实例分类为男性或女性。多项式Logistic回归模型是二项式Logistic回归模型的一个简单扩展,当探索性变量有两个以上的名义(无序)类别时,你可以使用该模型。
在多项式逻辑回归中,探索性变量被虚拟编码为多个1/0变量。除了一个类别外,所有类别都有一个变量,所以如果有M个类别,就会有M-1M-1个虚拟变量。
每个类别的虚拟变量在其类别中的值为1,在所有其他类别中的值为0。有一个类别,即参考类别,不需要它自己的虚拟变量,因为它是由所有其他变量都是0来唯一识别的。
然后,多叉逻辑回归为每个虚拟变量估计一个单独的二元逻辑回归模型。结果是M-1M-1二元逻辑回归模型。每个模型都传达了预测因素对该类别成功概率的影响,与参考类别相比较。
除了多叉逻辑回归,你还有有序逻辑回归,它是二叉逻辑回归的另一个延伸。
有序logistic逻辑回归
有序回归是用来预测具有 “有序 “的多个类别和自变量的因变量。你已经在这种类型的逻辑回归的名称中看到了这一点,因为 “有序 “意味着 “类别的顺序”。
换句话说,它被用来分析因变量(有多个有序层次)与一个或多个自变量的关系。
例如,你正在进行客户访谈,评估他们对我们新发布产品的满意度。你的任务是向受访者提出一个问题,他们的答案介于满意-满意或不满意-非常不满意之间。为了很好地概括答案,你在回答中加入了一些等级,如非常不满意,不满意,中立,满意,非常满意。这有助于你观察类别中的自然秩序。
用glm进行R语言的Logistic回归
在本节中,你将研究一个二元逻辑回归的例子,你将用ISLR包解决这个问题,它将为你提供数据集,glm()函数一般用于拟合广义线性模型,将用于拟合逻辑回归模型。
加载数据
首先要做的是安装和加载ISLR包,它有你要使用的所有数据集。
在本教程中,你将使用股市数据集。该数据集显示了2001年至2005年间标准普尔500股票指数的每日收益率。
探索数据
让我们来探索一下。names()对于查看数据框上的内容很有用,head()是对前几行的一瞥,而summary()也很有用。

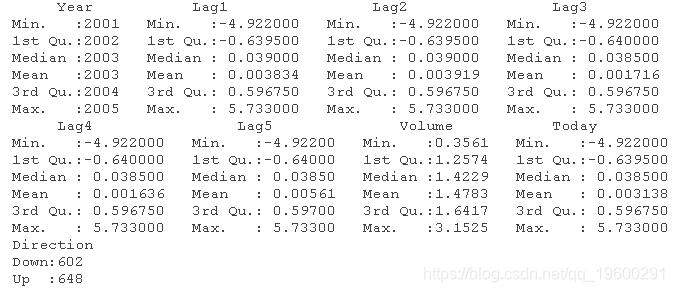
summary()函数为你提供了数据框架上每个变量的简单总结。你可以看到有成交量,收盘价,和涨跌方向。你将使用 “涨跌方向 “作为因变量,因为它显示了自前一天以来市场是上涨还是下跌。
数据的可视化
数据可视化也许是总结和了解你的数据的最快和最有用的方法。你将从单独探索数字变量开始。
直方图提供了一个数字变量的柱状图,它被分成若干个部分,其高度显示了属于每个部分的实例的数量。它们对于获得一个属性的分布特征是很有用的。
for(i in 1:8)hist(Smarket\[,i\]
这是极难看到的,但大多数变量显示出高斯或双高斯的分布。
你可以用盒状图和盒须图以不同的方式来观察数据的分布。盒子包括了数据的中间50%,线显示了中位数,图中的须线显示了数据的合理范围。任何在须线之外的点都是离群值。
for(i in 1:8) boxplot(Smarket\[,i\]
你可以看到,Lags和Today都有一个类似的范围。除此之外,没有任何离群值的迹象。
缺失数据对建模有很大影响。因此,你可以使用缺失图来快速了解数据集中的缺失数据量。X轴显示属性,Y轴显示实例。水平线表示一个实例的缺失数据,垂直块表示一个属性的缺失数据。
mis( col=c("blue", "red")
在这个数据集中没有缺失数据!
让我们开始计算每一对数字变量之间的相关性。这些成对的相关关系可以绘制在相关矩阵图中,了解哪些变量在一起变化。
corrplot(correlations, method="circle")
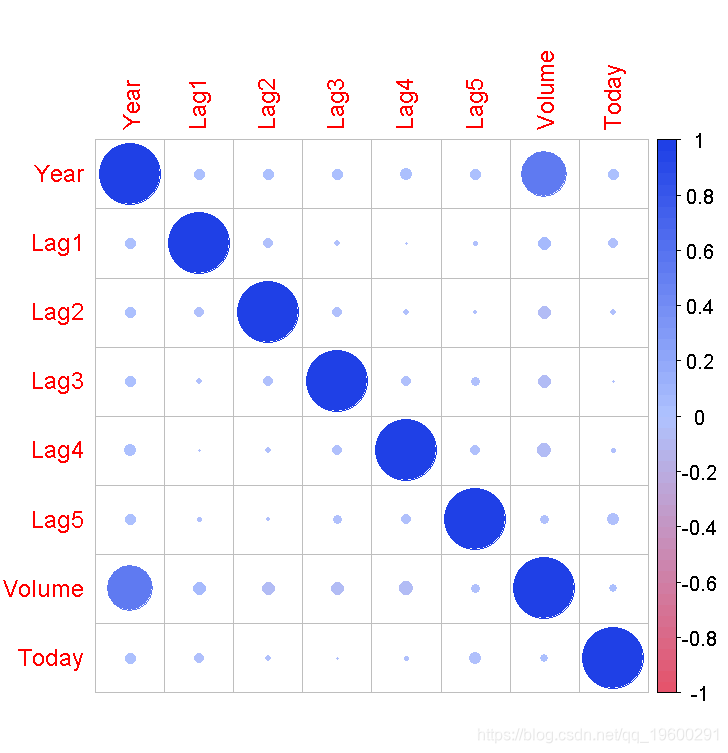
使用点表示法,蓝色代表正相关,红色代表负相关。点越大,相关度越大。你可以看到矩阵是对称的,对角线是完全正相关的,因为它显示了每个变量与自身的相关性。但是,没有一个变量是相互关联的。
我们来做一个数据图。有一个pair()函数可以将Smarket中的变量绘制成一个散点图矩阵。在这种情况下,”涨跌方向”,你的二元因变量,是颜色指标。
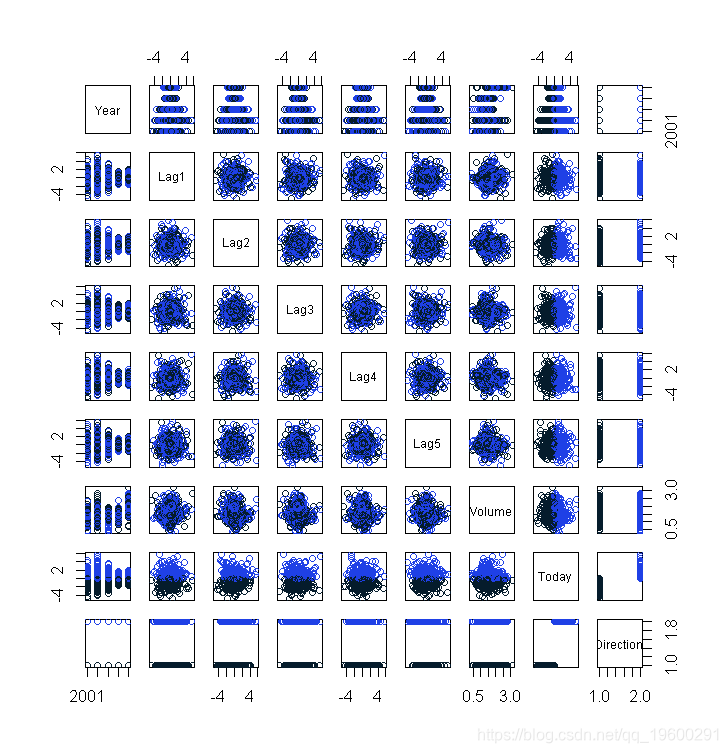
看起来这里没有什么关联性。该类变量来自于变量今日收益,所以涨和跌做了划分。
让我们来看看按方向值细分的每个变量的密度分布。像上面的散点图矩阵一样,按方向绘制的密度图可以帮助看到涨和跌的方向。它还可以帮助了解一个变量的方向的重叠情况。
Plot(x=x, y=y, plot="density", scales=scales)
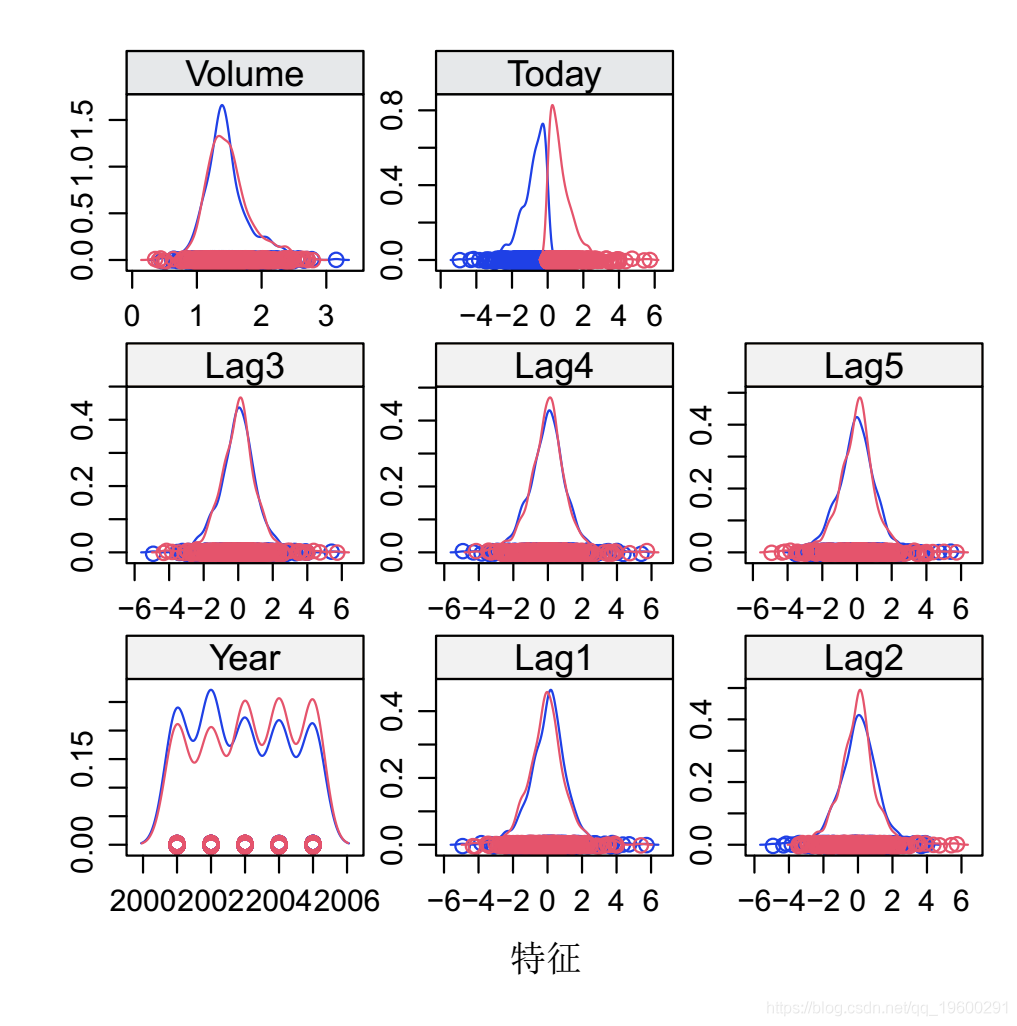
你可以看到,所有这些变量的方向值都是重叠的,这意味着仅凭一两个变量很难预测上涨或下跌。
建立Logistic回归模型
现在你调用glm.fit()函数。你传递给这个函数的第一个参数是一个R公式。在这种情况下,该公式表明方向是因变量,而滞后和成交量变量是预测因素。正如你在介绍中看到的,glm通常用于拟合广义线性模型。
然而,在这种情况下,你需要明确表示你想拟合一个逻辑回归模型。你通过将族参数设置为二项式来解决这个问题。这样,你就告诉glm()把拟合一个逻辑回归模型,而不是可以拟合glm的许多其他模型中的一个。
接下来,你可以做一个summary(),它告诉你一些关于拟合的信息。
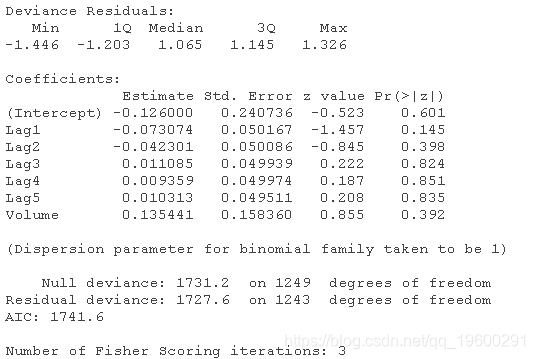
正如你所看到的,summary()返回每个系数的估计值、标准误差、z-score和p值。看上去没有一个系数是显著的。它还给出了无效偏差(仅指平均值的偏差)和残差偏差(包含所有预测因素的模型的偏差)。两者之间的差异非常小,而且有6个自由度。
你把glm.fit()的预测结果分配给glm.probs,类型等于因变量。这将对你用来拟合模型的训练数据进行预测,并给我一个拟合概率的向量。
你看一下前5个概率,它们非常接近50%。
probs\[1:5\]
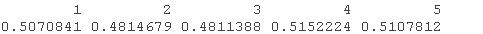
现在我将根据滞后期和其他预测因素对市场是上涨还是下跌做出预测。特别是,我将通过0.5的阈值将概率变成分类。为了做到这一点,我使用ifelse()命令。
ifelse(probs > 0.5, "Up", "Down")
glm.pred是一个真和假的向量。如果glm.probs大于0.5,glm.pred调用 "Up";否则,调用 "False"。
在这里,你附上数据框架Smarket,并制作一个glm.pred的表格,这是上一个方向的上涨和下跌。你还可以取其中的平均值。
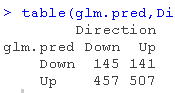
从表中看,对角线上的实例是你获得正确分类的地方,而对角线外的实例是你分类错误的地方。看起来你犯了很多错误。平均值给出的比例是0.52。
创建训练样本和测试样本
你怎么能做得更好呢?把数据分成训练集和测试集是一个好的策略。
# 生成训练和测试集 train = Year<2005 predict(glm.fit, newdata = Smarket\[!train,\], type = "response")
让我们详细看看这个代码块。
train等于比2005年少的那一年。对于所有小于2005年的年份,你会得到一个true;否则,我会得到一个false。- 然后你用glm.fit()重新拟合模型,只是子集等于’train’,这意味着它只拟合小于2005年的数据。
- 然后你再次对glm.probs使用predict()函数来预测大于或等于2005年的剩余数据。对于新的数据,你给了它Smarket,用!”train “作为索引(如果年份大于或等于2005,train为真)。你将类型设置为 “因变量 “以预测概率。
- 最后,你对glm.pred再次使用ifelse()函数来生成上涨和下跌变量。
你现在做一个新的变量来存储测试数据的新子集,并把它叫做Direction.2005。因变量仍然是方向。你制作一个表格并计算这个新测试集的平均值。
Direction.2005 = Direction\[!train\]


比以前的情况还糟糕。怎么会出现这种情况?
解决过度拟合的问题
好吧,你可能对数据进行了过度拟合。为了解决这个问题,你要拟合一个较小的模型,使用Lag1、Lag2、Lag3作为预测因子,从而撇开所有其他变量。代码的其余部分是一样的。
#拟合一个较小的模型 glm(family = binomial, subset = train)

好吧,你得到了59%的分类率,不算太差。使用较小的模型似乎表现得更好。
最后,你对glm.fit做一个summary(),看看是否有任何明显的变化。

没有什么变得很重要,至少P值更好了,表明对性能的预测有所提高。
结语
所以,这个关于使用glm()函数和设置族为二项式建立逻辑回归模型的R教程就结束了。glm()并不假设因变量和自变量之间的线性关系。然而,它假定logit模型中的链接函数和自变量之间存在线性关系,我希望你能学到有价值的东西。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化
Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化 Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证
Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
