
我最近一直在教授建模课程,并一直在阅读和思考适合度的概念。
R方由协变量X解释的结果Y的变化比例通常被描述为拟合优度的度量。这当然看起来非常合理,因为R平方测量观察到的Y值与模型的预测(拟合)值的接近程度。
然而,要记住的重要一点是,R平方不会向我们提供有关我们的模型是否正确指定的信息。也就是说,它没有告诉我们我们是否正确地指定了结果Y的期望如何取决于协变量。特别是,R平方的高值并不一定意味着我们的模型被正确指定。用一个简单的例子说明这是最简单的。
首先,我们将使用R模拟一些数据。为此,我们从标准正态分布(均值为零,方差一)中随机生成X值。然后,我们生成结果Y等于X加上随机误差,再次使用标准正态分布:
n < - 1000
set.seed(512312)
x < - rnorm(n)
y < - x + rnorm(n)
然后我们可以拟合Y的(正确的)线性回归模型,其中X作为协变量:
summary(mod1)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-2.8571 -0.6387 -0.0022 0.6050 3.0716
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.02193 0.03099 0.708 0.479
x 0.93946 0.03127 30.040 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.98 on 998 degrees of freedom
Multiple R-squared: 0.4748, Adjusted R-squared: 0.4743
F-statistic: 902.4 on 1 and 998 DF, p-value: < 2.2e-16
我们还可以绘制数据,用模型中的拟合线覆盖:
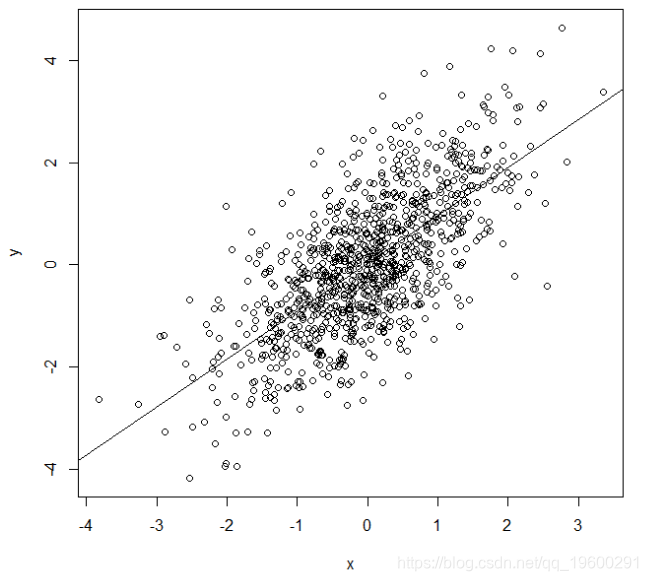

观察到(Y,X)数据并重叠拟合线。
现在让我们重新生成数据,但是生成Y使得它的期望值是X的指数函数:
x < - rnorm(n) y < - exp(x)+ rnorm(n)
当然,在实践中,我们不模拟我们的数据 – 我们观察或收集数据,然后尝试将合理的模型拟合到它。因此,和以前一样,我们可以从拟合简单的线性回归模型开始,该模型假设Y的期望是X的线性函数:
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-3.5022 -0.9963 -0.1706 0.6980 21.7411
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.65123 0.05220 31.63 <2e-16 ***
x 1.53517 0.05267 29.15 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.651 on 998 degrees of freedom
Multiple R-squared: 0.4598, Adjusted R-squared: 0.4593
F-statistic: 849.5 on 1 and 998 DF, p-value: < 2.2e-16
与第一种情况不同,我们获得的参数估计(1.65,1.54)不是“真实”数据生成机制中参数的无偏估计,其中Y的期望是exp(X)的线性函数。此外,我们看到我们得到的R平方值为0.46,再次表明X(包括线性)解释了Y中相当大的变化。我们可能认为这意味着我们使用的模型,即期望Y在X中是线性的,是合理的。但是,如果我们再次绘制观察到的数据,并用拟合线覆盖它:
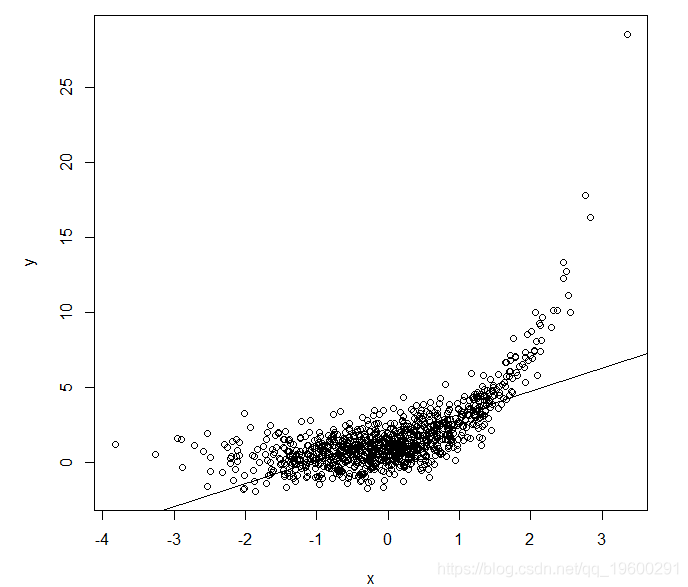

将拟合线叠加到观察到的数据上清楚地表明我们使用的模型未正确指定,尽管R平方值非常大。特别地,我们看到对于X的低值和高值,拟合值太小。这显然是Y的期望取决于exp(X)这一事实的结果,而我们使用的模型假设它是X的线性函数。
这个简单的例子说明,尽管R平方是一个重要的度量,但高值并不意味着我们的模型被正确指定。可以说,描述R平方的更好方法是“解释变异”的度量。为了评估我们的模型是否正确指定,我们应该使用模型诊断技术,例如针对协变量的残差图或线性预测器。
 Python用线性回归和TensorFlow非线性概率神经网络不同激活函数分析可视化
Python用线性回归和TensorFlow非线性概率神经网络不同激活函数分析可视化 Python随机森林、线性回归对COVID-19疫情、汇率数据预测死亡率、病例数、失业率影响可视化
Python随机森林、线性回归对COVID-19疫情、汇率数据预测死亡率、病例数、失业率影响可视化 【视频】R语言用线性回归预测共享单车的需求和可视化|数据分享
【视频】R语言用线性回归预测共享单车的需求和可视化|数据分享 R语言线性回归模型拟合诊断异常值分析家庭燃气消耗量和卡路里实例带自测题
R语言线性回归模型拟合诊断异常值分析家庭燃气消耗量和卡路里实例带自测题


