
在开展基于概率推理的课程时,关键主题之一是基于似然函数的检验和置信区间构建。
通常包括Wald,似然比和分数检验。在这篇文章中,我将修改Wald和似然比检验的优缺点。
可下载资源
我将重点关注置信区间而不是检验 。
示例
我们将X表示观察到的成功次数的随机变量,x表示其实现的值。似然函数只是二项式概率函数,但参数是模型参数。 所以MLE只是观察到的比例。
Wald置信区间
如果我们使用将参数空间(在我们的示例中为区间(0,1))映射到整个实线的变换,那么我们保证在原始比例上获得仅包括允许参数值的置信区间。

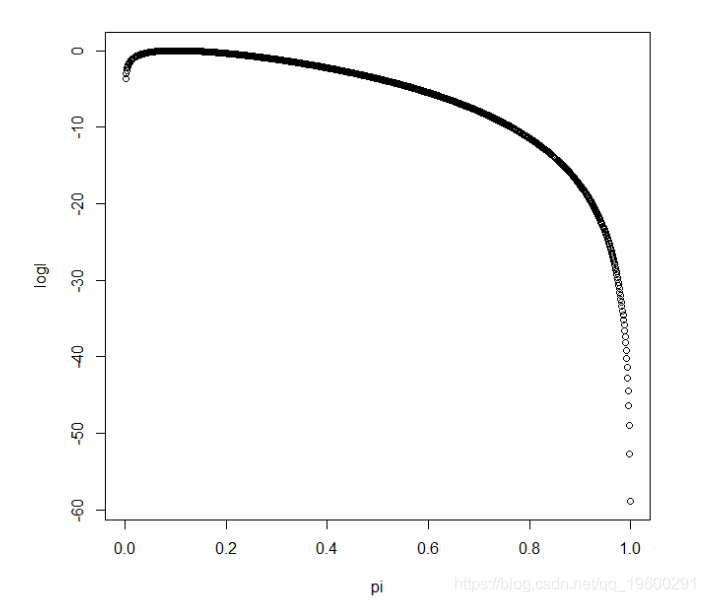
对于概率参数绘制的n = 10,x = 1的二项式示例的对数似然函数:
从视觉上我们可以看出,对数似然函数在绘制时 实际上不是二次方。下图显示了相同的对数似然函数,但现在x轴是对数几率:
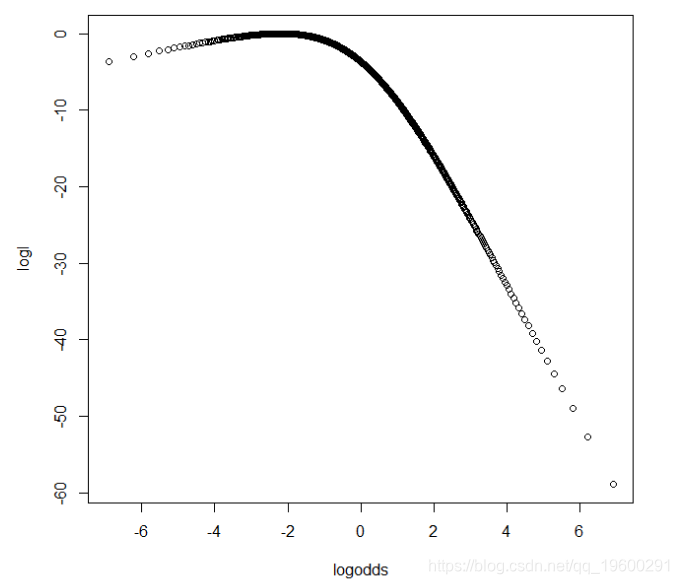
二项式的对数似然函数n = 10 x = 1检验,相对于对数几率。
似然比置信区间
虽然似然比方法具有明显的统计优势,但计算上Wald区间/测试更容易。在实践中,如果样本量不是太小,并且Wald区间是以适当的比例构建的,它们通常是合理的。然而,在小样本中,似然比方法可能是优选的。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据

