在最近的一篇文章中,我描述了一个Metropolis-in-Gibbs采样器,用于估计贝叶斯逻辑回归模型的参数。
这篇文章就此问题进行了研究,以展示Rcpp如何帮助克服这一瓶颈。 TLDR:只需用C ++编写log-posterior而不是矢量化R函数,我们就可以大大减少运行时间。
可下载资源
我模拟了模型的数据:
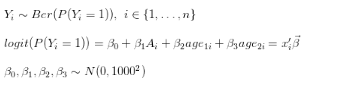
对于这个分析,我编写了两个Metropolis-Hastings(MH)采样器:sample\_mh()和sample\_mh\_cpp()。
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
前者使用对数后验编码作为向量化R函数。后者使用C ++(log\_post.cpp)中的log-posterior编码,并使用Rcpp编译成R函数。Armadillo库对C ++中的矩阵和向量类很有用。
因此,在每次迭代中,提出了系数向量。下面用红线表示链,表示生成数据的参数值。
burnin <- 1000 iter <- 100000 p <- ncol(X) cpp(X, Y, iter = iter, jump = .03) par(mfrow=c(2,2)) plot(mh_cpp\[\[1\]\]\[burnin:iter,'intercept'\]) abline(h= -1, col='red')
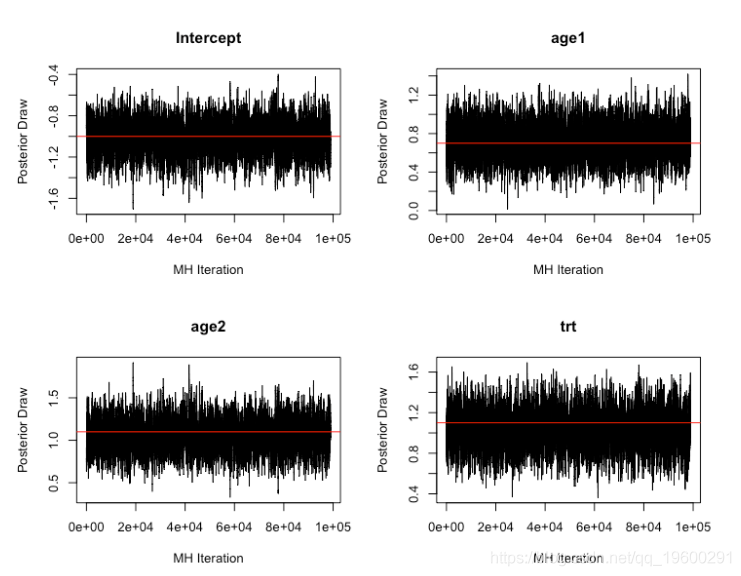
似乎趋同。平均接受概率在采样运行中收敛到约20%。
那么Rcpp实现与R实现相比如何呢?Rcpp的运行时间明显较低。当log-posterior被编码为矢量化R函数时,采样器相对于Rcpp实现运行速度大约慢7倍(样本大小为100)。下图显示了样本大小为100到5000的相对运行时间,增量为500。
for(i in 1:length(s){
benchmark(mh(X, Y, iter = iter)
time\[i\] <- time/rcpp
plot(ss, time)
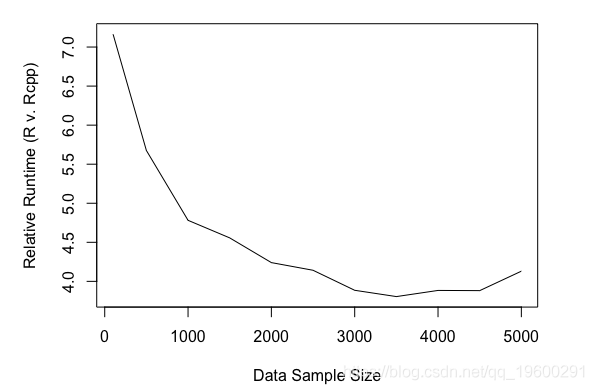
直观地说,C ++带来了一些效率增益。但很明显,Rcpp是解决代码瓶颈的好方法。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据
Python结合TF-IDF、逻辑回归、transformers、DistilBERT实现评论语义搜索|附AI智能体、代码和数据

