Nelson-Siegel- [Svensson]模型是拟合收益曲线的常用方法。它的优点是其参数的经济可解释性,被银行广泛使用。
最近我们被客户要求撰写关于Nelson-Siegel模型的研究报告。
但它不一定在所有情况下都有效:模型参数有时非常不稳定,无法收敛。
Nelson-Siegel 模型是一种用于描述利率期限结构的模型。
它通过几个参数来拟合不同期限的利率,能够较为准确地反映利率随期限变化的趋势。
该模型在金融领域被广泛应用于债券定价、利率风险管理等方面。
通过改进该模型可以提高其拟合效果和准确性。
而神经网络是一种人工智能技术,可以学习数据中的复杂模式和关系,将其应用于改进 Nelson-Siegel 模型,可以更好地捕捉收益率曲线的特征和变化。
收益率曲线是反映不同期限债券收益率之间关系的曲线,对金融市场的分析和决策具有重要意义。

在之前的文章中,我们提供了Nelson-Siegel模型收敛失败的示例,我们已经展示了它的一些缺陷。
蒙特卡洛模拟帮助我们理解:
for(j in 1:N_SIMULATIONS)
{
npo = c(newYields, oldYields)
plot(MATURITY_BASES, oldYields, ylim=c(min(npo), max(npo)))
lines(MATURITY_BASES, oldYields)
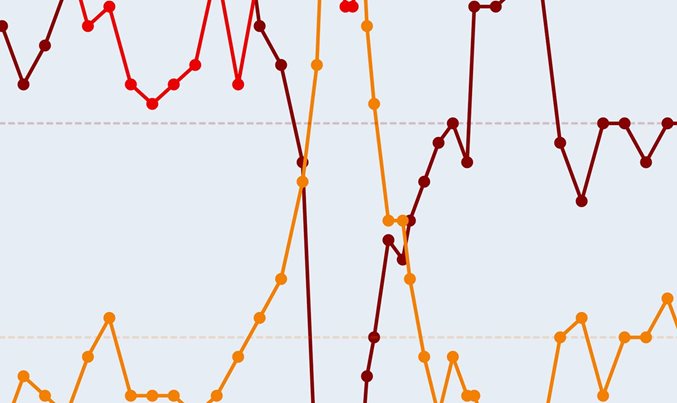
points(MATURITY_BASES, newYields, col="red", pch=4)
points(newMATs, newNsYields, col="blue")
lines(newMATs, newNsYields, col="blue")
Bloomberg用的yield curve构建方法有三种,bootstrap,parametric (e.g. nelson-siegel),spline。这里的bootstrap指的是广义上的,泛指能够reprice所有构建curve的instrument的方法,而不是狭义地指curve stripping的过程。
1. Bootstrap主要用于swap curve的构建。swap market有固定的tenor,并且每个特定的tenor只有一个交易工具,因此对于定价的准确性要求很高。一般swap的market player要求用curve来price swap的时候是要完全能back-out出par coupon的,因此bookstrap是唯一的选择,因为这种方法不管你用什么interpolation或者extrapolation方法,对于market直接有报价的点,定价的时候是完全能match上的,换作拟合的方法是无法做到。对于market quote的点,则做插值处理。
2. Parametric一般用于bond curve,或者又叫做issuer curve的构建。bond的特点就是有固定的到期日,而不像swap market一样每天都有比如5年的swap。这种情况下可能有不同coupon的bond 集中在某个区域,又或者一个aging的bond和一个新issue的bond有相同的到期日(on-the-run vs off-the-run)。这时候就不能用bootstrap的方法来match所有的bond yield,因为这样的curve会非常的kinky。因此这时候只能用parametric的方式。一般这种时候根据不同的用途会用不同的bond construction。比如只用on the run的US treasury bond来构建的active government curve 或者用liquidity达到一定标准的的bond构建的curve,或者取相似rating的bond构建的rating curve。大多数Government,Sovereign,Municipal和Corporate curve都是这么构建的。
3. 最后一种是spline,更具体得说是piecewise spline。上面所说的parametric的办法现实当中有一定的缺陷。第一是因为参数的数量有限,导致曲线虽然平滑,但是限制了它fit更多instrument的能力。第二,这类方法有时候会过度fit曲线上某一个区域(例如短期)的yield导致对于别的区域(例如中长期)fit的误差比较大。spline曲线很好得解决了这个问题,spline方法假设每一段曲线都拥有独立的自由度去fit相应区域的instrument。常见的有cubic或者expoential spline。这样构建出来的曲线兼顾了平滑和拟合度。但是要使用spline curve,这个curve的 instrument得非常liquid。提高了拟合的自由度是一把双刃剑,只有非常liquid的market比如G7的Government bond curve,因为本身不同的tenor之间yield的关系就非常一致,因此能用spline来拟合。如果curve本身不liquid,不同期限的yield非常混乱,比如一些Latam market的curve(像上面提到的多米尼加共和国的曲线),那么还是用parametric curve比较好。
我们要做的是:从一些收益率曲线开始,然后逐步地随机修改收益率,最后尝试NS模型拟合新的收益。因此我们对此进行了模拟。
对于Nelson-Siegel模型,此Monte-Carlo模拟尽管假定前一步的收益(旧收益率) 与NS曲线_完全_匹配。但是,即使如此也无法完全避免麻烦。我们如何发现这些麻烦?在每一步中,我们计算两条相邻曲线之间的最大距离(supremum-norm):
maxDistanceArray[j] = max( abs(oldYieldsArray[j,] - newNsYieldsArray[j,]) )最后,我们找到到上一条曲线的最大距离的步骤,这就是收敛失败的示例。
_maxDistanceArray_的概率密度 如下所示:
分布尾部在0.08处减小,但对于收益率曲线而言,每天偏移8个点并不罕见。因此,尽管我们进行了1e5 = 10000蒙特卡洛模拟,但只有极少数情况,我们可以将其标记为不良。训练神经网络绝对是不够的。
而且,两条Nelson-Siegel曲线可能彼此非常接近,但其参数却彼此远离。由于模型是线性的, 因此可以假设beta的极大变化(例如,超过95分位数)是异常值,并将其标记为不良。
idx = intersect(intersect(which(b0 < q_b0), which(b1 < q_b1)), which(b2 < q_b2))
par(mfrow=c(3,3))
plot(density(log(b0)))
plot(density(log(b1)))
plot(density(log(b2)))
plot(density(log(b0[idx])))
plot(density(log(b1[idx])))
plot(density(log(b2[idx])))
plot(density(b0[idx]))
plot(density(b1[idx]))
plot(density(b2[idx]))
b0 = b0-mean(b0)
b1 = b1-mean(b1)
b2 = b2-mean(b2)
#训练神经网络
X = cbind(b0, b1, b2)
Y = array(0, dim=(N_SIMULATIONS-1))
Y[idx] = 1
然后我们可以训练神经网络
SPLT = 0.8
library(keras)
b = floor(SPLT*(N_SIMULATIONS-1))
plot(history)
model %>% evaluate(x_test, y_test)神经网络不仅在训练集而且在验证集上都提供了高精度。
如果模拟新数据集,对模型进行修改 :例如修改VOLAs = 0.005*sqrt(MATURITY_BASES) 到 VOLAs = 0.05*sqrt(MATURITY_BASES) 将无法识别新数据集上的不良情况。
不足与展望:尽管我们在两种情况下均对数据进行了归一化和平均化,但是模型波动性的线性变化对尾部分位数具有很高的非线性影响。
那么,我们是否需要一个更复杂的AI模型?
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据

