
R语言估计时变VAR模型时间序列的实证研究分析案例
加载包后,我们将此数据集中包含的12个心情变量进行子集化:
在经济与金融等诸多领域中,时间序列数据蕴含着丰富的信息,揭示变量间的动态关系对理解系统运行规律至关重要。
传统向量自回归(VAR)模型在分析多变量时间序列时,假定变量间的关系在整个样本期内保持不变,然而现实世界的复杂性往往使得这种恒定关系的假设难以成立。
时变 VAR 模型应运而生,它允许系数随时间变化,能够更精准地刻画变量间的时变动态关系,为时间序列分析提供了更强大的工具。
本实证研究将借助 R 语言这一功能强大的数据分析平台,深入探究时变 VAR 模型在时间序列分析中的应用,通过实际案例剖析,揭示其估计方法、模型性能及在现实场景中的应用价值。

mood_data <- as.matrix(symptom_data$data[, 1:12]) # 子集变量
mood_labels <- symptom_data$colnames[1:12] # 子集变量标签
colnames(mood_data) <- mood_labels
time_data <- symptom_data$data_time对象mood_data是一个1476×12矩阵,测量了12个心情变量:
> dim(mood_data)
[1] 1476 12
> head(mood_data[,1:7])
Relaxed Down Irritated Satisfied Lonely Anxious Enthusiastic
[1,] 5 -1 1 5 -1 -1 4
[2,] 4 0 3 3 0 0 3
[3,] 4 0 2 3 0 0 4
[4,] 4 0 1 4 0 0 4
[5,] 4 0 2 4 0 0 4
[6,] 5 0 1 4 0 0 3time_data包含有关每次测量的时间戳的信息。数据预处理需要此信息。
> head(time_data)
date dayno beepno beeptime resptime_s resptime_e time_norm
1 13/08/12 226 1 08:58 08:58:56 09:00:15 0.000000000
2 14/08/12 227 5 14:32 14:32:09 14:33:25 0.005164874
3 14/08/12 227 6 16:17 16:17:13 16:23:16 0.005470574
4 14/08/12 227 8 18:04 18:04:10 18:06:29 0.005782097
5 14/08/12 227 9 20:57 20:58:23 21:00:18 0.006285774
6 14/08/12 227 10 21:54 21:54:15 21:56:05 0.006451726
该数据集中的一些变量是高度偏斜的,这可能导致不可靠的参数估计。 在这里,我们通过计算自举置信区间(KS方法)和可信区间(GAM方法)来处理这个问题,以判断估计的可靠性。 由于本教程的重点是估计时变VAR模型,因此我们不会详细研究变量的偏度。 然而,在实践中,应该在拟合(时变)VAR模型之前始终检查边际分布。
估计时变VAR模型
通过参数lags = 1,我们指定拟合滞后1 VAR模型,并通过lambdaSel =“CV”选择具有交叉验证的参数λ。 最后,使用参数scale = TRUE,我们指定在模型拟合之前,所有变量都应标准化。 当使用“1正则化”时,建议这样做,因为否则参数惩罚的强度取决于预测变量的方差。 由于交叉验证方案使用随机抽取来定义,因此我们设置种子以确保重现性。
在查看结果之前,我们检查了1476个时间点中有多少用于估算,这在调用输出对象的摘要中显示
> tvvar_obj
mgm fit-object
Model class: Time-varying mixed Vector Autoregressive (tv-mVAR) model
Lags: 1
Rows included in VAR design matrix: 876 / 1475 ( 59.39 %)
Nodes: 12
Estimation points: 20估计的VAR系数的绝对值存储在对象tvvar_obj $ wadj中,该对象是维度p×p×滞后×estpoints的数组。
参数估计的可靠性
res_obj <- resample(object = tvvar_obj,
data = mood_data,
nB = 50,
blocks = 10,seeds = 1:50,
quantiles = c(.05, .95))res_obj $ bootParameters包含每个参数的经验采样分布。
计算时变预测误差
函数predict()计算给定mgm模型对象的预测和预测误差。
预测存储在pred_obj $预测中,并且所有时变模型的预测误差组合在pred_obj中:
> pred_obj$errors
Variable Error.RMSE Error.R2
1 Relaxed 0.939 0.155
2 Down 0.825 0.297
3 Irritated 0.942 0.119
4 Satisfied 0.879 0.201
5 Lonely 0.921 0.182
6 Anxious 0.950 0.086
7 Enthusiastic 0.922 0.169
8 Suspicious 0.818 0.247
9 Cheerful 0.889 0.200
10 Guilty 0.928 0.175
11 Doubt 0.871 0.268
12 Strong 0.896 0.195可视化时变VAR模型
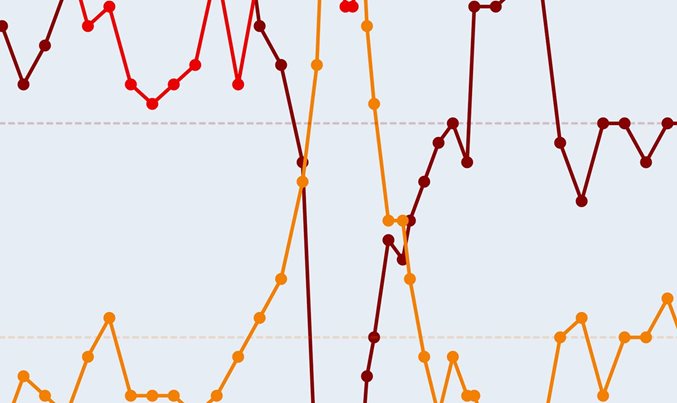
可视化上面估计的一部分随时间变化的VAR参数:
# 两个网络图
# 获取均值图的布局
Q <- qgraph(t(mean_wadj), DoNotPlot=TRUE)
saveRDS(Q$layout, "Tutorials/files/layout_mgm.RDS")
#在选定的固定时间点绘制图形
tpSelect <- c(2, 10, 18)
#
tvvar_obj$edgecolor[, , , ][tvvar_obj$edgecolor[, , , ] == "darkgreen"] <- c("darkblue")
lty_array <- array(1, dim=c(12, 12, 1, 20))
lty_array[tvvar_obj$edgecolor[, , , ] != "darkblue"] <- 2
for(tp in tpSelect) {
qgraph(t(tvvar_obj$wadj[, , 1, tp]),
layout = Q$layout,
edge.color = t(tvvar_obj$edgecolor[, , 1, tp]),
labels = mood_labels,
vsize = 13,
esize = 10,
asize = 10,
mar = rep(5, 4),
minimum = 0,
maximum = .5,
lty = t(lty_array[, , 1, tp]),
pie = pred_obj$tverrors[[tp]][, 3])
}CIs <- apply(res_obj$bootParameters[par_row[1], par_row[2], 1, , ], 1, function(x) {
quantile(x, probs = c(.05, .95))
} )
# 绘图阴影
polygon(x = c(1:20, 20:1), y = c(CIs[1,], rev(CIs[2,])), col=alpha(colour = cols[i], alpha = .3), border=FALSE)
} #
图 显示了上面估计的时变VAR参数的一部分。 顶行显示估计点8,15和18的VAR参数的可视化。蓝色实线箭头表示正关系,红色虚线箭头表示负关系。 箭头的宽度与相应参数的绝对值成比例。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究

