
隶属关系图模型 是一种生成模型,可通过社区联系产生网络。
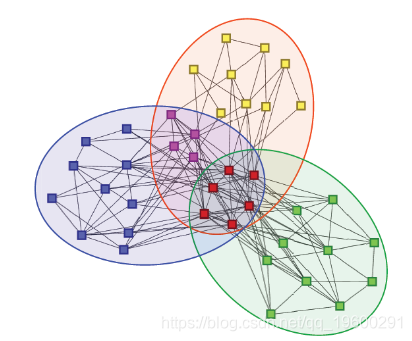
下图描述了一个社区隶属关系图和网络的示例(图1)。
可下载资源
图1.左:社区关系图(圆形节点表示三个社区,正方形节点代表网络的节点),右:AGM生成的网络,社区关系图在左侧
社团检测通常是指将网络中联系紧密的部分找出来,这些部分就称之为社团,那么也可以认为社团内部联系稠密,而社团之间联系稀疏 。显而易见,其中有一个非常重要的点,稠密是如何定义的。不管现在想到的定义是什么,但都包含顶点,边,度,或许还有路径这些字眼,它们有一个共同的特征–网络的结构。所以,社团检测侧重于找到网络中联系紧密的部分,而经常忽略节点的属性(attributes)。
聚类,顾名思义是将属于同一类的目标聚在一起,通常在聚类之前我们是不知道目标有哪些类型,这也是一种典型的无监督学习方法。那么现在来想想我们熟知的聚类方法:kmeans,层次聚类等。其中,最核心的一个部分是计算两个目标之间的距离(或者称为相似度),距离近则它俩是一类,距离远,那就自成一派,或者去找其它距离近的。当然,距离近只是其中一种方法,还有距离远或者怎么样,就看自己的判断。判断标准不是讨论的重点,重点是如何计算距离。欧式距离,曼哈顿距离,余弦相似度等,都是直接用目标特征构成的向量来计算的,没有考虑目标的边,度。所以,聚类侧重于找到一堆属性相似的目标,从而忽略了目标与目标之间的联系。
两者之间的关系已经很清楚啦,社团检测和聚类存在区别,但是呢,两者又是可以结合起来的。比如,我们现在有一个网络,只知道顶点和边的情况,顶点的属性是未知的。那么在做社团检测的时候,可以将顶点与顶点之间的关系构成一个邻接矩阵,通过一系列变化或者就这个邻接矩阵而言,将每个行看作一个属性,每个列看作目标,就可以很轻松的转为聚类,用聚类的方法求解。当邻接矩阵高维时,还可以先做降维处理。所以,两者并没有完全独立,只是考虑的角度不同,可以结合使用。现在社交网络方向有一个很热门的就是用 attributes来辅助进行社团检测,是对传统的社团检测和聚类方法的一种改进,两者优势互补。
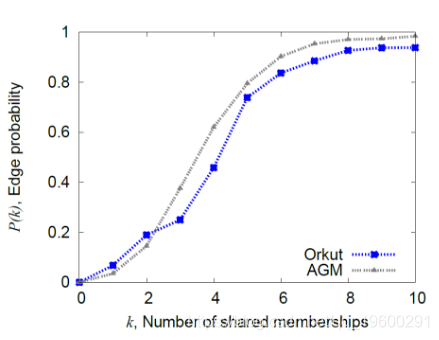
当我们使用拟合于实际网络的 合成网络时,合成网络具有与真实网络非常相似的特征(图2)。

图2.边际概率是Orkut网络中常见社区成员数量的函数 。
进行社区检测
如果用户指定了要检测的社区数量,则 会找到相应的社区数量。如果用户未假定某个概率,则 使用(1 / N ^ 2),其中N是图中的节点数。
例子
我们展示了一些由隶属关系图模型和基础网络检测到的社区的示例。
图创建
如何创建和使用有向图的示例:
# 创建一个网络图
G1 = snap.TNGraph.New()
G1.AddNode(1)
G1.AddNode(5)
G1.AddNode(32)
G1.AddEdge(1,5)
G1.AddEdge(5,1)
G1.AddEdge(5,32)用于保存和加载图形的代码如下所示:
# 使用 Forest Fire 模型创建一个网络图
G3 = snap.GenForestFire(1000, 0.35, 0.35)
#保存
FOut = snap.TFOut("test.graph")
G3.Save(FOut)
FOut.Flush()
FIn = snap.TFIn("test.graph")
G4 = snap.TNGraph.Load(FIn)
# 保存从文本读取
snap.SaveEdgeList(G4, "test.txt", "Save as tab-separated list of edges")
G5 = snap.LoadEdgeList(snap.PNGraph, "test.txt", 0, 1)
- 悲惨世界中的人物网络中的社区。不共享社区的两个节点之间的边缘概率设置为0.01,以检测更紧凑的社区。
- NCAA橄榄球队网络中的社区(通过将两个不共享社区的节点的边缘概率设置为0.1,5个试验的最佳结果。圆形区域表示检测到的社区,节点颜色表示NCAA。

下载资料
我们提供6个数据集,每个数据集都有一个网络和一组真实的社区。真实社区是可以从数据中定义和标识的社区。每个数据集的网页都描述了我们如何识别数据集中的真实社区。
数据集:
| 类型 | 节点数 | 边缘 | 社区 | 描述 | |
|---|---|---|---|---|---|
| 无向,社区 | 3,997,962 | 34,681,189 | 664,414 | LiveJournal在线社交网络 | |
| 无向,社区 | 65,608,366 | 1,806,067,135 | 1,620,991 | Friendster在线社交网络 | |
| 无向,社区 | 3,072,441 | 117,185,083 | 15,301,901 | Orkut在线社交网络 | |
| 无向,社区 | 1,134,890 | 2,987,624 | 16,386 | YouTube在线社交网络 | |
| 无向,社区 | 317,080 | 1,049,866 | 13,477 | DBLP协作网络 | |
| 无向,社区 | 334,863 | 925,872 | 271,570 | 亚马逊产品网络 |
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据

