
从网站提取数据的方法称为网络抓取。
Web抓取的目的是从任何网站获取数据,从而节省了收集数据/信息的大量体力劳动。例如,您可以从IMDB网站收集电影的所有评论。之后,您可以执行文本分析,以从收集到的大量评论中获得有关电影的见解。
可下载资源
抓取开始的第一页
如果我们更改地址空间上的页码,您将能够看到从0到15的各个页面。我们将开始抓取第一页https://www.opencodez.com/page/0。
1.Beautiful Soup的简介
简单来说,Beautiful Soup是Python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
废话不多说,我们来试一下吧~
2.Beautiful Soup安装
参考上一篇文章利用Pycharm安装
另一个可供选择的解析器是纯Python实现的html5lib , html5lib的解析方Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则Python会使用Python默认的解析器,lxml解析器更加强大,速度更快,推荐安装。
3.开启BeautifulSoup之旅
中文版官方文档https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
第一步,我们将向URL发送请求,并将其响应存储在名为response的变量中。这将发送所有Web代码作为响应。
url= https://www.opencodez.com/page/0
response= requests.get(url)然后,我们必须使用html.parser解析HTML内容。
soup = BeautifulSoup(response.content,"html.parser")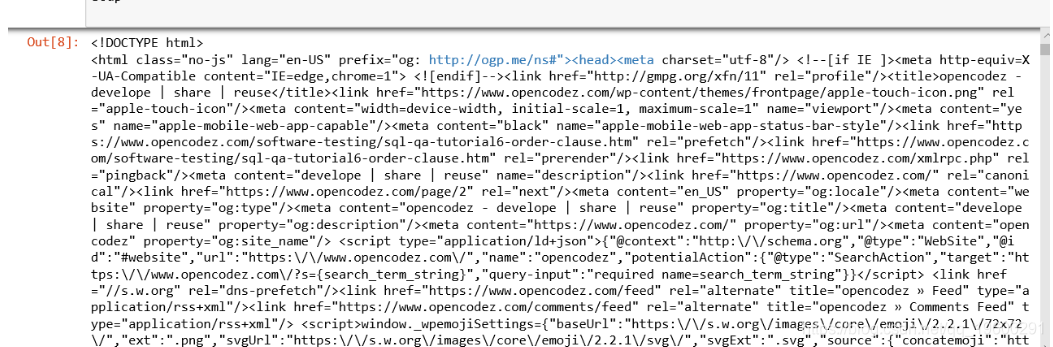
我们将使用整理功能对其进行组织。
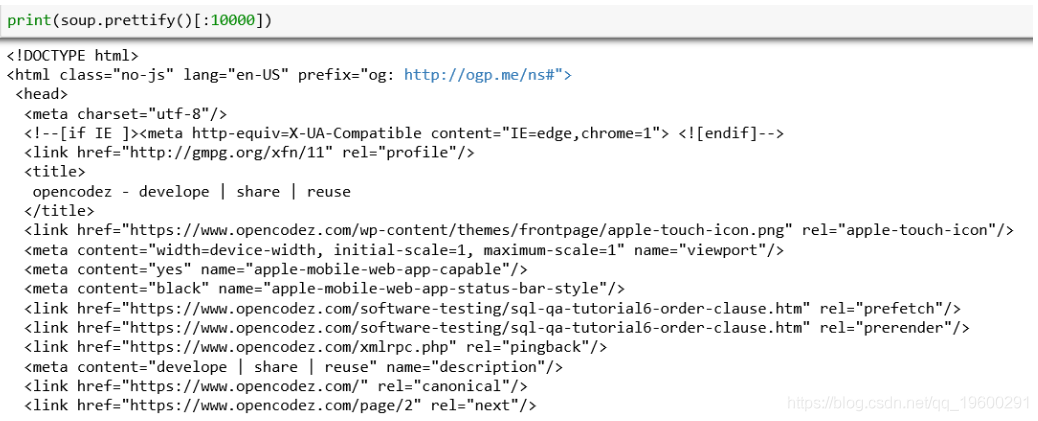
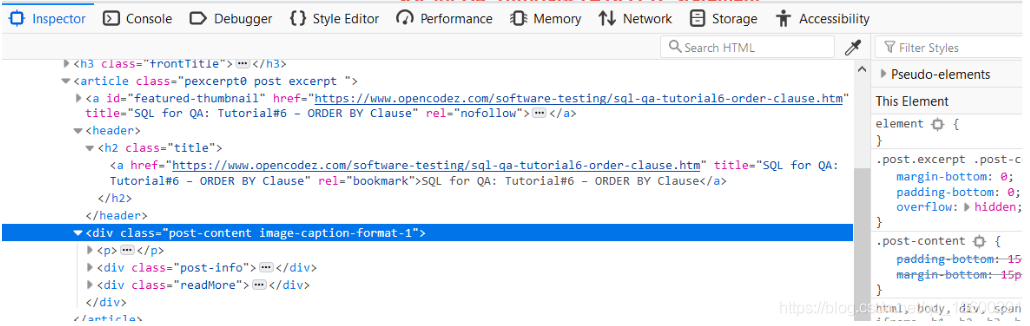
让我们观察必须提取详细信息的页面部分。如果我们通过前面介绍的右键单击方法检查其元素,则会看到href的详细信息以及任何文章的标题都位于标签h2中,该标签带有名为title的类。
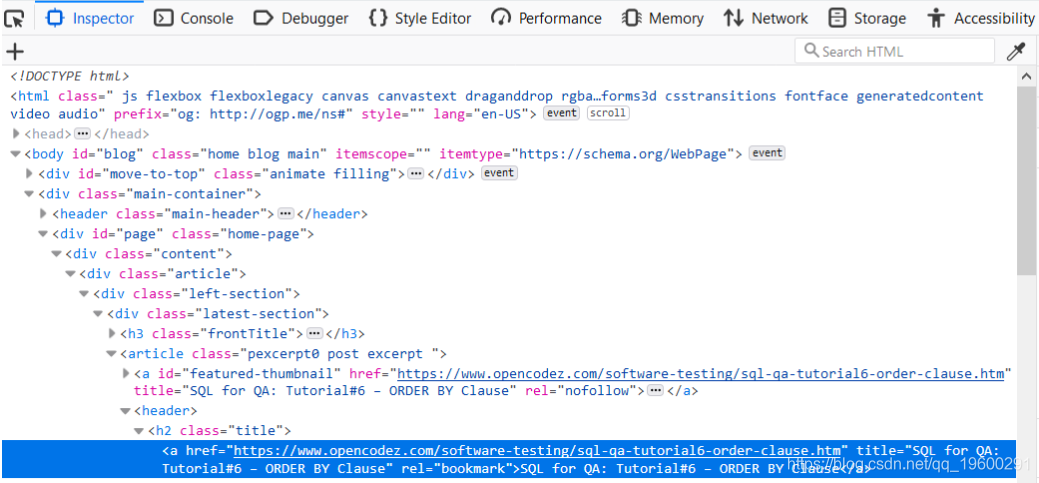
文章标题及其链接的HTML代码在上方的蓝色框中。
我们将通过以下命令将其全部拉出。
soup_title= soup.findAll("h2",{"class":"title"})
len(soup_title)将列出12个值的列表。从这些文件中,我们将使用以下命令提取所有已发布文章的标题和hrefs。
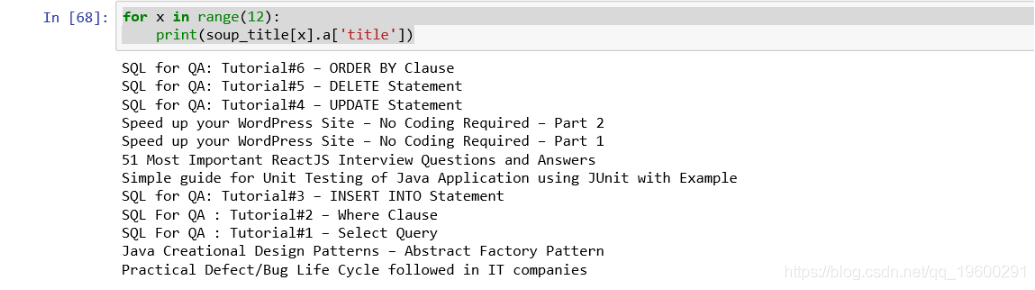
for x in range(12):
print(soup_title[x].a['href'])
for x in range(12):
print(soup_title[x].a['title'])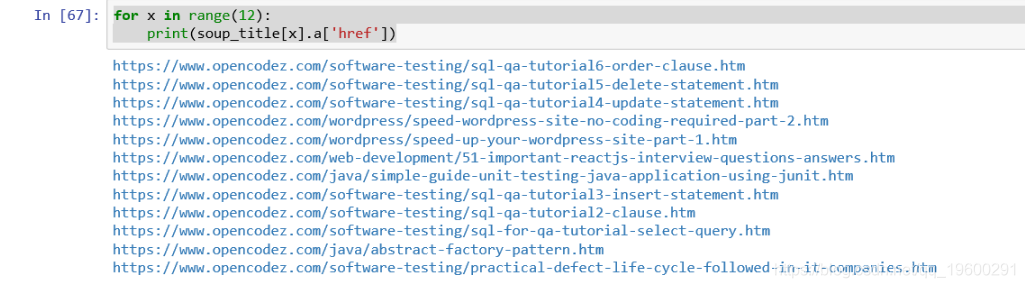
为了收集帖子,作者和日期的简短描述,我们需要针对包含名为“ post-content image-caption-format-1”的类的div标签。
我们抓取的数据怎么办?
可以执行多种操作来探索excel表中收集的数据。首先是wordcloud生成,我们将介绍的另一个是NLP之下的主题建模。

词云
1)什么是词云:
这是一种视觉表示,突出显示了我们从文本中删除了最不重要的常规英语单词(称为停用词)(包括其他字母数字字母)后,在文本数据语料库中出现的高频单词。
2)使用词云:
这是一种有趣的方式,可以查看文本数据并立即获得有用的见解,而无需阅读整个文本。
3)所需的工具和知识:
python
4)摘要:
在本文中,我们将excel数据重新视为输入数据。
5)代码

随时关注您喜欢的主题
6)代码中使用的一些术语的解释:
停用词是用于句子创建的通用词。这些词通常不会给句子增加任何价值,也不会帮助我们获得任何见识。例如A,The,This,That,Who等。
7)词云输出

2)使用主题建模:
它的用途是识别特定文本/文档中所有可用的主题样式。
3)所需的工具和知识:
- python
- Gensim
- NLTK
4)代码摘要:
我们将合并用于主题建模的LDA(潜在Dirichlet),以生成主题并将其打印以查看输出。
5)代码

6)读取输出:
我们可以更改参数中的值以获取任意数量的主题或每个主题中要显示的单词数。在这里,我们想要5个主题,每个主题中包含7个单词。我们可以看到,这些主题与java,salesforce,单元测试,微服务有关。如果我们增加话题数,例如10个,那么我们也可以发现现有话题的其他形式。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据
Python用LoRA微调Gemma4视觉模型用于放射学医学影像问答|附AI智能体、代码和数据 Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据
Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据

