谱聚类是一种将数据的相似矩阵的谱应用于降维的技术。
它是有用且易于实现的聚类方法。
Scikit-learn API 提供了 谱聚类来实现 Python 中的谱聚类方法。
给你若干个博客,让你将它们分成K类,你会怎样做?想必有很多方法,本文要介绍的是其中的一种——谱聚类。
聚类的直观解释是根据样本间相似度,将它们分成不同组。谱聚类的思想是将样本看作顶点,样本间的相似度看作带权的边,从而将聚类问题转为图分割问题:找到一种图分割的方法使得连接不同组的边的权重尽可能低(这意味着组间相似度要尽可能低),组内的边的权重尽可能高(这意味着组内相似度要尽可能高)。将上面的例子代入就是将每一个博客当作图上的一个顶点,然后根据相似度将这些顶点连起来,最后进行分割。分割后还连在一起的顶点就是同一类了。一共有6个顶点(博客),顶点之间的连线表示两个顶点的相似度,现在要将这图分成两半(两个类),要怎样分割(去掉哪边条)?根据谱聚类的思想,应该去掉的边是用虚线表示的那条。最后,剩下的两半就分别对应两个类了。
根据这个思想,可以得到unnormalized谱聚类和normalized谱聚类,由于前者比后者简单,所以本文介绍unnormalized谱聚类的几个步骤(假设要分K个类):
(a)建立similarity graph,并用 W 表示similarity graph的带权邻接矩阵
(b)计算unnormalized graph Laplacian matrix L(L = D – W, 其中D是degree matrix)
(c)计算L的前K个最小的特征向量
(d)把这k个特征向量排列在一起组成一个N*k的矩阵,将其中每一行看作k维空间中的一个向量,并使用 K-means 算法进行聚类
谱聚类 将聚类应用于归一化拉普拉斯算子的投影。
在本教程中,我们将简要了解如何在 Python 中使用 谱聚类 对数据进行聚类和可视化。教程涵盖:
- 准备数据
- 使用 谱聚类 和可视化进行聚类
- 源代码
我们将首先导入所需的库和函数。
from numpy import random
准备数据
我们将通过使用 make_blob() 函数生成一个简单的数据集并在图中将其可视化。
random.seed make_blobs plt plt.show
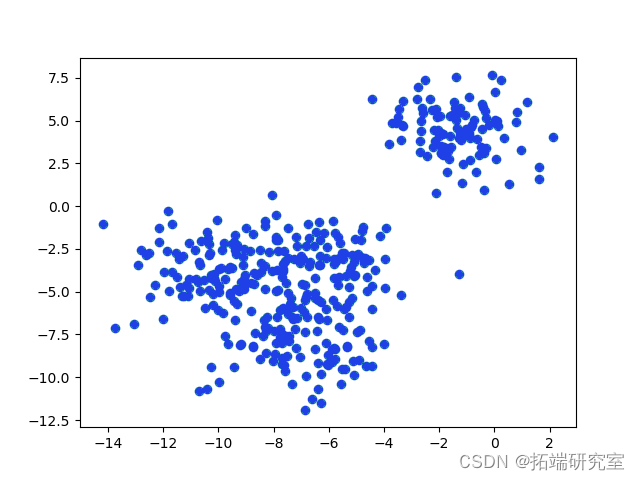
这是一个易于理解的数据,因此我们将使用谱聚类方法对其进行聚类。
谱聚类 和可视化
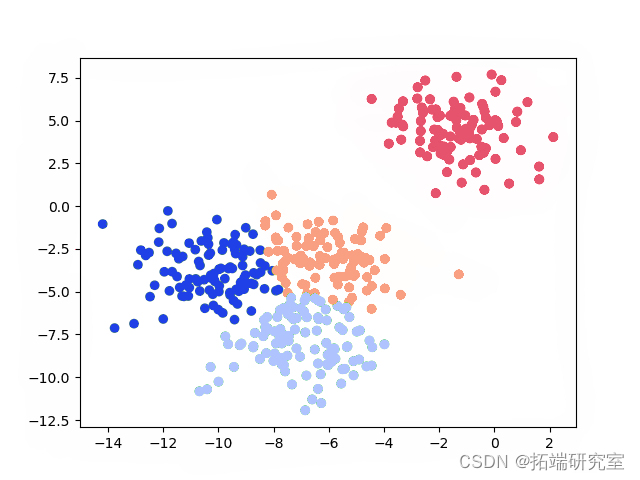
我们将使用 谱聚类定义模型,然后我们将它拟合到 x 数据上。谱聚类需要聚类的数量,因此将 4 设置为 n_cluster 参数。您可以检查类的参数并根据您的分析和目标数据更改它们。
SptlCltg.fit(x) SelCg( n_clusters=4)
接下来,我们将在图中可视化聚类数据。为了按颜色分隔聚类,我们将从拟合模型中提取标签数据。
labels = sc.labels_ plt.scatter(x\[:,0\], x\[:,1\], c=labels) plt.show()

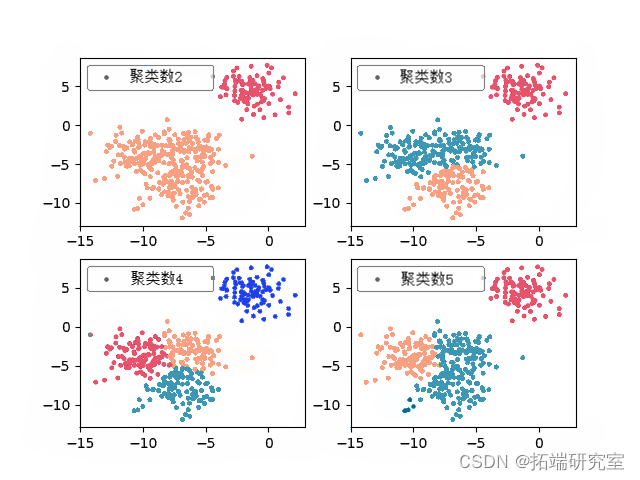
我们还可以通过改变簇数来检查聚类结果。
plt f.add_subplot for i in range: sc = Serurg.fit f.add_subplot plt.scatter plt.legen plt.show
随时关注您喜欢的主题
在本教程中,我们简要了解了如何使用 Python 中对数据进行聚类和可视化。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化
Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化 Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享
Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享 专题|R语言、SPSS电信客户流失预测实例汇总:KNN、决策树、聚类、RFM分群、挽留策略研究
专题|R语言、SPSS电信客户流失预测实例汇总:KNN、决策树、聚类、RFM分群、挽留策略研究
