
使用潜在Dirichlet分配(LDA)和t-SNE中的可视化进行主题建模。
本文中的代码片段仅供您在阅读时更好地理解。有关完整的工作代码,请参阅下载资源。
可下载资源
我们将首先介绍主题建模和t-SNE,然后将这些技术应用于两个数据集:20个新闻组和推文。
什么是主题建模?
主题模型是一套算法/统计模型,可以揭示文档集中的隐藏主题。文档通常涉及不同比例的多个主题,特别是在跨学科文档中(例如,60%关于生物学,25%关于统计学,15%关于计算机科学的生物信息学文章)。主题模型在数学框架中检查和发现主题可能是什么以及每个文档的主题可能性。
1. 简介
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来文本分类。
LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
2. 先验知识
LDA 模型涉及很多数学知识,这也许是LDA晦涩难懂的主要原因。本小节主要介绍LDA中涉及的数学知识。数学功底比较好的同学可以直接跳过本小节。
LDA涉及到的先验知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibs Sampling、EM算法等。限于篇幅,本文仅会有的放矢的介绍部分概念,不会每个概念都仔细介绍,亦不会涉及到每个概念的数学公式推导。如果每个概念都详细介绍,估计都可以写一本百页的书了。如果你对LDA的理解能达到如数家珍、信手拈来的程度,那么恭喜你已经掌握了从事机器学习方面的扎实数学基础。想进一步了解底层的数学公式推导过程,可以参考《数学全书》等资料。
2.1 词袋模型
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。有兴趣的读者可以参考其他书籍。
2.2 二项分布
二项分布是N重伯努利分布,即为X ~ B(n, p). 概率密度公式为:
2.3 多项分布
多项分布,是二项分布扩展到多维的情况. 多项分布是指单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3…,k).概率密度函数为:
2.4 Gamma函数
Gamma函数的定义:
分部积分后,可以发现Gamma函数如有这样的性质:
Gamma函数可以看成是阶乘在实数集上的延拓,具有如下性质:
2.5 Beta分布
Beta分布的定义:对于参数\alpha > 0, \beta > 0, 取值范围为[0, 1]的随机变量x的概率密度函数为:
(1)
其中,
(2)
2.6 共轭先验分布
在贝叶斯概率理论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
(3)
Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
共轭的意思是,以Beta分布和二项式分布为例,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta分布的形式,这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后续分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释。
2.7 Dirichlet分布
Dirichlet的概率密度函数为:
(4)
其中,
(5)
根据Beta分布、二项分布、Dirichlet分布、多项式分布的公式,我们可以验证上一小节中的结论 — Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
2.8 Beta / Dirichlet 分布的一个性质
如果 ,则
(6)
(7)
(8)
上式右边的积分对应到概率分布 , 对于这个分布,有
把上式带入E(p)的计算式,得到
(9)
(10)
(11)
这说明,对于Beta分布的随机变量,其均值可以用 来估计。Dirichlet分布也有类似的结论,如果
, 同样可以证明:
(12)
这两个结论非常重要,后面的LDA数学推导过程会使用这个结论。
2.9 MCMC 和 Gibbs Sampling
在现实应用中,我们很多时候很难精确求出精确的概率分布,常常采用近似推断方法。近似推断方法大致可分为两大类:第一类是采样(Sampling), 通过使用随机化方法完成近似;第二类是使用确定性近似完成近似推断,典型代表为变分推断(variational inference).
在很多任务中,我们关心某些概率分布并非因为对这些概率分布本身感兴趣,而是要基于他们计算某些期望,并且还可能进一步基于这些期望做出决策。采样法正式基于这个思路。具体来说,假定我们的目标是计算函数f(x)在概率密度函数p(x)下的期望
(13)
则可根据p(x)抽取一组样本 ,然后计算f(x)在这些样本上的均值
(14)
以此来近似目标期望E[f]。若样本 独立,基于大数定律,这种通过大量采样的办法就能获得较高的近似精度。可是,问题的关键是如何采样?对概率图模型来说,就是如何高效地基于图模型所描述的概率分布来获取样本。概率图模型中最常用的采样技术是马尔可夫链脸蒙特卡罗(Markov chain Monte Carlo, MCMC). 给定连续变量
的概率密度函数p(x), x在区间A中的概率可计算为
(15)
若有函数 , 则可计算f(x)的期望
(16)
若x不是单变量而是一个高维多元变量x, 且服从一个非常复杂的分布,则对上式求积分通常很困难。为此,MCMC先构造出服从p分布的独立同分布随机变量 , 再得到上式的无偏估计
(17)
然而,若概率密度函数p(x)很复杂,则构造服从p分布的独立同分布样本也很困难。MCMC方法的关键在于通过构造“平稳分布为p的马尔可夫链”来产生样本:若马尔科夫链运行时间足够长,即收敛到平稳状态,则此时产出的样本X近似服从分布p.如何判断马尔科夫链到达平稳状态呢?假定平稳马尔科夫链T的状态转移概率(即从状态X转移到状态 的概率)为
, t时刻状态的分布为p(x^t), 则若在某个时刻马尔科夫链满足平稳条件
(18)
则p(x)是马尔科夫链的平稳分布,且马尔科夫链在满足该条件时已收敛到平稳条件。也就是说,MCMC方法先设法构造一条马尔科夫链,使其收敛至平稳分布恰为待估计参数的后验分布,然后通过这条马尔科夫链来产生符合后验分布的样本,并基于这些样本来进行估计。这里马尔科夫链转移概率的构造至关重要,不同的构造方法将产生不同的MCMC算法。
Metropolis-Hastings(简称MH)算法是MCMC的重要代表。它基于“拒绝采样”(reject sampling)来逼近平稳分布p。算法如下:
-
输入:先验概率
-
过程:
-
1. 初始化x^0;
-
2. for t = 1, 2, … do
-
3. 根据
采样出候选样本
-
4. 根据均匀分布从(0, 1)范围内采样出阈值u;
-
5. if u
-
6.
-
7. else
-
8.
-
9. end if
-
10. enf for
-
11. return
-
输出:采样出的一个样本序列
于是, 为了达到平稳状态,只需将接受率设置为
(19)
吉布斯采样(Gibbs sampling)有时被视为MH算法的特例,它也使用马尔科夫链读取样本,而该马尔科夫链的平稳分布也是采用采样的目标分布p(x).具体来说,假定 , 目标分布为p(x), 在初始化x的取值后,通过循环执行以下步骤来完成采样:
-
1. 随机或以某个次序选取某变量
;
-
2. 根据x中除
, 其中
;
-
3. 根
3. 文本建模
一篇文档,可以看成是一组有序的词的序列 . 从统计学角度来看,文档的生成可以看成是上帝抛掷骰子生成的结果,每一次抛掷骰子都生成一个词汇,抛掷N词生成一篇文档。在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,这会涉及到两个最核心的问题:
-
上帝都有什么样的骰子;
-
上帝是如何抛掷这些骰子的;
第一个问题就是表示模型中都有哪些参数,骰子的每一个面的概率都对应于模型中的参数;第二个问题就表示游戏规则是什么,上帝可能有各种不同类型的骰子,上帝可以按照一定的规则抛掷这些骰子从而产生词序列。
3.1 Unigram Model
在Unigram Model中,我们采用词袋模型,假设了文档之间相互独立,文档中的词汇之间相互独立。假设我们的词典中一共有 V 个词 ,那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。
-
1. 上帝只有一个骰子,这个骰子有V面,每个面对应一个词,各个面的概率不一;
-
2. 每抛掷一次骰子,抛出的面就对应的产生一个词;如果一篇文档中N个词,就独立的抛掷n次骰子产生n个词;
3.1.1 频率派视角
对于一个骰子,记各个面的概率为 , 每生成一个词汇都可以看做一次多项式分布,记为
。一篇文档
, 其生成概率是
文档之间,我们认为是独立的,对于一个语料库,其概率为:
假设语料中总的词频是N,记每个词 的频率为
, 那么
, 服从多项式分布
整个语料库的概率为
此时,我们需要估计模型中的参数 ,也就是词汇骰子中每个面的概率是多大,按照频率派的观点,使用极大似然估计最大化p(W), 于是参数
的估计值为
3.1.2 贝叶斯派视角
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子 不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的:
-
1. 现有一个装有无穷多个骰子的坛子,里面装有各式各样的骰子,每个骰子有V个面;
-
2. 现从坛子中抽取一个骰子出来,然后使用这个骰子不断抛掷,直到产生语料库中的所有词汇
坛子中的骰子无限多,有些类型的骰子数量多,有些少。从概率分布角度看,坛子里面的骰子 服从一个概率分布
, 这个分布称为参数
的先验分布。在此视角下,我们并不知道到底用了哪个骰子
,每个骰子都可能被使用,其概率由先验分布
来决定。对每个具体的骰子,由该骰子产生语料库的概率为
, 故产生语料库的概率就是对每一个骰子
上产生语料库进行积分求和
先验概率有很多选择,但我们注意到 . 我们知道多项式分布和狄利克雷分布是共轭分布,因此一个比较好的选择是采用狄利克雷分布
此处 ,就是归一化因子
, 即
由多项式分布和狄利克雷分布是共轭分布,可得:
(20)
此时,我们如何估计参数 呢?根据上式,我们已经知道了其后验分布,所以合理的方式是使用后验分布的极大值点,或者是参数在后验分布下的平均值。这里,我们取平均值作为参数的估计值。根据第二小节Dirichlet分布中的内容,可以得到:
(21)
对于每一个 , 我们使用下面的式子进行估计
(22)
在 Dirichlet 分布中的物理意义是事件的先验的伪计数,上式表达的是:每个参数的估计值是其对应事件的先验的伪计数和数据中的计数的和在整体计数中的比例。由此,我们可以计算出产生语料库的概率为:
(23)
(24)
(25)
(26)
(27)
3.2 PLSA模型
Unigram Model模型中,没有考虑主题词这个概念。我们人写文章时,写的文章都是关于某一个主题的,不是满天胡乱的写,比如一个财经记者写一篇报道,那么这篇文章大部分都是关于财经主题的,当然,也有很少一部分词汇会涉及到其他主题。所以,PLSA认为生成一篇文档的生成过程如下:
-
1. 现有两种类型的骰子,一种是doc-topic骰子,每个doc-topic骰子有K个面,每个面一个topic的编号;一种是topic-word骰子,每个topic-word骰子有V个面,每个面对应一个词;
-
2. 现有K个topic-word骰子,每个骰子有一个编号,编号从1到K;
-
3. 生成每篇文档之前,先为这篇文章制造一个特定的doc-topic骰子,重复如下过程生成文档中的词:
-
3.1 投掷这个doc-topic骰子,得到一个topic编号z;
-
3.2 选择K个topic-word骰子中编号为z的那个,投掷这个骰子,得到一个词;
PLSA中,也是采用词袋模型,文档和文档之间是独立可交换的,同一个文档内的词也是独立可交换的。K 个topic-word 骰子,记为 ; 对于包含M篇文档的语料
中的每篇文档
,都会有一个特定的doc-topic骰子
,所有对应的骰子记为
。为了方便,我们假设每个词
都有一个编号,对应到topic-word 骰子的面。于是在 PLSA 这个模型中,第m篇文档
中的每个词的生成概率为
(28)
(29)
一篇文档的生成概率为:
(30)
(31)
由于文档之间相互独立,很容易写出整个语料的生成概率。求解PLSA 可以使用著名的 EM 算法进行求得局部最优解,有兴趣的同学参考 Hoffman 的原始论文,或者李航的《统计学习方法》,此处略去不讲。
3.3 LDA 模型
3.3.1 PLSA 和 LDA 的区别
首先,我们来看看PLSA和LDA生成文档的方式。在PLSA中,生成文档的方式如下:
-
1. 按照概率
选择一篇文档
-
2. 根据选择的文档
,从从主题分布中按照概率
选择一个隐含的主题类别
-
3. 根据选择的主题
, 从词分布中按照概率
选择一个词
LDA 中,生成文档的过程如下:
-
1. 按照先验概率
-
2. 从Dirichlet分布
中取样生成文档
,主题分布
-
3. 从主题的多项式分布
-
4. 从Dirichlet分布
中取样生成主题
对应的词语分布
,词语分布
-
5. 从词语的多项式分布
可以看出,LDA 在 PLSA 的基础上,为主题分布和词分布分别加了两个 Dirichlet 先验。
我们来看一个例子,如图所示:
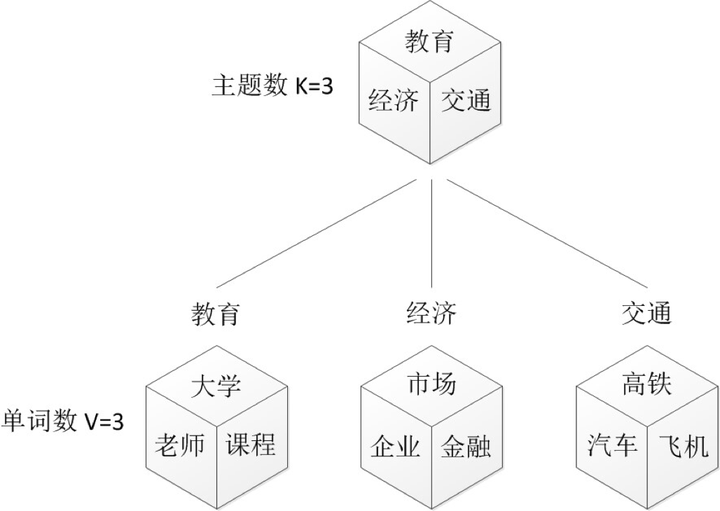
上图中有三个主题,在PLSA中,我们会以固定的概率来抽取一个主题词,比如0.5的概率抽取教育这个主题词,然后根据抽取出来的主题词,找其对应的词分布,再根据词分布,抽取一个词汇。由此,可以看出PLSA中,主题分布和词分布都是唯一确定的。但是,在LDA中,主题分布和词分布是不确定的,LDA的作者们采用的是贝叶斯派的思想,认为它们应该服从一个分布,主题分布和词分布都是多项式分布,因为多项式分布和狄利克雷分布是共轭结构,在LDA中主题分布和词分布使用了Dirichlet分布作为它们的共轭先验分布。所以,也就有了一句广为流传的话 — LDA 就是 PLSA 的贝叶斯化版本。下面两张图片很好的体现了两者的区别:

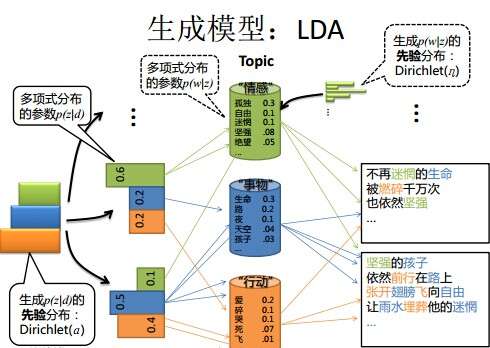
在PLSA和LDA的两篇论文中,使用了下面的图片来解释模型,它们也很好的对比了PLSA和LDA的不同之处。
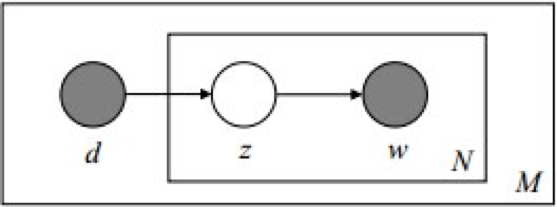

3.3.2 LDA 解析一
现在我们来详细讲解论文中的LDA模型,即上图。
, 这个过程表示在生成第m篇文档的时候,先从抽取了一个doc-topic骰子
, 然后投掷这个骰子生成了文档中第n个词的topic编号
;
, 这个过程表示,从K个topic-word骰子
中,挑选编号为
的骰子进行投掷,然后生成词汇
;
在LDA中,也是采用词袋模型,M篇文档会对应M个独立Dirichlet-Multinomial共轭结构;K个topic会对应K个独立的Dirichlet-Multinomial共轭结构。
3.3.3 LDA 解析二
上面的LDA的处理过程是一篇文档一篇文档的过程来处理,并不是实际的处理过程。文档中每个词的生成都要抛两次骰子,第一次抛一个doc-topic骰子得到 topic, 第二次抛一个topic-word骰子得到 word,每次生成每篇文档中的一个词的时候这两次抛骰子的动作是紧邻轮换进行的。如果语料中一共有 N 个词,则上帝一共要抛 2N次骰子,轮换的抛doc-topic骰子和 topic-word骰子。但实际上有一些抛骰子的顺序是可以交换的,我们可以等价的调整2N次抛骰子的次序:前N次只抛doc-topic骰子得到语料中所有词的 topics,然后基于得到的每个词的 topic 编号,后N次只抛topic-word骰子生成 N 个word。此时,可以得到:
(32)
(33)
3.3.4 使用Gibbs Sampling进行采样
根据上一小节中的联合概率分布 , 我们可以使用Gibbs Sampling对其进行采样。
语料库 中的第i个词我们记为
, 其中i=(m,n)是一个二维下标,对应于第m篇文档的第n个词,用
表示去除下标为i的词。根据第二小节中的Gibbs Sampling 算法,我们需要求任一个坐标轴 i 对应的条件分布
。假设已经观测到的词
, 则由贝叶斯法则,我们容易得到:
(34)
由于 只涉及到第 m 篇文档和第k个 topic,所以上式的条件概率计算中, 实际上也只会涉及到与之相关的两个Dirichlet-Multinomial 共轭结构,其它的 M+K−2 个 Dirichlet-Multinomial 共轭结构和
是独立的。去掉一个词汇,并不会改变M + K 个Dirichlet-Multinomial共轭结构,只是某些地方的计数减少而已。于是有:
(35)
(36)
下面进行本篇文章最终的核心数学公式推导:
(37)
(38)
(39)
(40)
(41)
(42)
(43)
(44)
最终得到的 就是对应的两个 Dirichlet 后验分布在贝叶斯框架下的参数估计。借助于前面介绍的Dirichlet 参数估计的公式 ,有:
(45)
(46)
最终,我们得到LDA 模型的 Gibbs Sampling 公式为:
(47)
3.3.5 LDA Training
根据上一小节中的公式,我们的目标有两个:
-
1. 估计模型中的参数
和
;
-
2. 对于新来的一篇文档,我们能够计算这篇文档的 topic 分布
。
训练的过程:
-
1. 对语料库中的每篇文档中的每个词汇
,随机的赋予一个topic编号z
-
2. 重新扫描语料库,对每个词
-
3. 重复步骤2,直到Gibbs Sampling收敛
-
4. 统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型;
根据这个topic-word频率矩阵,我们可以计算每一个p(word|topic)概率,从而算出模型参数 , 这就是那 K 个 topic-word 骰子。而语料库中的文档对应的骰子参数
在以上训练过程中也是可以计算出来的,只要在 Gibbs Sampling 收敛之后,统计每篇文档中的 topic 的频率分布,我们就可以计算每一个 p(topic|doc) 概率,于是就可以计算出每一个
。由于参数
是和训练语料中的每篇文档相关的,对于我们理解新的文档并无用处,所以工程上最终存储 LDA 模型时候一般没有必要保留。通常,在 LDA 模型训练的过程中,我们是取 Gibbs Sampling 收敛之后的 n 个迭代的结果进行平均来做参数估计,这样模型质量更高。
3.3.6 LDA Inference
有了 LDA 的模型,对于新来的文档 doc, 我们只要认为 Gibbs Sampling 公式中的 部分是稳定不变的,是由训练语料得到的模型提供的,所以采样过程中我们只要估计该文档的 topic 分布
就好了. 具体算法如下:
-
1. 对当前文档中的每个单词
-
2. 使用Gibbs Sampling公式,对每个词
-
3. 重复以上过程,知道Gibbs Sampling收敛;
-
4. 统计文档中的topic分布,该分布就是
4 Tips
懂 LDA 的面试官通常会询问求职者,LDA 中主题数目如何确定?
在 LDA 中,主题的数目没有一个固定的最优解。模型训练时,需要事先设置主题数,训练人员需要根据训练出来的结果,手动调参,有优化主题数目,进而优化文本分类结果。
5 后记
LDA 有非常广泛的应用,深层次的懂 LDA 对模型的调优,乃至提出新的模型 以及AI技能的进阶有巨大帮助。只是了解 LDA 能用来干什么,只能忽悠小白。
百度开源了其 LDA 模型,有兴趣的读者可以阅读:https://github.com/baidu/Familia/wiki
References
[1]: Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
[2]: Hofmann, T. (1999). Probabilistic latent semantic indexing. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval (pp. 50-57). ACM.
[3]: Li, F., Huang, M., & Zhu, X. (2010). Sentiment Analysis with Global Topics and Local Dependency. In AAAI (Vol. 10, pp. 1371-1376).
[4]: Medhat, W., Hassan, A., & Korashy, H. (2014). Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal, 5(4), 1093-1113.
[5]: Rick, Jin. (2014). Retrieved from http://www.flickering.cn/数学之美/2014/06/【lda数学八卦】神奇的gamma函数/.
[6]: 通俗理解LDA主题模型. (2014). Retrieved fromhttp://blog.csdn.net/v_july_v/article/details/41209515.
[7]: 志华, 周. (2017). 机器学习. 北京, 北京: 清华大学出版社.
[8]: Goodfellow, I., Bengio, Y., & Courville, A. (2017). Deep learning. Cambridge, MA: The MIT Press.
[9]: 航, 李. (2016). 统计学习方法. 北京, 北京: 清华大学出版社.
热门话题建模算法包括潜在语义分析(LSA),分层Dirichlet过程(HDP)和潜在Dirichlet分配(LDA),其中LDA在实践中已经显示出很好的结果,因此被广泛采用。这篇文章将使用LDA进行主题建模。
T-SNE
t-SNE或t分布随机邻域嵌入是用于高维数据可视化的维数降低算法。
这是一个在三维空间中可视化的示例:
t-SNE是不确定的,其结果取决于数据批次。换句话说,相对于批次中的其他数据点,相同的高维数据点可以被转换成不同批次的不同2-D或3-D向量。
可以使用各种语言实现t-SNE,但速度可能会有所不同。例如,我对C ++和Python以及Python sklearn版本进行了比较,发现前者在矩阵转换速度方面通常快3倍。
环境
15-inch MacBook Pro, macOS Sierra
2.2 GHz Intel Core i7 processor
16 GB 1600 MHz DDR3 memory
1.将10,000 x 50矩阵转换为10,000 x 2
C ++和Python
real 1m2.662s
user 1m0.575s
sys 0m1.929s
Python sklearn
real 3m29.883s
user 2m22.748s
sys 1m7.010s
2.将20,000 x 50矩阵转换为20,000 x 2
C ++和Python
real 2m40.250s
user 2m32.400s
sys 0m6.420s
Python sklearn
real 6m54.163s
user 4m17.524s
sys 2m31.693s
3.将1,000,000 x 25矩阵转换为1,000,000 x 2
C ++和Python
real 224m55.747s
user 216m21.606s
sys 8m21.412s
Python sklearn
out of memory… 🙁
t-SNE的作者说,他们“已经将这项技术应用于数据集,最多有3000万个例子”(尽管他没有指定数据和运行时的维度)。如果你有一个更大的数据集,你可以扩大你的硬件,调整参数(例如,sklearn的t-SNE中的angle参数),或尝试替代(如LargeVis,其作者声称“与tSNE比较,LargeVis显着降低了图形构建步骤的计算成本“。我还没有测试过它。
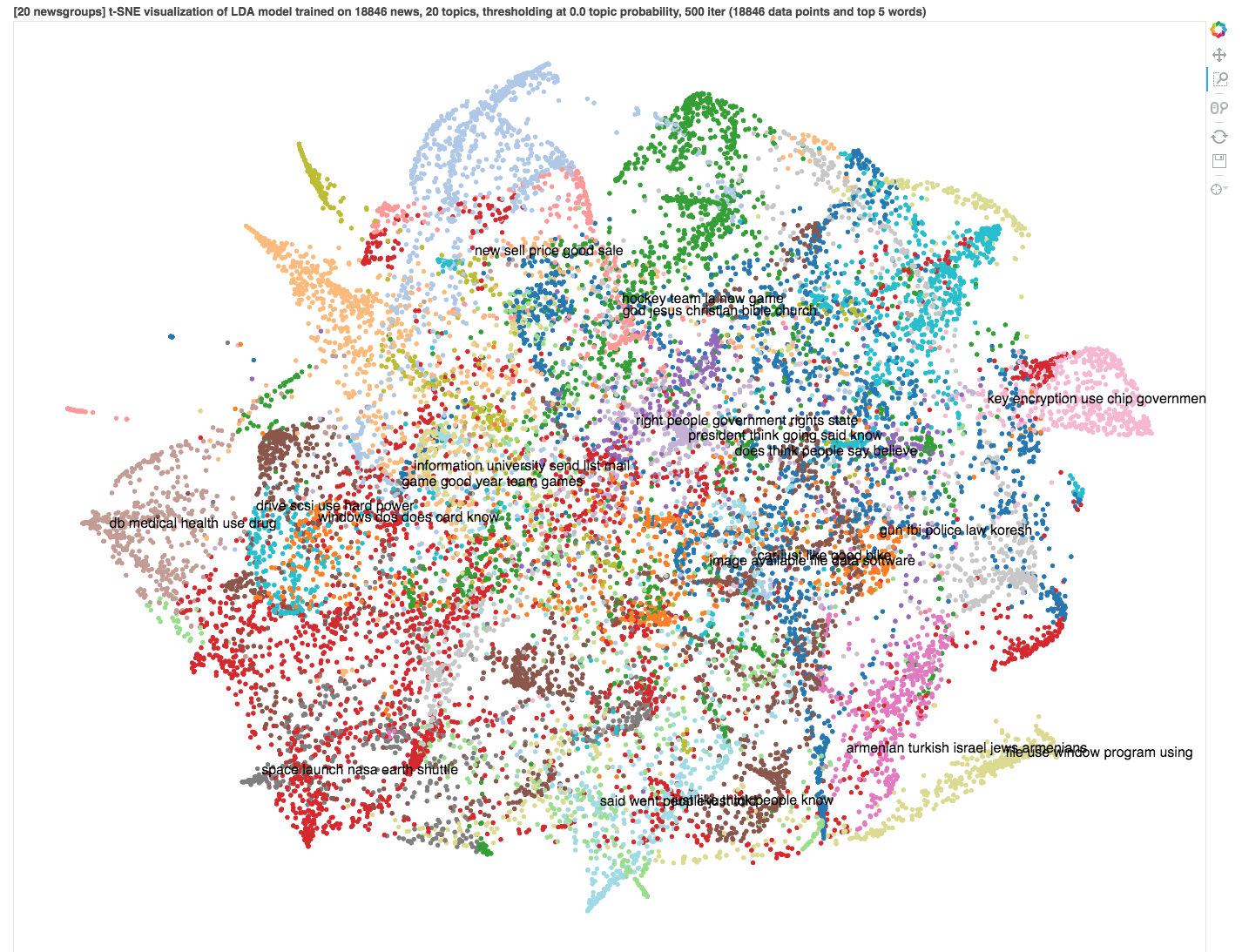
20个新闻组的例子
在本节中,我们将在20个新闻组数据集上应用LDA算法,以发现每个文档中的基础主题,并使用t-SNE将它们显示为组。
获取数据
sklearn具有检索和过滤20个新闻组数据的功能:
from sklearn.datasets import fetch_20newsgroups
# 筛选文档部分
remove = ('headers', 'footers', 'quotes')
# 划分训练和测试数据
newsgroups_train = fetch_20newsgroups(subset ='train', remove =remove)
newsgroups_test = fetch_20newsgroups(subset ='test', remove =remove)
# 清理文本转换小写
news = [' ' .join(filter(unicode .isalpha, raw .lower() .split())) for raw in
newsgroups_train .data + newsgroups_test .data]LDA模型
在我们获得清理后的数据后,我们可以进行矢量化并训练LDA模型:
import lda
from sklearn.feature_extraction.text import CountVectorizer
n_topics = 20 # #主题数
n_iter = 500 # 迭代次数
#向量化,删除短词
cvectorizer = CountVectorizer(min_df =5, stop_words ='english')
cvz = cvectorizer .fit_transform(news)
#训练LDA模型
lda_model = lda .LDA(n_topics =n_topics, n_iter =n_iter)
X_topics = lda_model .fit_transform(cvz)其中X_topics是18,846(num_news)乘20(n_topics)矩阵。注意,我们在这里有一个很好的概率解释:每一行是属于某个主题的这个新闻的概率分布(由我们的LDA模型学习)(例如,X_topics[0][0]代表属于主题1的第一个新闻的可能性)。
用t-SNE减少到2-D
我们有一个学习过的LDA模型。但我们无法直观地检查我们的模型。使用t-sne
from sklearn.manifold import TSNE
# t-SNE 模型
#pca初始化通常会带来更好的结果tsne_model = TSNE(n_components =2, verbose =1, random_state =0, angle =.99, init='pca')
# 20-D -> 2-D
tsne_lda = tsne_model .fit_transform(X_topics)

可视化组及其关键字
现在,我们已准备好使用流行的Python可视化库来可视化新闻组和关键字。
首先我们做一些设置工作(导入类和函数,设置参数等):
import numpy as np
import bokeh.plotting as bp
from bokeh.plotting import save
from bokeh.models import HoverTool
n_top_words = 5 # 我们显示的关键字数量
# 20 颜色
colormap = np .array([
"#1f77b4", "#aec7e8", "#ff7f0e", "#ffbb78", "#2ca02c",
"#98df8a", "#d62728", "#ff9896", "#9467bd", "#c5b0d5",
"#8c564b", "#c49c94", "#e377c2", "#f7b6d2", "#7f7f7f",
"#c7c7c7", "#bcbd22", "#dbdb8d", "#17becf", "#9edae5"
])然后我们找到每个新闻最可能的主题:
_lda_keys = []
for i in xrange(X_topics .shape[0]):
_lda_keys += _topics[i] .argmax(),
#获得每个主题的顶级单词:
topic_summaries = []
topic_word = lda_model .topic_word_ # 所有主题关键词
vocab = cvectorizer .get_feature_names()
for i, topic_dist in enumerate(topic_word):
topic_words = np .array(vocab)[np .argsort(topic_dist)][: -(n_top_words + 1): -1] # 获得数据
topic_summaries .append(' ' .join(topic_words)) # 附加到关键词列表最后我们绘制新闻(每个点代表一个新闻):
title = '20 newsgroups LDA viz'
num_example = len(X_topics)
plot_lda = bp .figure(plot_width =1400, plot_height =1100,
title =title,
tools ="pan,wheel_zoom,box_zoom,reset,hover,previewsave",
x_axis_type =None, y_axis_type =None, min_border =1)
plot_lda .scatter(x =tsne_lda[:, 0], y =tsne_lda[:, 1],
color =colormap[_lda_keys][:num_example],
source =bp .ColumnDataSource({
"content": news[:num_example],
"topic_key": _lda_keys[:num_example]
}))
#并绘制每个主题的关键词:
#随机选择一个新闻(主题内)作为关键词
topic_coord = np .empty((X_topics .shape[1], 2)) * np .nan
for topic_num in _lda_keys:
if not np .isnan(topic_coord) .any():
break
topic_coord[topic_num] = tsne_lda[_lda_keys .index(topic_num)]
#绘制关键词
for i in xrange(X_topics .shape[1]):
plot_lda .text(topic_coord[i, 0], topic_coord[i, 1], [topic_summaries[i]])
hover = plot_lda .select(dict(type =HoverTool))
hover .tooltips = {"content": "@content - topic: @topic_key"}
# 保存
save(plot_lda, '{}.html' .format(title))随时关注您喜欢的主题
你会得到一个像这样的交互式图像:
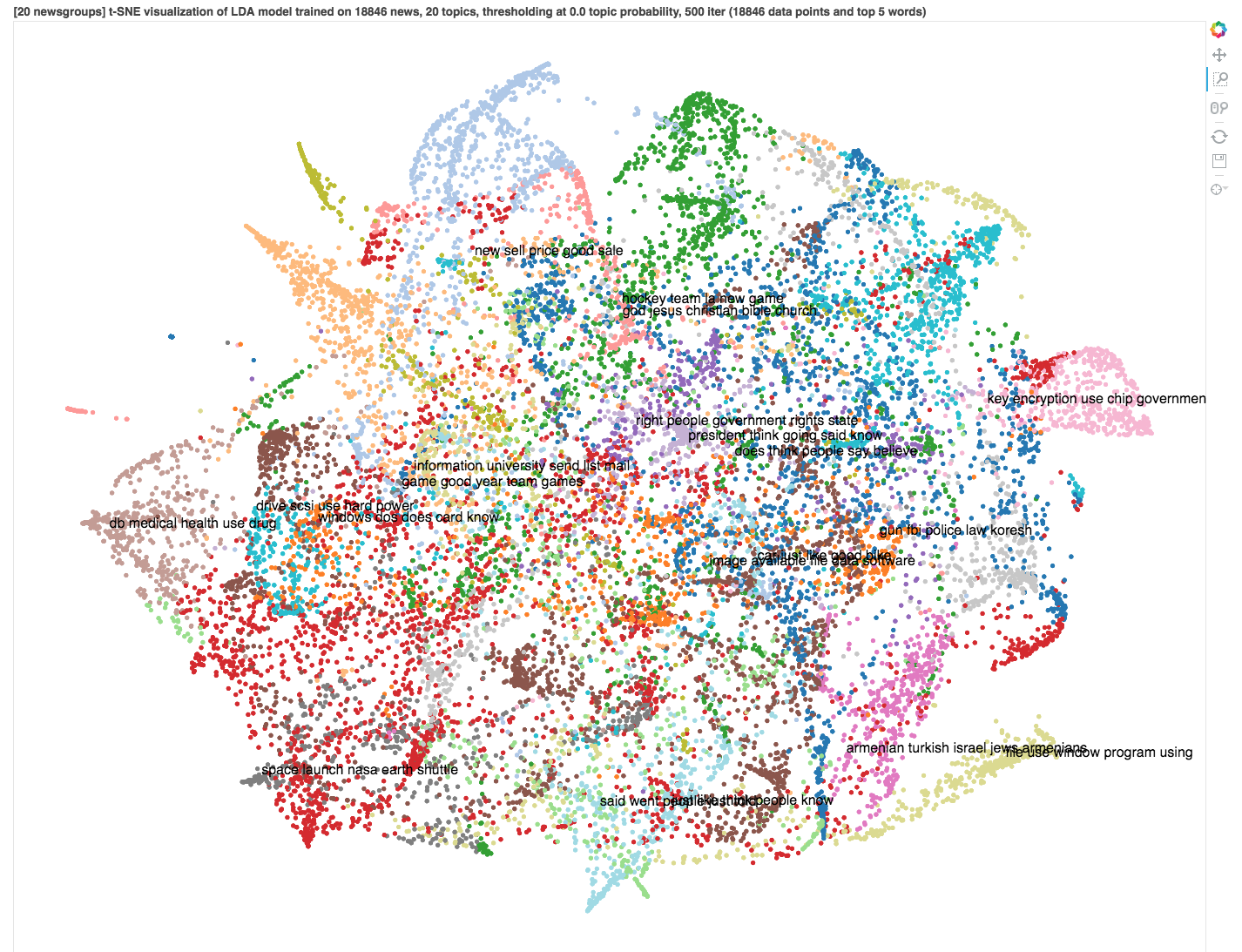
当我们为每个文档分配一个主题时,有些情况下最可能的主题的概率相当低(极端情况是每个主题被分配5%,即,均匀分布)。换句话说,我们的模型无法自信地为这样的新闻分配主题。
一种解决方法是添加一个阈值因子,以帮助过滤掉低置信的分配。在我们训练LDA模型之后,在我们使用t-SNE减少维数之前,简单地说明:
import numpy
threshold = 0.5
_idx = np .amax(X_topics, axis =1) > threshold # 指标代表高于阈值的文档
X_topics = X_topics[_idx]重新运行我们将得到:
看起来好多了:独立、明确的簇!这表明我们的LDA模型能从这个数据集中学到很多,而且我们的模型为所有新闻分配一个好的主题。
Twitter已成为最受欢迎的新闻和社交网络服务(SNS)平台之一。
推文示例
在实时Twitter趋势发现中,我们讨论了如何实时可视化Twitter趋势。然而,我们也可以使用推文语料库来模拟主题。
我们希望将推文保存到磁盘并积累一定数量(至少数百万)来有效地模拟主题,而不是将推文放在内存中进行实时处理。
首先,我们需要建立一个推文连接。我们可以抓取实时推文:
至少花一两天时间来积累相当数量的推文。有时连接可能会中断:只需重新运行脚本,以便将新推文保存到磁盘。
获得足够的推文后,我们可以加载推文,处理它们,对它们进行矢量化并计算tf-idf分数,训练LDA模型,减少到2-D,并可视化结果。
你会得到一个如下图:
这是对200万条推文进行过训练的模型的可视化,只显示了5,000个数据点(或推文)。我们有一些很好的集群学习模型:例如’视频赞同’代表社交网络内容。
 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据 Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据
Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据

