某交通工程专业博士生想要研究不同因素对通勤交通方式选择的影响。
对成都两个大型小区(高端和普通)居民分别进行了出行调查,各调查了300人。
其中
Distance:居住地离上班地的距离(公里)
Pincome:个人年收入(万元)
Hincome:家庭年收入(万元)
Age:年龄
Gender:性别(0:女;1:男)
Car:家庭拥有汽车的数量
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
People:家里人口数量
Children:家里未成年人数量
可下载资源
Housing:房屋拥有类型(0:租房;1:买房)
Area:房屋居住面积(平方米)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
但是小区的编号忘记记录下来。
任务:
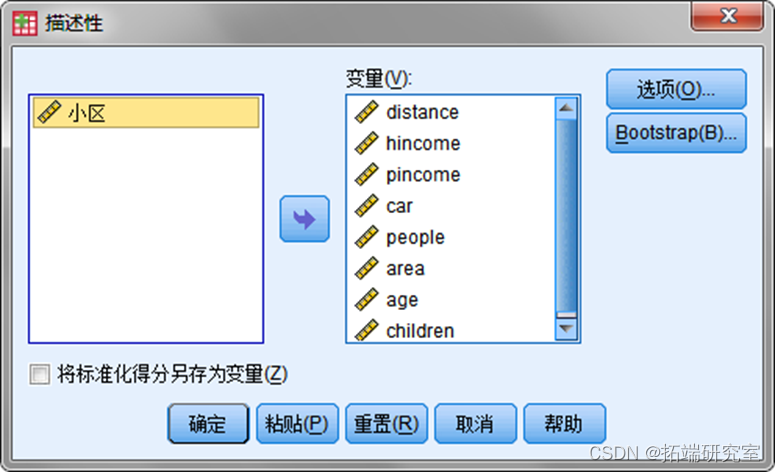
- 判断每个变量时数值型变量还是分类型变量,数组型的计算其均值和方差,分类型的列出每类的频率。
数值型变量为:
城市交通拥挤、交通事故、环境污染已是全世界面的共同问题,并成为制约各城市社会和经济进一步发展的瓶颈问题。但由于受到了经济条件、技术条件、环境条件、空间条件等制约,单纯依靠增加投资、进行大规模交通基础设施建设解决城市交通问题的传统方法,已不能适应城市交通的迅速发展。
相对于其他出行,通勤出行在时间和空间上具有更大的恒定性,其时间安排是影响城市居民其他活动和出行的选择。从某种意义而言,通勤活动也是其他活动的基础。特别是随着城市居民就业范围的扩大,通勤出行的数量不仅迅速增加,而且也日益的复杂化。特别是由于通勤出行集中在一定的高峰期和一定的区域,使得早、晚高峰通勤时段的交通拥堵,成为城市交通问题最为突出的问题。
Distance:居住地离上班地的距离(公里)
Pincome:个人年收入(万元)
Hincome:家庭年收入(万元)
Age:年龄
Car:家庭拥有汽车的数量
People:家里人口数量
Children:家里未成年人数量
Area:房屋居住面积(平方米)
视频
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
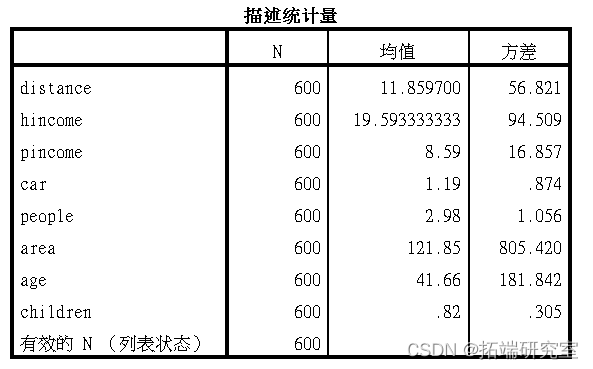
分类型变量为:
Gender:性别(0:女;1:男)
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
Housing:房屋拥有类型(0:租房;1:买房)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
分类型变量为:
Gender:性别(0:女;1:男)
Education:教育水平(1:初中及以下;2:高中;3:专科;4:本科;5:研究生)
Job:工作类型(1:公司职员;2:工厂工人;3:公务员;4:个体;5:事业单位;6:其他)
Housing:房屋拥有类型(0:租房;1:买房)
Mode:主要通勤出行方式(1:汽车;2:公共交通;3:电动自行车;4:其他)
- 判断每个受访者所在的小区。
根据居住地距离 ,我们使用kmean聚类将样本分成2个类别,并保存结果到小区变量中。
结果如图所示。
聚类中心结果如下
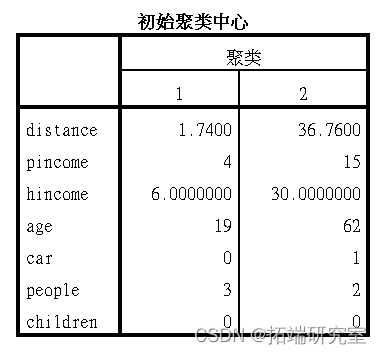
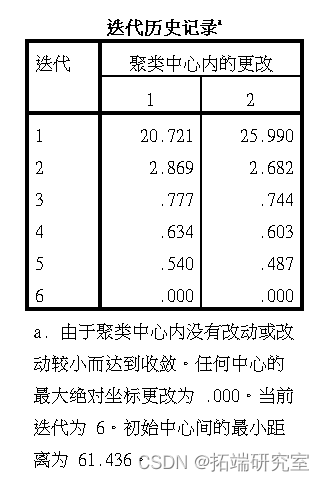
每个样本的聚类信息:
- 分析不同小区居民的平均出行距离、平均家庭收入、年龄分布、性别分布、家庭人口数和受教育程度有什么区别吗?
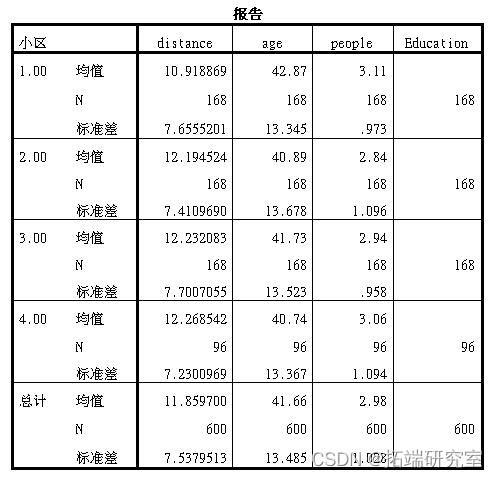
从均值比较的结果来来看,第1个类别的工作里小区工作距离较短,第三个类别年龄较小,第一个小区家庭人口较大,教育水平第四个小区较低。

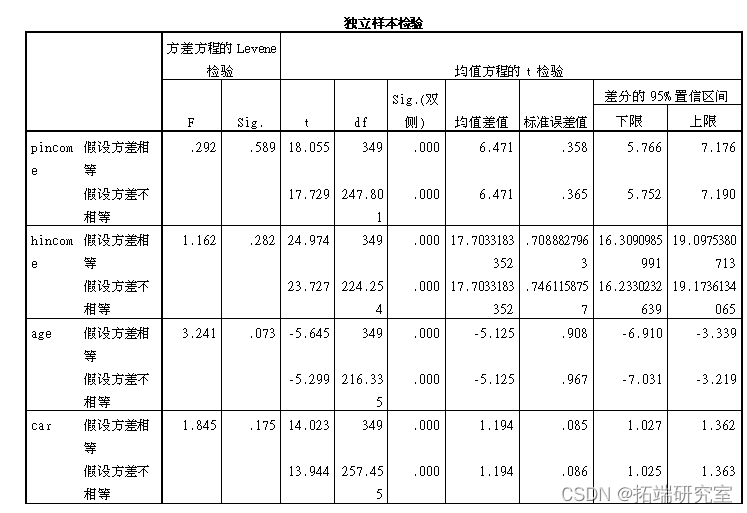
然后对不同聚类类别的数据进行独立样本t检验。
随时关注您喜欢的主题
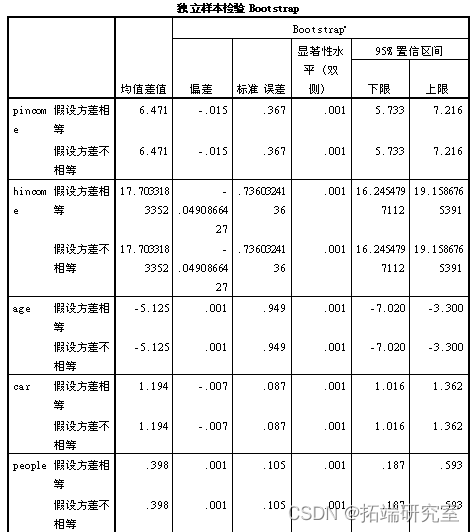
由上表中的结果: distance的sig>0.05,可知: distance无显著区别。
- 对每个小区分别建模(逻辑回归和决策树),看哪个模型对出行方式选择的拟合更好(比较模型在检验样本里的表现,而不是训练样本),并分析各个变量如何影响通勤交通方式的选择。
首先对1区的样本进行决策树模型

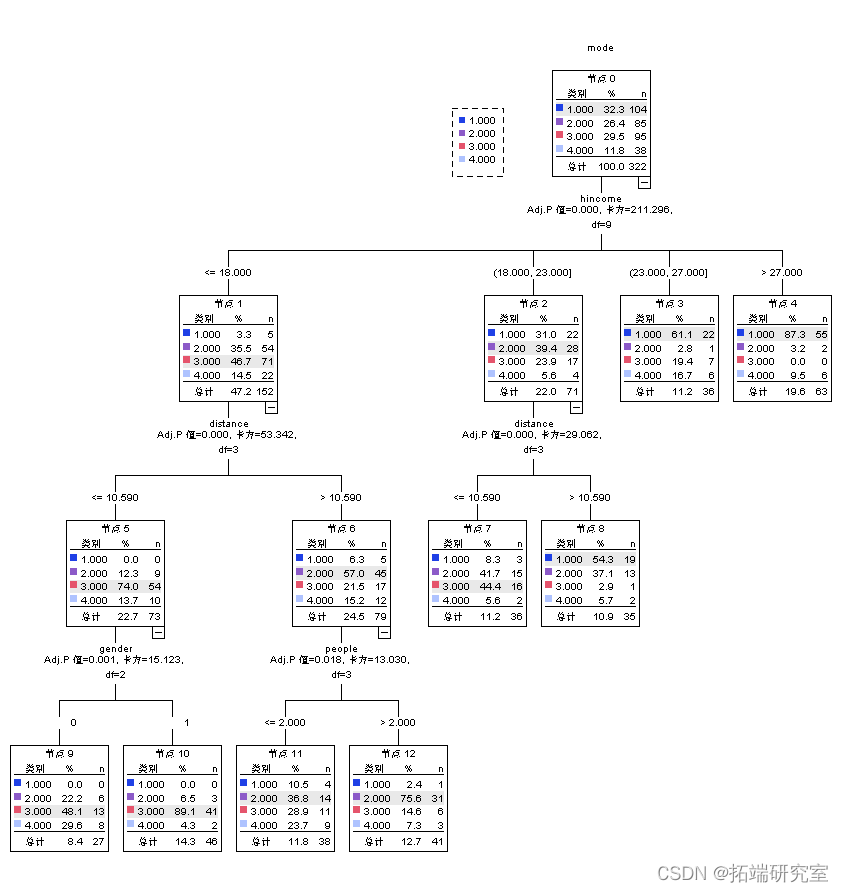
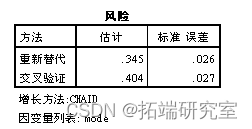
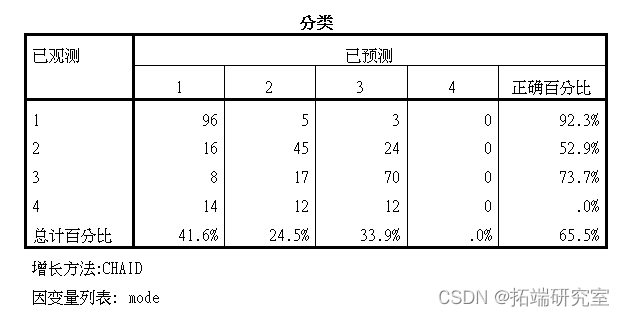
可以看到距离 收入、家庭人口数和性别对出行方式有较大的影响,男性出行以电动车为主,女性也有一部分以公交出行为主,从家庭人口数来看,大于2人的家庭出行以公交车为主。
然后使用逻辑回归进行预测
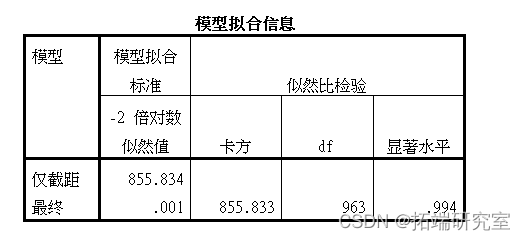

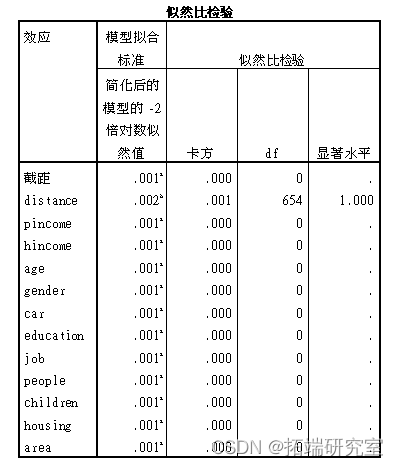
由结果来看整个逻辑回归的表达式是显著的;由“似然比检验”表格可知所有变量的显著性水平均小于0.05,可知自变量对于因变量mode都是显著的;而在参数估计中可得,自变量的显著性水平较低,即这些变量和mode是有关系的。
对2区出行数据进行决策树模型分析
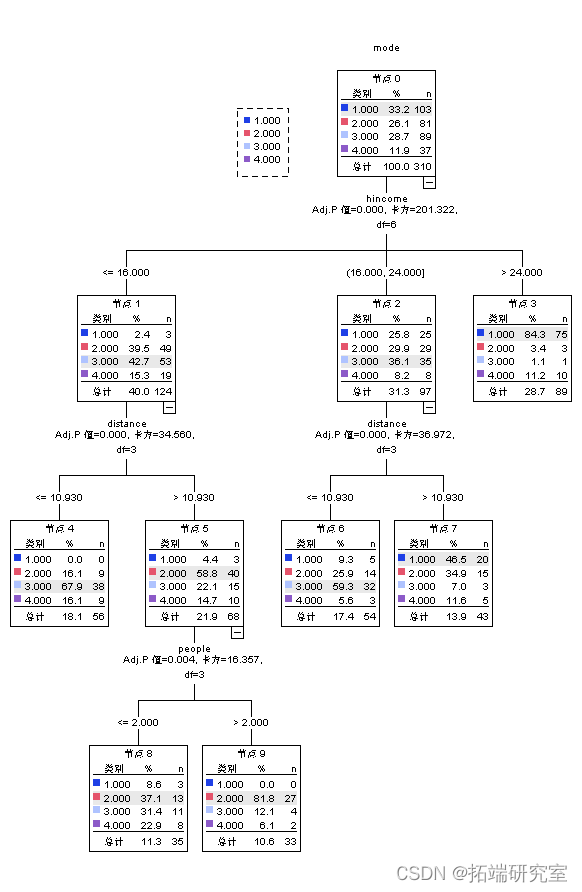
从结果来看,决策树分类模型可以看到区2的出行方式主要受到距离的影响。若距离较大,则出行方式以汽车和电瓶车为主,若距离较小,则以公交车为主。
对区2的出行数据进行逻辑回归
由结果来看整个逻辑回归的表达式是显著的;由“似然比检验”表格可知所有变量的显著性水平均小于0.05,可知自变量对于因变量mode都是显著的;而在参数估计中可得,自变量的显著性水平较低,即这些变量和mode是有关系的。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据
LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 Python、SPSS单指数、FF三因子模型、决策树分析沪深300指数、申万风格指数、10年期国债收益率、300ETF期权波动率指数数据优化金融期货市场预测|附代码数据
Python、SPSS单指数、FF三因子模型、决策树分析沪深300指数、申万风格指数、10年期国债收益率、300ETF期权波动率指数数据优化金融期货市场预测|附代码数据



