本文我们讨论了期望寿命的计算,人口统计模型的起点是死亡率表。
但是,这种假设有偏差,因为它假设生活条件不会得到改善。为了正确处理问题,我们使用了更完整的数据,其中死亡人数根据x岁而定,还包括日期t。
可下载资源
DE=read.table("DE.txt",skip = 3,header=TRUE)
EXPS=read.table("EXPS.txt",skip = 3,header=TRUE)
Lee-Carter模型的主要思路是将死亡率的变化分解为时间因子t和年龄因子x。如果用 表示x岁的人群在第t年的中心死亡率,那么
表示x岁的人群在第t年的中心死亡率,那么 满足以下函数关系式。
满足以下函数关系式。
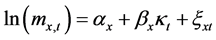 (1)
(1)
其中, 反应x岁年龄组别的对数中心死亡率的平均水平,
反应x岁年龄组别的对数中心死亡率的平均水平, 为人口死亡率随时间变化的速度,
为人口死亡率随时间变化的速度, 为年龄因子对
为年龄因子对 的敏感度,即x岁年龄组别的死亡率随着时间变化的大小,
的敏感度,即x岁年龄组别的死亡率随着时间变化的大小, 为随机误差项,假设其服从正态分布
为随机误差项,假设其服从正态分布 。为了得到唯一确定的参数估计值,加入约束条件
。为了得到唯一确定的参数估计值,加入约束条件 以及
以及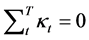 。
。 是为了保证参数
是为了保证参数 的平均值的含义,即
的平均值的含义,即 。
。
模型的求解
Lee-Carter模型参数的估计方法主要包括矩阵奇异值分解法(SVD)、最小二乘(OLS)和加权最小二乘法(WLS);奇异值分解法和最小二乘法对不同年龄人群的死亡率赋予了相同的权重,但Koissi [2] 证明了,在现实情况下,不同年龄人群对应的人口数和死亡人口数都存在较大的差异,因此这两种方法在死亡率很低的条件下使用效果较差。为此,本文采用加权最小二乘法来估计Lee-Carter模型。
加权最小二乘法通过以下两个步骤求得 ,
,
第一步,将式(1)两边对年龄x 求和,得到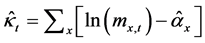 。
。
第二步,Wilmoth证明 的方差近似等于死亡人数
的方差近似等于死亡人数 的倒数,因此可以将
的倒数,因此可以将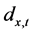 作为残差平方和的权重。最小化经加权处理后的残差平方和
作为残差平方和的权重。最小化经加权处理后的残差平方和 ,即
,即 得到
得到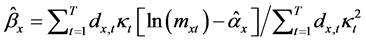
我们用 Dx,t表示死亡人数,Ex,t表示暴露人数。因此,对于在日期t上x岁的某人,在该年死亡的概率为 qx,t = Dx,t / Ex,t。这些数据存储在矩阵中进行可视化,存储在数据库中进行回归。
QF[QF==0]=NA
QH[QH==0]=NA必须进行一些修改以避免出现零值的问题,因为(i)我们求出比率(ii)然后我们对数化)。我们可以可视化为x和t的函数。
persp(log(QF))
或
persp3d(ages,annees,log(QH),col="light blue")
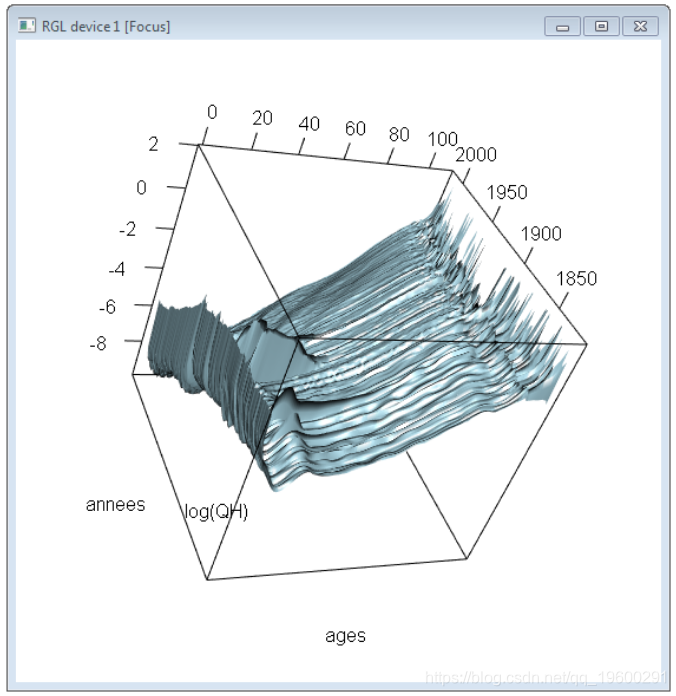
为了模拟qx,t的演化,我们可以从Lee&Carter(1992)的模型中获得启发,该模型 假设log (qx,t)= Ax + Bx⋅Kt。A =(A0,A1,⋯,A110)在某种程度上是log(qx,t)。K =(K1816,K1817,⋯,K2015)使我们了解生活条件的改善,一年内死亡的可能性降低。这些改善不是均匀的,因此我们使用B =(B0,B1,⋯,B110)来使改善取决于l ‘年龄。
为了估计参数A,B和K,我们尝试使用二项式模型。B(Ex,t,qx,t),这是人寿保险的基本模型。这里Dx,t〜B(Ex,t,exp [ Ax + Bx⋅Kt])。
另一个线索是使用小数定律,即如果概率低(一年中的死亡概率就是这种情况),则二项式定律可以近似由泊松分布。我们在这里用到了Poisson回归,其解释变量为年龄x,年t和暴露量为偏移变量。唯一的问题是它不是线性回归。我们这里有非线性模型,因为E [ Dx,t] =(exp[log(Ex,t)+ Ax + Bx⋅Kt])。
gnm( DH ~ offset(log(EH) + as.factor(age) +
Multas.factor(age,as.factor(annee),
family = poisson(link="log")我们有估计系数A ^,B ^和K ^。
Ax=reg$coefficients[2:111]
Bx=reg$coefficients[112:222]
Kt=reg$coefficients[223:length(reg$coefficients)]我们可以表示三组系数。首先 A ^表示平均变化,
plot(ages[-1],Ax)
我们还可以用 K ^来绘制时间。
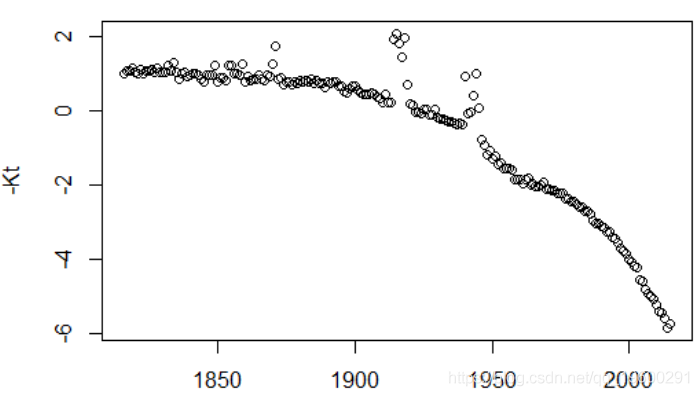
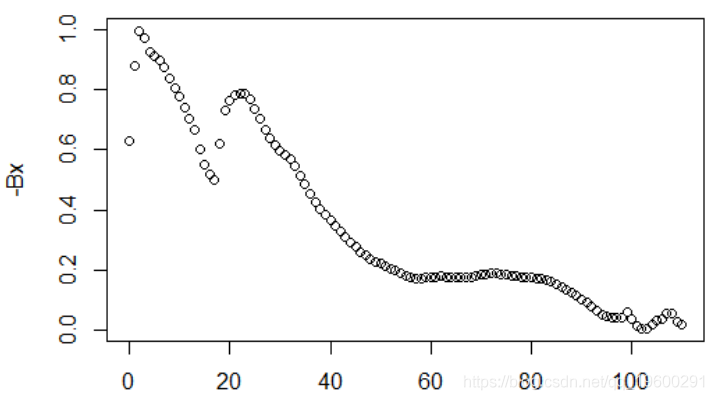
同样,该模型不可被识别。简而言之,改善没有任何意义。我们可以表示-K ^,它的优点是描述了生活条件的改善。最后,让我们作图-B ^

困难在于,为了预测期望寿命,我们需要针对t的大值(尚未观察到)计算qt,x。例如,某人可能想知道q50,2020(对于1970年出生的人)。我们要使用q50,2020 = exp(A ^ 50 + B ^ 50 K ^ 2020)。问题是K ^ 2020不属于估计数量K ^。
这个想法是Lee&Carter(1992)的初衷,我们可以尝试指数模型或线性模型(在1950年以后的原始K ^序列上)
lm(log(Kt[idx])~ann[idx])
futur=2016:2125
lm(Kt[idx]~ann[idx])
points(futur,pr,col="blue")随时关注您喜欢的主题
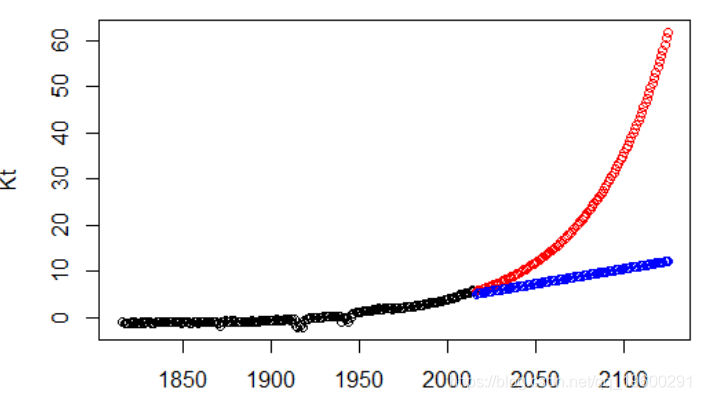
然后,我们可以根据过去的数据建立一系列预测,q ^ x,t = exp [A ^ x + B ^ x K ^ t],以及未来数据q〜x,t = exp [A ^ x + B ^ x K〜t]。
我们保留过去的数据,这里是1880年死亡的概率
plot(BASE$x[BASE$t==1880],BASE$pred[BASE$t==1880],
log="y")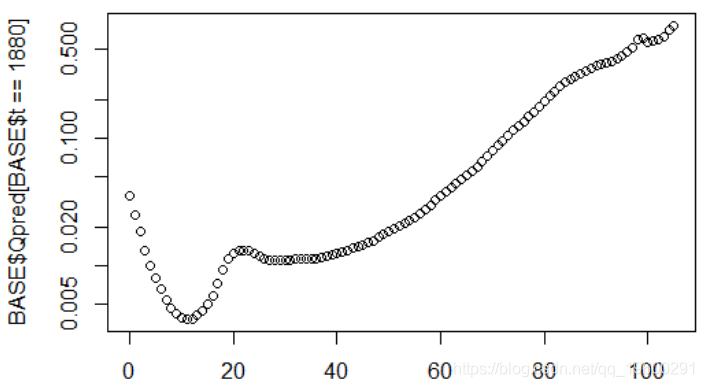
同样,我们在未来(此处为2050年)使用这两种模型
BASE2$Qpred1=exp(cste+BASE2$Ax+BASE2$Bx*BASE2$Kt1)
plot(BASE2$x[BASE2$t==2050],BASE2$Qpred1[BASE2$t==
2050],log="y")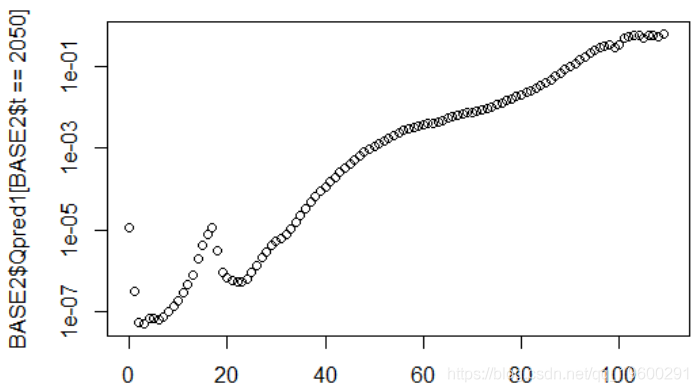
用于指数预测
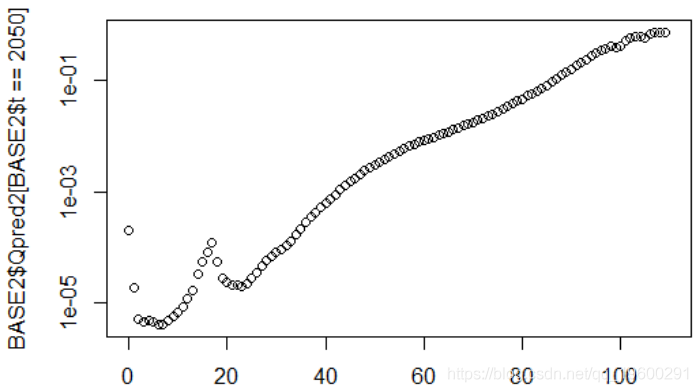
对于线性预测,对1968年出生的人,我们有第二年死亡的概率
if(sbase$t[i]<= 2015)
{vq[i]=BASE[ BASE$x==sbase$x[i]) & BASE$t==sbase$t[i]),"Qpred"]
if(sbase$t[i] <2015)
{vq[i]=BASE2[(BASE2$x==sbase$x[i]) & (BASE2$t==sbase$t[i]),"Qpred2"]
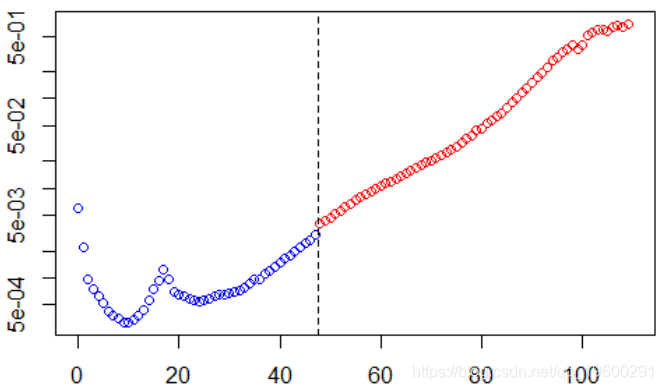
左边是我们模型估算值,右边是预测值。
要计算出生时的期望寿命,我们使用以下代码
sum(cumprod(exp(-vq[1:110])))
[1] 77.62047然后,我们可以做函数可视化这种期望寿命的演变
vP = cumprod(exp(-(sbase$vq[1:110])))
sum(vP)}
ANN =1930:2010
plot(ANN ,E2)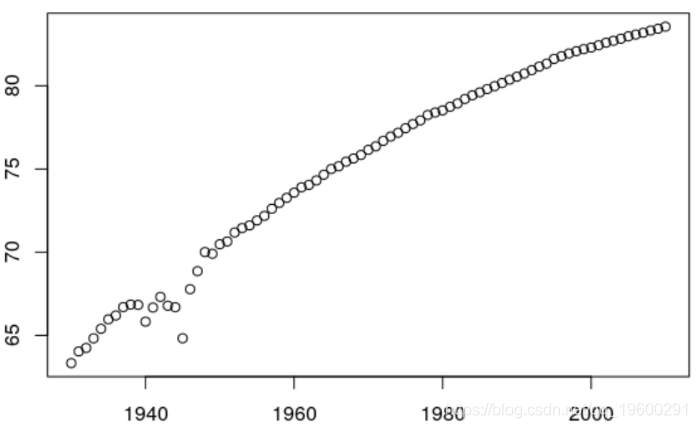
如果我们看一下变化,我们发现每年(大约)有0.25的变化
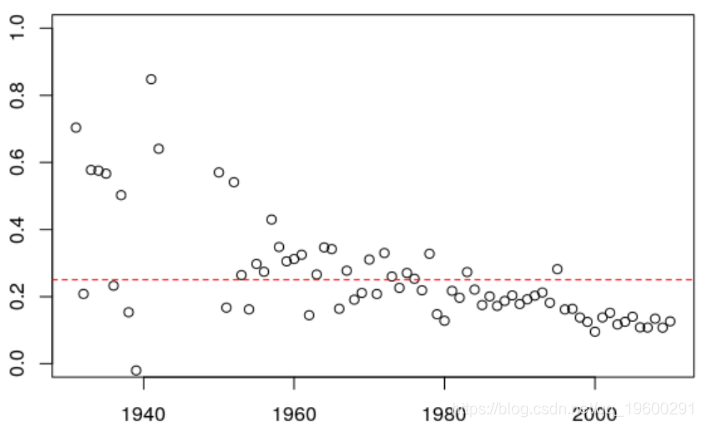
另一方面,如果我们采用保留Kt指数变化的预测,则可以得出
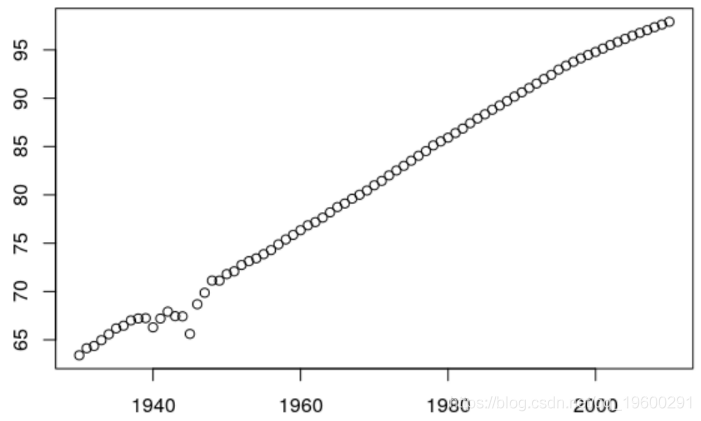
结果不符合实际,它更少地考虑曲线的变化。

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究 Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究
Python+AI提示词出租车出行轨迹:梯度提升GBR、KNN、LR回归、随机森林融合预测及贝叶斯概率异常检测研究 Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享
Python对Airbnb北京、上海链家租房数据用逻辑回归LR、决策树、岭回归、Lasso、随机森林、XGBoost、神经网络kmeans聚类分析市场影响因素|数据分享


