
关联规则挖掘是一种识别不同项目之间潜在关系的技术。
以超级市场为例,客户可以在这里购买各种商品。通常,客户购买的商品有一种模式。例如,有婴儿的母亲购买婴儿产品,如牛奶和尿布。少女可以购买化妆品,而单身汉可以购买啤酒和薯条等。总之,交易涉及一种模式。如果可以识别在不同交易中购买的物品之间的关系,则可以产生更多的利润。
例如,如果项目A和项目B的购买频率更高,则可以采取几个步骤来增加利润。例如:
- A和B可以放在一起,这样,当客户购买其中一种产品时,他不必走很远就可以购买另一种产品。
- 购买某一种产品的人可以通过广告活动来定位以购买另一种产品。
- 如果客户购买了这两种产品,则可以在这些产品上提供折扣。
- A和B都可以包装在一起。
识别产品之间的关联的过程称为关联规则挖掘。
关联规则挖掘的Apriori算法
已经开发出不同的统计算法来实现关联规则挖掘,而Apriori就是这样一种算法。在本文中,我们将研究Apriori算法背后的理论,稍后将在Python中实现Apriori算法。
先验算法理论
支持度
支持是指商品的默认受欢迎程度,可以通过查找包含特定商品的交易数量除以交易总数来计算。假设我们想找到对项目B的支持。可以将其计算为:
Support(B) = (Transactions containing (B))/(Total Transactions)
例如,如果在1000个事务中,有100个事务包含Ketchup,则对项目Ketchup的支持可以计算为:
Support(Ketchup) = (Transactions containingKetchup)/(Total Transactions)
Support(Ketchup) = 100/1000
= 10%
置信度
置信度是指如果购买了商品A,也购买了商品B的可能性。可以通过找到一起购买A和B的交易数量除以购买A的交易总数来计算。从数学上讲,它可以表示为:
Confidence(A→B) = (Transactions containing both (A and B))/(Transactions containing A)
回到我们的问题,我们有50笔交易,汉堡和番茄酱是一起购买的。在150笔交易中,会购买汉堡。然后我们可以发现购买汉堡时购买番茄酱的可能性可以表示为Burger-> Ketchup的置信度,并且可以用数学公式写成:
Confidence(Burger→Ketchup) = (Transactions containing both (Burger and Ketchup))/(Transactions containing A)
Confidence(Burger→Ketchup) = 50/150
= 33.3%
提升度
Lift(A -> B)指当出售A时B的出售比例的增加。提升(A –> B)可以通过除Confidence(A -> B)以来计算Support(B)。从数学上讲,它可以表示为:
Lift(A→B) = (Confidence (A→B))/(Support (B))
回到我们的汉堡和番茄酱问题,Lift(Burger -> Ketchup)可以计算为:
Lift(Burger→Ketchup) = (Confidence (Burger→Ketchup))/(Support (Ketchup))
Lift(Burger→Ketchup) = 33.3/10
= 3.33
Lift基本上告诉我们,一起购买汉堡和番茄酱的可能性是仅购买番茄酱的可能性的3.33倍。
Apriori算法涉及的步骤
对于大量数据,成千上万的交易中可能有数百个项目。Apriori算法尝试为每种可能的项目组合提取规则。例如,可以为项目1和项目2,项目1和项目3,项目1和项目4,然后是项目2和项目3,项目2和项目4,然后是项目1,项目2和项目3的组合计算提升。项目3;类似地,项目1,项目2和项目4,依此类推。
用Python实现Apriori算法
从理论上讲,现在是时候看看Apriori算法了。在本节中,我们将使用Apriori算法查找规则,这些规则描述了在法国零售商店一周进行7500次交易的不同产品之间的关联。
另一个有趣的一点是,我们不需要编写脚本来为所有可能的项目组合计算支撑度,置信度和提升度。我们将使用一个现成的库,其中所有代码都已实现。
我指的是apyori库,可以在这里找到源。我建议您在继续之前,在Python库的默认路径中下载并安装该库。
注意:本文中的所有脚本均已使用Spyder IDE for Python 执行。
请按照以下步骤在Python中实现Apriori算法:
导入库
与往常一样,第一步是导入所需的库。
导入数据集
现在,我们导入数据集执行以下脚本:
store_data = pd.read_csv('D:\\Datasets\\store_data.csv')
让我们调用该head()函数以查看数据集:
store_data.head()
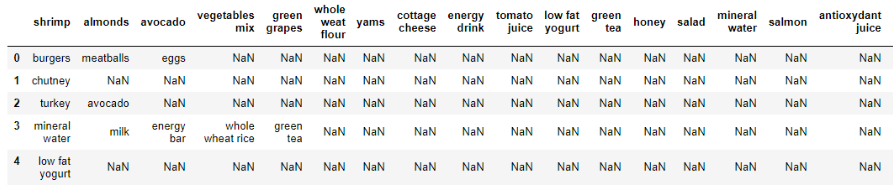

上面的屏幕快照中显示了数据集的摘要。如果仔细查看数据,我们可以看到标题实际上是第一个事务。每行对应一个交易,每列对应于在该特定交易中购买的商品。在NaN告诉我们,列所代表的项目在具体的交易没有购买。
在此数据集中没有标题行。 如下所示:
store_data = pd.read_csv('D:\\Datasets\\store_data.csv', header=None)
现在执行head()函数:
store_data.head()
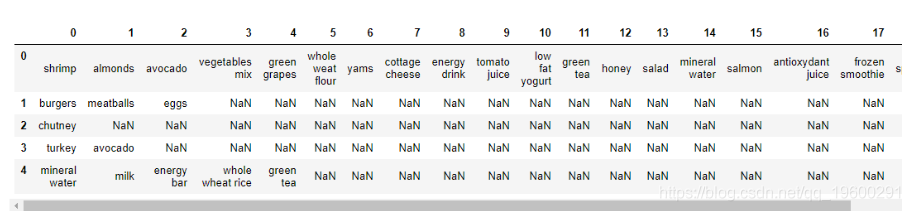

现在,我们将使用Apriori算法来找出哪些商品通常一起出售,以便商店所有者可以采取行动将相关商品放在一起或一起做广告 。
数据处理
我们将要使用的Apriori库要求我们的数据集采用列表列表的形式,其中整个数据集是一个大列表,而数据集中的每个事务都是外部大列表中的一个内部列表。
应用
下一步是将Apriori算法应用于数据集。为此,我们可以使用apriori从apyori库导入的类。
在第二行中,我们将apriori类找到的规则转换为,list因为这样更容易查看结果。
查看结果
首先让我们找到apriori该类挖掘的规则总数。执行以下脚本:上面的脚本应返回48。每个项目对应一个规则。
让我们打印association_rules列表中的第一项以查看第一条规则。执行以下脚本:输出应如下所示:
RelationRecord(items=frozenset({'light cream', 'chicken'}), support=0.004532728969470737, ordered_statistics[OrderedStatistic(items_base=frozenset({'light cream'}), items_add=frozenset({'chicken'}), confidence=0.29059829059829057, lift=4.84395061728395)])
列表中的第一项是包含三项的列表本身。列表的第一项显示规则中的杂货项目。
例如,从第一项开始,我们可以看到淡奶油和鸡肉通常一起购买。这是有道理的,因为购买淡奶油的人对自己吃的东西很谨慎,因此他们更有可能购买鸡肉即白肉而不是红肉即牛肉。或这可能意味着淡奶油通常用于鸡肉食谱中。
第一条规则的支持值为0.0045。该数字是通过将含淡奶油的交易次数除以交易总数得出的。该规则的置信度为0.2905,这表明在所有包含轻奶油的交易中,29.05%的交易也包含鸡肉。最终,提升4.84告诉我们,与默认销售鸡肉的可能性相比,购买淡奶油的顾客购买鸡肉的可能性高4.84倍。
以下脚本以更清晰的方式显示每个规则的规则,支撑,置信度和提升:
如果执行上述脚本,您将看到apriori该类返回的所有规则。apriori该类返回的前四个规则如下所示:
Rule: light cream -> chicken
Support: 0.004532728969470737
Confidence: 0.29059829059829057
Lift: 4.84395061728395
=====================================
Rule: mushroom cream sauce -> escalope
Support: 0.005732568990801126
Confidence: 0.3006993006993007
Lift: 3.790832696715049
=====================================
Rule: escalope -> pasta
Support: 0.005865884548726837
Confidence: 0.3728813559322034
Lift: 4.700811850163794
=====================================
Rule: ground beef -> herb & pepper
Support: 0.015997866951073192
Confidence: 0.3234501347708895
Lift: 3.2919938411349285
=====================================
我们已经讨论了第一条规则。现在让我们讨论第二条规则。第二条规则指出,经常购买蘑菇奶油酱和无骨牛排。蘑菇奶油酱的支持量是0.0057。
结论
关联规则挖掘算法(例如Apriori)对于查找数据项之间的简单关联非常有用。它们易于实现并且具有很高的解释能力。
 SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究
SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究 R语言、WEKA关联规则、决策树、聚类、回归分析工业企业创新情况影响因素数据
R语言、WEKA关联规则、决策树、聚类、回归分析工业企业创新情况影响因素数据 SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究
SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究 WEKA关联规则挖掘Apriori算法在学生就业数据中的应用
WEKA关联规则挖掘Apriori算法在学生就业数据中的应用


