
诸如长期短期记忆网络(LSTM)之类的高级深度学习模型能够捕获时间序列数据中的模式,因此可用于对数据的未来趋势进行预测。
最近我们被客户要求撰写关于时间序列预测的研究报告。在本文中,您将看到如何使用LSTM算法使用时间序列数据进行将来的预测。
可下载资源
数据集和问题定义
让我们先导入所需的库,然后再导入数据集:
一、长期依赖的问题
循环神经网络的一个吸引人的地方在于其能够结合之前的状态保留下来的信息来用于当前任务的处理,比方说其可以利用视频文件中之前的帧所包含的信息来帮助理解当前的图像帧,或者根据句子中之前的文字信息来预测之后可能出现的单词。有时候我们只需考虑最近的信息来帮助解决当前的任务,比方说我们想要预测句子”The clouds are in the sky.”中的最后一个单词,我们只需要前面位置不远的几个词汇即可进行有效的预测; 而当我们面临下面这样的文本”I grew up in France… I speak fluent French.”来预测最后一个单词时,前面位置相近的词汇所能提供的信息或许只是最后的单词是一个语言的名字,若我们考虑更长的依赖关系我们便能够将这个范围缩小到”French”。LSTM就是针对数据的长短期依赖关系所提出的一个十分经典的循环神经网络结构,并且在自然语言处理,视频理解与目标检测,深度强化学习等领域有着十分广泛的应用。
二、关于LSTM的一个直觉理解
考虑这样一个场景,当我们在看一个精彩的电影时,我们会被电影中的各个精彩情节所吸引,但是我们不能够记住所有的电影情节。当观影结束时,我们会立马忘记电影里面一些无关紧要的情节,留在我们脑海中的可能更多的是一些对剧情发展起关键作用的场景,这些场景可能在之后的很长一段时间后依然停留在我们的脑海中,以至于当我们去观看电影的续集时还能够利用到之前所观看的电影的情节作为铺垫来帮助我们理解新的内容。人类的这一记忆过程可以抽象为对已有知识的选择性遗忘与选择性保留,事实上LSTM模块的设计便是与这一记忆过程有着十分密切的联系的。
三、LSTM的基本结构
LSTM与基本的递归神经网络具有类似的控制流程,不同的是LSTM基本单元内部的控制逻辑要稍稍复杂。LSTM的核心部件是基本单元,其中包含几个控制结构来对序列中的数据进行处理。LSTM基本块可以通过内部的门结构,包括遗忘门,更新门,输出门,来对之前的输入信息进行增加与遗忘,一个基本块内部基本单元之间的关系如下图所示。
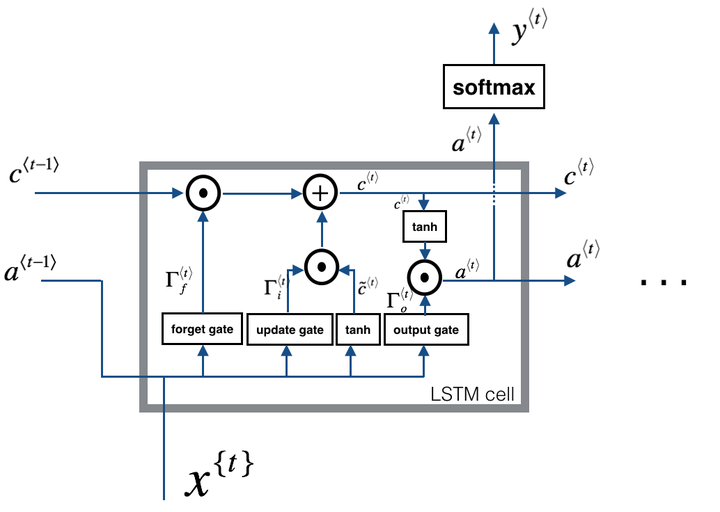
3.1 遗忘门
为了便于说明,我们可以用一个简单的例子来说明遗忘门所起的作用。假设我们用一个LSTM结构来跟踪一篇英文文本的语法结构,比方说主语的单复数,那么当文章的主语由单数变为复数的时候我们需要找到一个方法来清楚我们之前所保留的主语为单数的状态。在LSTM中,一个遗忘门结构执行如下的操作:
其中, 是用来控制遗忘门行为的权重矩阵,我们将
和
连接起来并用
去乘连接后的矩阵,然后在加上一个偏置
,最后通过sigmoid函数将值映射到区间[0,1]。遗忘门的输出结果
将会与上一个单元的状态值进行对应元素的乘法运算。因此,如果
中的一个值为0或接近0,那么上一个单元
的对应信息(比方说代表主语为单数的信息)将被丢弃,如果
中的值为1,那么对应的信息将被保留。
3.2 更新门
还是以跟踪句子主语的单复数为例,当我们在遗忘门中对主语为单数的状态信息进行遗忘后,还需要对状态进行更新写入以表明现在主语已经更新为复数了。更新门实际上就是在进行这一操作,其基本操作可表示为:
与遗忘门类似,更新门的输出结果 同样是一个值在[0,1]范围内的向量。为了计算新的状态信息
,更新门的输出结果将会与
进行元素之间的乘法运算。
3.3 单元状态的更新
我们需要对在序列间进行传递的单元状态值 进行更新,如LSTM的结构图所示,首先我们需要计算中间变量为:
然后,新的单元状态为:
我们可以看到,新的单元状态融合了过去的单元状态信息,旧的单元内部的隐藏信息以及新的输入数据。
3.4 输出门
输出门中可以得到当前单元的输出值 和传递到下一个单元的隐藏状态值
,其具体的计算过程如下:
其中计算得到的 可以根据需要接上一个sigmoid或者softmax作为网络单元的最后输出。
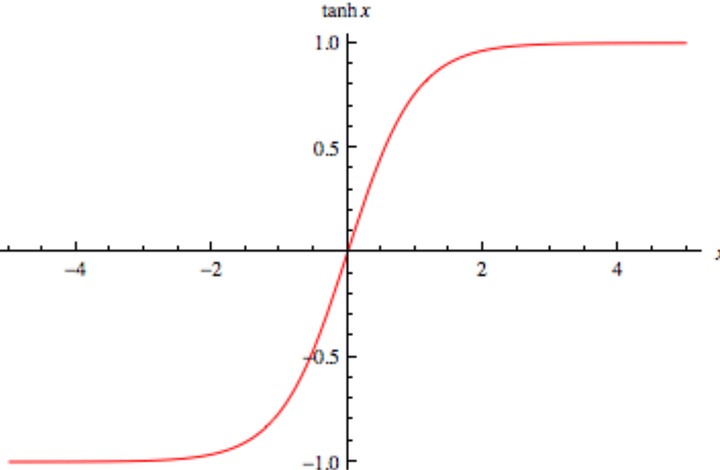
3.5 RNN中的tanh函数
我们知道一个向量被输入到神经网络之后会被执行很多的运算,tanh函数的图像如下所示,可以看出其将输入的向量变换到(-1,1)之间,这样当神经网络不断执行各种运算的时候就会在每一层对向量的值进行限制,从而避免出现向量内部各个值之间的差距过大的现象。当然传统的Relu也可用于RNN的激活函数,将RNN的激活函数变为Relu可能会产生很大的输出值,但是在这里我们不对RNN中激活函数的选择问题进行更加深入的探讨。
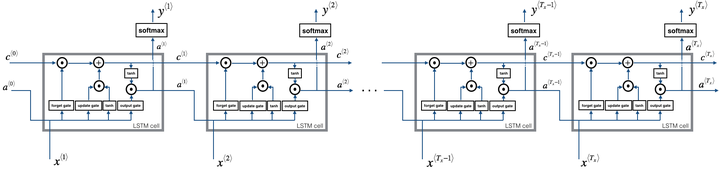
3.6 LSTM的前向传播过程
根据上述的推导过程,我们便可得到如下的LSTM前向计算过程示意图:
四、LSTM的反向传播过程
LSTM的反向传播过程较为复杂,需要特别注意的是单元内部的信息 被前向传递到了
和
中,因此求导时链式法则涉及到
的地方要特别注意。下面是LSTM单个单元反向传播过程的详细推导,其中
表示矩阵对应元素的乘积,
符号表示矩阵乘法运算,注意在吴恩达深度学习作业中,该部分的过程有些小错误。
五、GRU与双向RNN
GRU结构要比LSTM简单,在这里我们只给出其前向计算的计算过程:
其中 作为单元的隐藏状态不断往后传递信息,同时在
后加入sigmoid或者softmax函数作为当前单元的输出。可以明显的看出GRU具有比LSTM简单的结构,因此由于其计算代价较低,GRU在众多场合也有着十分广泛的应用。
上述提到的循环神经网络都能实现对过去的信息进行利用,我们考虑某个问题场景比如机器翻译问题知道未来的信息可能对当前的过程具有积极的作用,为了对序列数据中的当前时刻的未来信息加以利用,我们可以建立双向的RNN神经网络结构(BRNN)。BRNN的思路其实就是增加一个RNN模块,只不过这个模块的输入序列是正常序列数据的逆序,最后的输出结果是两个方向的输出进行汇总,从而达到同时利用过去的信息和未来的信息来解决当前问题的目的。
此外,我们还可以堆叠多个RNN模块,从而形成一个深度RNN结构,在Deep RNN 中,当前时刻的数据要经过多个RNN模块的前向计算才能得到最后的输出结果
六、小结
循环神经网络在处理序列化数据如语音识别,机器翻译等场景中具有非常广泛的应用,GRU和LSTM两种基本的结构通过模块中的门结构来控制信息的传递与利用,门结构也可视为对有用信息的一种提取方式。对数据中的有用数据进行抽取的新方法也在不断被提出,后续我们将对神经网络中的注意力机制进行介绍。
import torch
import torch.nn as nn
让我们输出所有数据集的列表:
sns.get_dataset_names()
输出:
['anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'exercise',
'flights',
'fmri',
'gammas',
'iris',
'mpg',
'planets',
'tips',
'titanic']
让我们将数据集加载到我们的程序中
flight_data = sns.load_dataset("flights")
flight_data.head()
输出:

该数据集有三列:year,month,和passengers。passengers列包含指定月份旅行旅客的总数。让我们输出数据集的维度:
flight_data.shape
输出:
(144, 3)
您可以看到数据集中有144行和3列,这意味着数据集包含12年的乘客旅行记录。
任务是根据前132个月来预测最近12个月内旅行的乘客人数。请记住,我们有144个月的记录,这意味着前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最近12个月的值进行评估。
让我们绘制每月乘客的出行频率。 接下来的脚本绘制了每月乘客人数的频率:
输出:

输出显示,多年来,乘飞机旅行的平均乘客人数有所增加。一年内旅行的乘客数量波动,这是有道理的,因为在暑假或寒假期间,旅行的乘客数量与一年中的其他部分相比有所增加。
数据预处理
数据集中的列类型为object,如以下代码所示:
data.columns
输出:
Index(['year', 'month', 'passengers'], dtype='object')
第一步是将passengers列的类型更改为float。
all_data = flight_data['passengers'].values.astype(float)
现在,如果 输出all_datanumpy数组,则应该看到以下浮点类型值:
print(all_data)

输出:
[112. 118. 132. 129. 121. 135. 148. 148. 136. 119. 104. 118. 115. 126.
141. 135. 125. 149. 170. 170. 158. 133. 114. 140. 145. 150. 178. 163.
172. 178. 199. 199. 184. 162. 146. 166. 171. 180. 193. 181. 183. 218.
230. 242. 209. 191. 172. 194. 196. 196. 236. 235. 229. 243. 264. 272.
237. 211. 180. 201. 204. 188. 235. 227. 234. 264. 302. 293. 259. 229.
203. 229. 242. 233. 267. 269. 270. 315. 364. 347. 312. 274. 237. 278.
284. 277. 317. 313. 318. 374. 413. 405. 355. 306. 271. 306. 315. 301.
356. 348. 355. 422. 465. 467. 404. 347. 305. 336. 340. 318. 362. 348.
363. 435. 491. 505. 404. 359. 310. 337. 360. 342. 406. 396. 420. 472.
548. 559. 463. 407. 362. 405. 417. 391. 419. 461. 472. 535. 622. 606.
508. 461. 390. 432.]
前132条记录将用于训练模型,后12条记录将用作测试集。以下脚本将数据分为训练集和测试集。
前132条记录将用于训练模型,后12条记录将用作测试集。以下脚本将数据分为训练集和测试集。
现在让我们输出测试和训练集的长度:
输出:
132
12
如果现在输出测试数据,您将看到它包含all_datanumpy数组中的最后12条记录:
输出:
[417. 391. 419. 461. 472. 535. 622. 606. 508. 461. 390. 432.]
随时关注您喜欢的主题
我们的数据集目前尚未归一化。最初几年的乘客总数远少于后来几年的乘客总数。标准化数据以进行时间序列预测非常重要。以在一定范围内的最小值和最大值之间对数据进行归一化。我们将使用模块中的MinMaxScaler类sklearn.preprocessing来扩展数据。
以下代码 将最大值和最小值分别为-1和1进行归一化。
MinMaxScaler(feature_range=(-1, 1))
输出:
[[-0.96483516]
[-0.93846154]
[-0.87692308]
[-0.89010989]
[-0.92527473]]
[[1. ]
[0.57802198]
[0.33186813]
[0.13406593]
[0.32307692]]
您可以看到数据集值现在在-1和1之间。
在此重要的是要提到数据归一化仅应用于训练数据,而不应用于测试数据。如果对测试数据进行归一化处理,则某些信息可能会从训练集中 到测试集中。
最后的预处理步骤是将我们的训练数据转换为序列和相应的标签。
您可以使用任何序列长度,这取决于领域知识。但是,在我们的数据集中,使用12的序列长度很方便,因为我们有月度数据,一年中有12个月。如果我们有每日数据,则更好的序列长度应该是365,即一年中的天数。因此,我们将训练的输入序列长度设置为12。
接下来,我们将定义一个名为的函数create_inout_sequences。该函数将接受原始输入数据,并将返回一个元组列表。在每个元组中,第一个元素将包含与12个月内旅行的乘客数量相对应的12个项目的列表,第二个元组元素将包含一个项目,即在12 + 1个月内的乘客数量。
如果输出train_inout_seq列表的长度,您将看到它包含120个项目。这是因为尽管训练集包含132个元素,但是序列长度为12,这意味着第一个序列由前12个项目组成,第13个项目是第一个序列的标签。同样,第二个序列从第二个项目开始,到第13个项目结束,而第14个项目是第二个序列的标签,依此类推。
现在让我们输出train_inout_seq列表的前5个项目:
输出:
[(tensor([-0.9648, -0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066,
-0.8593, -0.9341, -1.0000, -0.9385]), tensor([-0.9516])),
(tensor([-0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593,
-0.9341, -1.0000, -0.9385, -0.9516]),
tensor([-0.9033])),
(tensor([-0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341,
-1.0000, -0.9385, -0.9516, -0.9033]), tensor([-0.8374])),
(tensor([-0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000,
-0.9385, -0.9516, -0.9033, -0.8374]), tensor([-0.8637])),
(tensor([-0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385,
-0.9516, -0.9033, -0.8374, -0.8637]), tensor([-0.9077]))]
您会看到每个项目都是一个元组,其中第一个元素由序列的12个项目组成,第二个元组元素包含相应的标签。
创建LSTM模型
我们已经对数据进行了预处理,现在是时候训练我们的模型了。我们将定义一个类LSTM,该类继承自nn.ModulePyTorch库的类。
让我总结一下以上代码。LSTM该类的构造函数接受三个参数:
input_size:对应于输入中的要素数量。尽管我们的序列长度为12,但每个月我们只有1个值,即乘客总数,因此输入大小为1。hidden_layer_size:指定隐藏层的数量以及每层中神经元的数量。我们将有一层100个神经元。output_size:输出中的项目数,由于我们要预测未来1个月的乘客人数,因此输出大小为1。
接下来,在构造函数中,我们创建变量hidden_layer_size,lstm,linear,和hidden_cell。LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。该hidden_cell变量包含先前的隐藏状态和单元状态。lstm和linear层变量用于创建LSTM和线性层。
在forward方法内部,将input_seq作为参数传递,该参数首先传递给lstm图层。lstm层的输出是当前时间步的隐藏状态和单元状态,以及输出。lstm图层的输出将传递到该linear图层。预计的乘客人数存储在predictions列表的最后一项中,并返回到调用函数。下一步是创建LSTM()类的对象,定义损失函数和优化器。由于我们在解决分类问题,
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size

让我们输出模型:
输出:
LSTM(
(lstm): LSTM(1, 100)
(linear): Linear(in_features=100, out_features=1, bias=True)
)
训练模型
我们将训练模型150个步长。
输出:
epoch: 1 loss: 0.00517058
epoch: 26 loss: 0.00390285
epoch: 51 loss: 0.00473305
epoch: 76 loss: 0.00187001
epoch: 101 loss: 0.00000075
epoch: 126 loss: 0.00608046
epoch: 149 loss: 0.0004329932
由于默认情况下权重是在PyTorch神经网络中随机初始化的,因此您可能会获得不同的值。
做出预测
现在我们的模型已经训练完毕,我们可以开始进行预测了。
输出:
[0.12527473270893097, 0.04615384712815285, 0.3274725377559662, 0.2835164964199066, 0.3890109956264496, 0.6175824403762817, 0.9516483545303345, 1.0, 0.5780220031738281, 0.33186814188957214, 0.13406594097614288, 0.32307693362236023]
您可以将上述值与train_data_normalized数据列表的最后12个值进行比较。
该test_inputs项目将包含12个项目。在for循环内,这12个项目将用于对测试集中的第一个项目进行预测,即编号133。然后将预测值附加到test_inputs列表中。在第二次迭代中,最后12个项目将再次用作输入,并将进行新的预测,然后将其test_inputs再次添加到列表中。for由于测试集中有12个元素,因此该循环将执行12次。在循环末尾,test_inputs列表将包含24个项目。最后12个项目将是测试集的预测值。以下脚本用于进行预测:
如果输出test_inputs列表的长度,您将看到它包含24个项目。可以按以下方式输出最后12个预测项目:
输出:
[0.4574652910232544,
0.9810629487037659,
1.279405951499939,
1.0621851682662964,
1.5830546617507935,
1.8899496793746948,
1.323508620262146,
1.8764172792434692,
2.1249167919158936,
1.7745600938796997,
1.7952896356582642,
1.977765679359436]
需要再次提及的是,根据用于训练LSTM的权重,您可能会获得不同的值。
由于我们对训练数据集进行了归一化,因此预测值也进行了归一化。我们需要将归一化的预测值转换为实际的预测值。
print(actual_predictions)
输出:
[[435.57335371]
[554.69182083]
[622.56485397]
[573.14712578]
[691.64493555]
[761.46355206]
[632.59821111]
[758.38493103]
[814.91857016]
[735.21242136]
[739.92839211]
[781.44169205]]
现在让我们针对实际值绘制预测值。看下面的代码:
print(x)
输出:
[132 133 134 135 136 137 138 139 140 141 142 143]
在上面的脚本中,我们创建一个列表,其中包含最近12个月的数值。第一个月的索引值为0,因此最后一个月的索引值为143。
在下面的脚本中,我们将绘制144个月的乘客总数以及最近12个月的预计乘客数量。
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'])
plt.plot(x,actual_predictions)
plt.show()
输出:
 我们的LSTM所做的预测用橙色线表示。您可以看到我们的算法不太准确,但是它仍然能够捕获最近12个月内旅行的乘客总数的上升趋势以及波动。您可以尝试在LSTM层中使用更多的时期和更多的神经元,以查看是否可以获得更好的性能。
我们的LSTM所做的预测用橙色线表示。您可以看到我们的算法不太准确,但是它仍然能够捕获最近12个月内旅行的乘客总数的上升趋势以及波动。您可以尝试在LSTM层中使用更多的时期和更多的神经元,以查看是否可以获得更好的性能。
为了更好地查看输出,我们可以绘制最近12个月的实际和预测乘客数量,如下所示:
plt.title('Month vs Passenger')
plt.ylabel('Total Passengers')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(flight_data['passengers'][-train_window:])
plt.plot(x,actual_predictions)
plt.show()
输出:

预测不是很准确,但是该算法能够捕获趋势,即未来几个月的乘客数量应高于前几个月,且偶尔会有波动。
结论
LSTM是解决序列问题最广泛使用的算法之一。在本文中,我们看到了如何通过LSTM使用时间序列数据进行未来的预测。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据


1 comment on “在Python中使用LSTM和PyTorch进行时间序列预测”