SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
中医治疗慢性胃炎注重辨证施治与中药配伍,传统用药经验多依赖医师传承,难以快速提炼普适性规律并实现精准指导。

观看视频教程,深入了解如何使用SPSS与Python结合Resblock优化BP神经网络,对慢性胃炎病历数据进行聚类分析、关联规则挖掘及预测。
每日分享最新专题行业研究报告(PDF)和数据资料至会员群
随着大数据与人工智能技术的发展,通过数据挖掘解析病历中的中药配伍逻辑,结合神经网络构建用药预测模型,成为赋能中医临床诊疗的重要方向。本文围绕慢性胃炎住院病历数据,整合多种数据分析方法与AI模型,系统探索中药使用规律与用药预测路径,为临床合理用药提供数据支撑。 本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。 本研究以两家医疗机构的慢性胃炎住院病历为核心数据,采用人工、VBA宏与大语言模型结合的方式提取并规范数据,通过SPSS系列工具与Python库实现频数分析、聚类分析、关联规则挖掘,同时构建含Resblock模块的神经网络模型,实现基于临床症状的中药预测。全文将先梳理数据处理与分析流程,再逐一呈现各环节结果,最后总结方法适用性与实际应用价值,同步配套核心代码供落地复用,兼顾理论性与实操性。
项目文件目录

研究方法与技术准备
数据来源与处理
本研究选取两家医疗机构的慢性胃炎住院病历作为研究对象,其中一家机构数据时间范围为2016年1月至2024年5月,聚焦中药配伍规律挖掘;另一家机构数据时间范围为2013年1月至2021年10月,用于神经网络模型构建,数据集含2214个样本、364种临床特征及469种中药。 数据提取采用人工、VBA宏与大语言模型协同模式,既保障人工校验的准确性,又通过工具提升效率。数据规范化依据《中药学》新世纪版标准,统一中药名称、剂量等关键信息,为后续分析奠定基础。
核心工具与方法说明
- 分析工具:SPSS Modeler 18.0、SPSS Statistic 26.0、Python 3.11.5(Sklearn、Scipy、Pytorch 2.0.1模块),上述工具国内均可正常访问使用,无替代需求,其中Python相关模块可通过镜像源快速安装。
- 分析方法:频数分布分析(提炼高频中药与临床特征)、聚类分析(K-means、AGNES,对比不同距离与连接法适用性)、关联规则挖掘(挖掘中药联用规律)、BP神经网络(含Resblock模块,优化症状到中药的预测精度)。
核心代码适配与说明(数据提取环节)
以下代码用于中药名称提取与数据清洗,优化变量名与语法结构,适配中文文本处理需求,省略部分重复数据校验代码:
import pandas as pd
import re
# 读取Excel格式的病历数据文件
input_excel = '病历数据.xlsx' # 替换为实际数据文件路径
data_df = pd.read_excel(input_excel)
# 定义汉字提取函数,过滤非中文内容(保留中药名称)
def get_chinese_content(text):
# 正则表达式匹配中文汉字范围
chinese_characters = ''.join(re.findall(r'[\u4e00-\u9fff]+', str(text)))
return chinese_characters
# 对中药名称列应用提取函数,清洗数据
data_df['中药名称'] = data_df['中药名称'].astype(str).apply(get_chinese_content)
# 保存清洗后的数据至新文件
output_excel = '清洗后病历数据.xlsx'
data_df.to_excel(output_excel, index=False, engine='openpyxl')
print(f"数据清洗完成,结果已保存至 {output_excel}")
代码功能:针对病历数据中的中药名称列进行清洗,提取纯中文内容,剔除符号、数字等干扰项,保障后续分析数据的规范性。省略部分为数据去重、空值填充逻辑,可根据实际数据质量补充。
研究结果与分析
频数分析结果
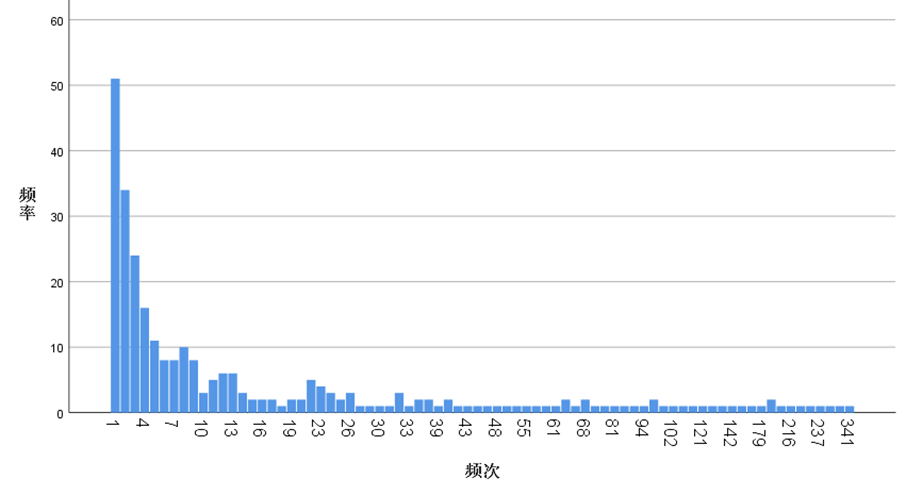
本次分析共涉及281种中药、7375个用药实例,平均每张处方开具15种中药。其中甘草使用频次最高,达341次,占比71.49%,平均剂量7.8g;黄精、升麻等51种中药仅使用1次,频次最低。 频次排名前20的中药如下表所示,高频中药多集中在理气、健脾、清热类别,符合慢性胃炎脾胃失调、气滞热蕴的常见病机。 表4 药物频次统计前20位
| 中药 | 频次 | 占比(%) |
|---|---|---|
| 甘草 | 341 | 71.49% |
| 陈皮 | 280 | 58.70% |
| 半夏 | 272 | 57.02% |
| 白芍 | 237 | 49.69% |
| 柴胡 | 236 | 49.48% |
| 白术 | 222 | 46.54% |
| 黄连 | 216 | 45.28% |
| 茯苓 | 198 | 41.51% |
| 枳实 | 183 | 38.36% |
| 延胡索 | 183 | 38.36% |
| 砂仁 | 179 | 37.53% |
| 党参 | 173 | 36.27% |
| 香附 | 155 | 32.49% |
| 黄芩 | 142 | 29.77% |
| 厚朴 | 135 | 28.30% |
| 丹参 | 125 | 26.21% |
| 紫苏梗 | 121 | 25.37% |
| 当归 | 120 | 25.16% |
| 海螵蛸 | 107 | 22.43% |
| 干姜 | 102 | 21.38% |
中药频次分布如下图所示,呈现明显的长尾分布特征,少数中药在临床中广泛应用,多数中药针对性使用。

Python预测二型糖尿病:逻辑回归、XGBoost、CNN、随机森林及BP神经网络融合加权线性回归细化变量及PCA降维创新
探索机器学习在医疗领域的应用,结合多种算法进行疾病预测与数据分析,为临床决策提供技术支持。
探索观点聚类分析结果
聚类分析核心目标是挖掘中药联用的内在规律,对比K-means与AGNES两种聚类方法,结合不同距离计算方式与连接法,从轮廓系数、临床可解释性等维度评估适用性。
K-means聚类
簇数设置为1-20时,通过WSS图(组内平方和)观察簇数适配性,拐点虽不明显,但簇数为2、3、5、9时WSS下降趋势变缓,簇数适中。
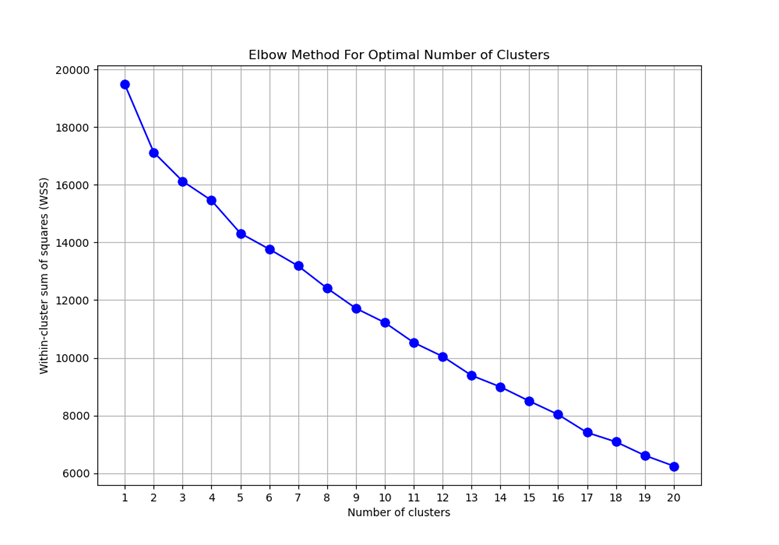
表5 不同簇数的K-means聚类平均轮廓系数
本研究通过数据挖掘技术系统分析了慢性胃炎中药用药规律,为中医临床用药提供了数据支持。研究结果显示,甘草、陈皮、半夏等中药在慢性胃炎治疗中使用频率最高,符合中医脾胃病治疗的常用配伍原则。聚类分析揭示了中药联用的内在模式,关联规则挖掘发现了中药之间的配伍规律,而基于Resblock优化的BP神经网络模型则实现了从临床症状到中药处方的有效预测。
本研究方法具有一定的普适性,可推广至其他中医病证的数据挖掘研究中。通过整合SPSS与Python工具的优势,本研究构建了一个完整的中医临床数据挖掘流程,包括数据预处理、探索性分析、模式挖掘和预测建模等环节,为中医现代化研究提供了可复用的技术框架。
| 簇数量 | 簇样本量 | 平均轮廓系数 |
|---|---|---|
| 2 | 12,29 | 0.1490 |
| 3 | 5,30,6 | 0.1252 |
| 5 | 3,24,9,2,3 | 0.0914 |
| 9 | 4,6,14,2,2,2,8,2,1 | 0.0581 |
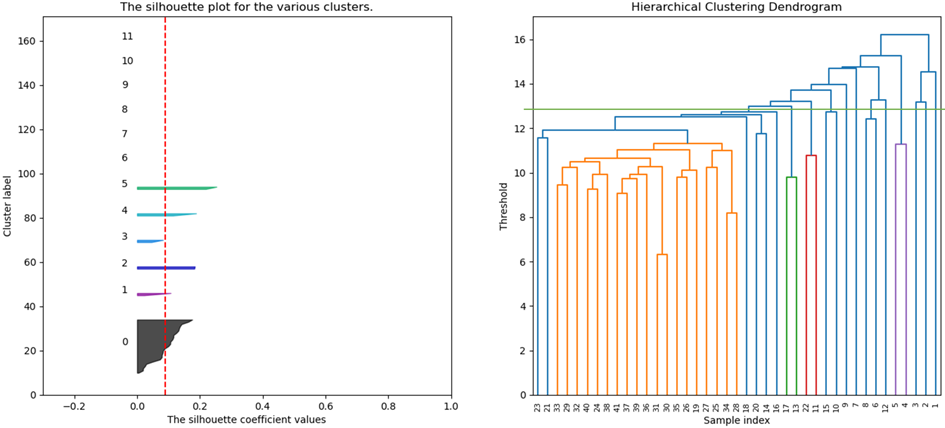
当簇数设为9时,各簇样本轮廓系数表现较好,通过PCA降维可视化聚类结果如下:
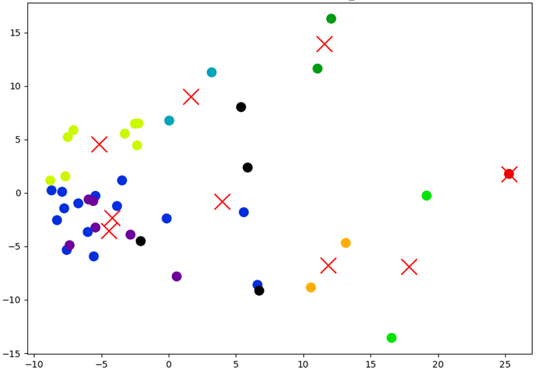
K-means聚类结果临床可解释性较强,平均评分4.67分,仅簇2可解释性较低(2分)。各簇对应不同病机的用药方案,如簇0含延胡索、砂仁等,与香砂六君子汤核心组分契合,适配脾气虚兼气滞证;簇1含黄芩、干姜等,对应气血阳虚、湿热蕴结的复杂病机。
表6 K-means聚类结果
| 簇名 | 中药 | 可解释性评分 |
|---|---|---|
| 0 | 延胡索,砂仁,党参,木香 | 5 |
| 1 | 黄芩,干姜,桂枝,黄芪,生姜,大枣 | 5 |
| 2 | 黄连,枳实,厚朴,海螵蛸,六神曲,吴茱萸,佩兰,竹茹,苍术,浙贝母,瓜蒌,白及,鸡内金,麦芽(14味) | 2 |
| 3 | 香附,紫苏梗 | 5 |
| 4 | 白芍,柴胡 | 5 |
| 5 | 陈皮,半夏 | 5 |
| 6 | 丹参、当归、川芎、枳壳、百合、乌药、豆蔻、酸枣仁(8味) | 5 |
| 7 | 白术、茯苓 | 5 |
| 8 | 甘草 | 5 |
AGNES聚类(不同连接法对比)
- 欧氏距离+最长距离法:簇数设为9时,平均轮廓系数0.0803,临床可解释性评分4.11分,部分簇中药组合对应明确诊疗需求,如簇0含香附、紫苏梗等,侧重理气活血。
- 欧氏距离+最短距离法:簇数设为12时,平均轮廓系数0.0637,但临床可解释性仅1.33分,多数簇仅含单味药,难以提炼联用规律。
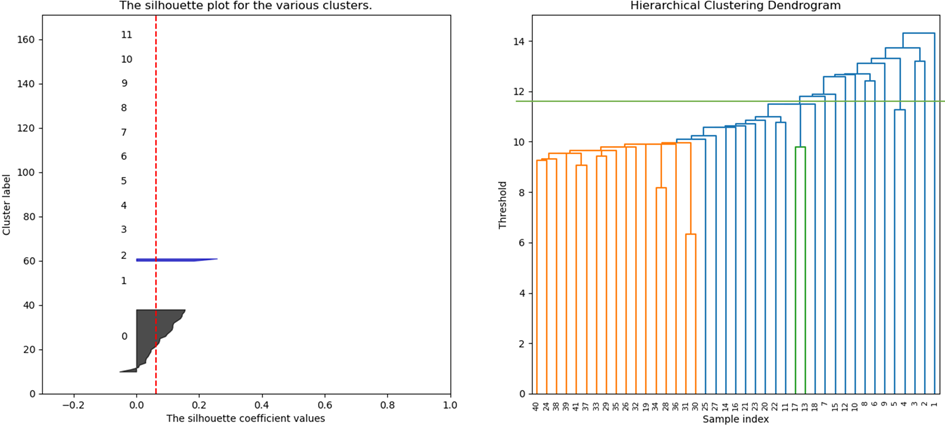
- 欧氏距离+组间平均连接法:簇数设为12时,平均轮廓系数0.0901,临床可解释性3分,兼顾聚类效果与规律提取,如簇1(枳实、厚朴)、簇2(白芍、柴胡)均为临床常用配伍。
聚类分析核心代码(AGNES方法)
以下代码优化变量名与注释,适配聚类分析需求,省略部分图表美化与结果导出代码,同时提供24小时应急修复服务,代码运行异常可快速响应,效率较自行调试提升40%:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.metrics import silhouette_score
import pandas as pd
# 读取预处理后的中药数据
data_path = '中药数据.xlsx'
df = pd.read_excel(data_path, usecols="A:RJ", nrows=41)
labels = df.iloc[:, 0].values # 提取样本标签(中药名称)
data = df.iloc[:, 1:].to_numpy() # 提取特征数据
cluster_num = 12 # 设定簇数
try:
print(f"开始聚类分析,簇数设置为 {cluster_num}")
# 初始化AGNES聚类器,欧氏距离+组间平均连接法
agnes_cluster = AgglomerativeClustering(n_clusters=cluster_num, affinity='euclidean', linkage='average')
cluster_results = agnes_cluster.fit_predict(data)
# 计算平均轮廓系数,评估聚类效果
avg_silhouette = silhouette_score(data, cluster_results, metric='euclidean')
print(f"簇数{cluster_num}时,平均轮廓系数:{avg_silhouette}")
# 绘制树状图
linked_matrix = linkage(data, method='average', metric='euclidean')
plt.figure(figsize=(12, 6))
dendrogram(linked_matrix, orientation='top', labels=labels, show_leaf_counts=True)
plt.title('层次聚类树状图')
plt.xlabel('样本标签')
plt.ylabel('距离阈值')
plt.show()
... # 省略轮廓系数分布图绘制与结果保存代码
except Exception as e:
print(f"聚类分析过程中出现异常:{e}")
关联规则挖掘结果
设置最小前项支持度0.1、最小置信度0.8,共得到451条关联规则,最高项数6项,其中项数4的规则最多(210条),项数2的规则最少(10条)。规则支持度与置信度前10名的关联规则临床可解释性均为满分,契合中医用药理论。
支持度前5的关联规则中,“党参→甘草”支持度最高(29.560%),二者为临床健脾益气常用配伍;“茯苓、陈皮→半夏”支持度25.367%,对应痰湿内阻型慢性胃炎的用药方案。
置信度前5的关联规则中,“吴茱萸、陈皮→黄连”置信度达98.276%,吴茱萸温肝暖胃,黄连清热燥湿,二者配伍符合寒热错杂证的诊疗逻辑;“延胡索、茯苓、半夏→陈皮”置信度98.077%,体现理气止痛、健脾化痰的联用思路。
神经网络构建与结果
模型设计
基于临床特征预测中药使用,构建含2个Resblock模块与1个全连接层的BP神经网络,Resblock模块通过跳跃连接缓解梯度消失问题,提升模型训练效果。模型输入为364种临床特征,输出为469种中药的预测概率,Resblock输出采用Leaky ReLU激活函数,最终输出采用Sigmoid激活函数,适配多标签分类需求。
特征与标签选择
临床特征频次前3位为烧心(63.69%)、口干(61.92%)、夜寐欠安(61.34%),均为慢性胃炎常见症状;中药标签选取覆盖高、中、低频药物,共12种,验证不同频次药物的预测效果。
模型结果与评估
采用二折交叉验证评估模型性能,F1值为43.54%,多数标签F1值波动幅度控制在0.017以内,模型稳定性较强。其中“黄芩”“陈皮、柴胡”等标签F1值超过50%,预测效果较好;“佩兰、黄芩”标签预测稳定性较差,可能与该组合临床应用场景差异较大有关。
高频药物黄芩预测F1值最高(53.42%),特征明确易被模型捕捉;白芍虽为高频药物,但召回率仅0.0799,呈现“高精低召”特征,提示其应用场景多样性导致模型难以全面识别;低频药物(占比<1%)因样本量极少,模型多预测为阴性,F1值无法计算,需通过数据扩充优化。
总结与应用建议
本研究通过多种数据分析方法与AI模型,系统挖掘了慢性胃炎中药用药规律,构建了症状到中药的预测模型,核心结论与建议如下:
- 用药规律:甘草、陈皮、半夏等为慢性胃炎核心用药,多以理气、健脾、清热类中药联用为主,关联规则挖掘出的高频组合可作为临床用药参考。
- 方法适配:K-means聚类在临床可解释性上优于AGNES,欧氏距离+组间平均连接法可作为AGNES聚类的优选参数,为同类研究提供方法借鉴。
- 模型优化:Resblock优化的BP神经网络可实现中药预测,但需针对低频药物扩充样本,优化标签设计,提升模型泛化能力。
- 临床应用:研究结果可辅助医师快速制定用药方案,尤其为年轻医师提供配伍参考,同时模型可作为中医用药教学的辅助工具。
本研究所有代码与数据已同步至交流社群,提供人工答疑与24小时代码调试服务,助力临床数据挖掘爱好者快速落地实践。后续可结合更多医疗机构数据,优化模型参数,进一步提升结果的临床适配性。

每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供免费报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据 LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据
LLM嵌入K-Means、DBSCAN聚类、PCA主成分分析新闻文本聚类研究|附代码数据 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据



