分类树的一个常见用途是预测抵押贷款申请人是否会拖欠贷款。
数据包含对 5,960 名抵押贷款申请人的观察结果。
一个名为的变量 Bad 表示申请人在获得贷款批准后是还清贷款还是拖欠贷款。
可下载资源
此示例构建一个树模型,该模型用于对数据进行评分,并可用于对有关新申请人的数据进行评分。
决策树(decision tree)算法是根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确地分类,本质是从训练集中归纳出一组分类规则。决策树生成方法包括ID3、C4.5及CART等。
优点:
-
易于理解和解释,决策树可以可视化。
-
几乎不需要数据预处理。其他方法经常需要数据标准化,创建虚拟变量和删除缺失值。决策树还不支持缺失值。
-
使用树的花费(例如预测数据)是训练数据点(data points)数量的对数。 可以同时处理数值变量和分类变量。其他方法大都适用于分析一种变量的集合。
-
可以处理多值输出变量问题。 使用白盒模型。如果一个情况被观察到,使用逻辑判断容易表示这种规则。相反,如果是黑盒模型(例如人工神经网络),结果会非常难解释。
-
即使对真实模型来说,假设无效的情况下,也可以较好的适用。
缺点:
-
决策树学习可能创建一个过于复杂的树,并不能很好的预测数据(过拟合)。
-
决策树可能是不稳定的,因为即使非常小的变异,可能会产生一棵完全不同的树。
-
难以产生一棵全家最优的决策树。对样本和特征随机抽样可以降低整体效果偏差。
-
如果某些分类占优势,决策树将会创建一棵有偏差的树。因此,在训练之前,需要先抽样使样本均衡。
适用数据类型:数值型和标称型。
数据变量
表 :数据表中的变量
| 变量 | 类型 | 等级 | 描述 |
|---|---|---|---|
Bad | 因变量 | 二进制 | 1 = 申请人拖欠贷款或严重拖欠贷款 |
| 0 = 申请人还清贷款 | |||
CLAge | 预测变量 | 区间 | 最长信用额度的月龄 |
CLNo | 预测变量 | 区间 | 信用额度数量 |
DebtInc | 预测变量 | 区间 | 债务收入比 |
Delinq | 预测变量 | 区间 | 拖欠信用额度的数量 |
Derog | 预测变量 | 区间 | 重大贬损报道数量 |
Job | 预测变量 | 标称 | 职业类别 |
Loan | 预测变量 | 区间 | 申请贷款金额 |
MortDue | 预测变量 | 区间 | 抵押贷款到期金额 |
nInq | 预测变量 | 区间 | 近期信用查询次数 |
Reason | 预测变量 | 二进制 | DebtCon = 债务合并 |
HomeImp = 家庭改善 | |||
Value | 预测变量 | 区间 | 财产价值 |
YoJ | 预测变量 | 区间 | 目前工作年限 |
加载数据
树模型的因变量是 Bad,一个有两个值的分类变量(0 代表贷款支付,1 代表违约)。其他变量是模型的预测变量。以下语句将数据加载到会话中并显示数据表的前 10 个观察值。
/* 将变量名称转换为混合大小写 */ data my.hm; length Bd oan Motue Value 8 Reason Job $7
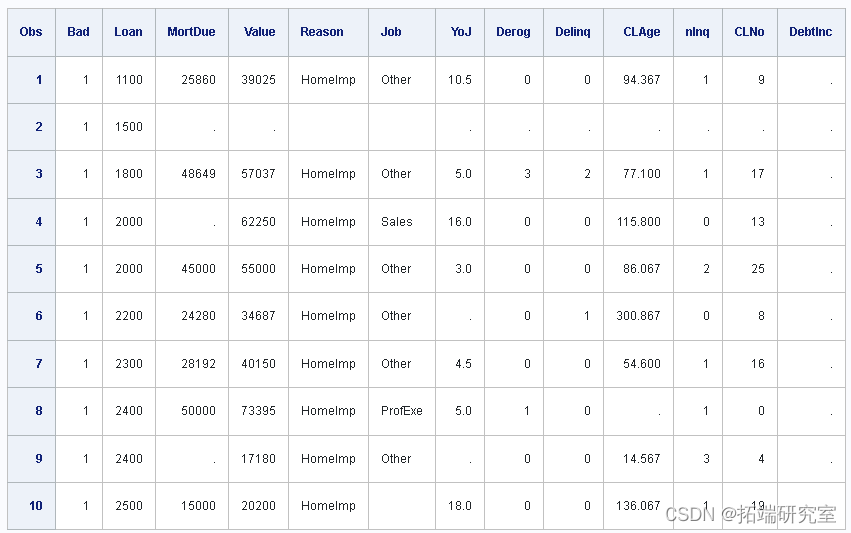
显示 的前 10 个观测值。
输出数据的部分列表
创建分类决策树
以下语句创建分类树:
proc maxdepth=5; model Bad = Dei o JbIq as LAeL DtInLa Mrue ae J; prune costcomplexity;
这 MAXDEPTH= 选项指定要生长的树的最大深度为 5。
Bad 在等号左侧 指定 MODEL 语句表明它是因变量。
因为没有包含 GROW 语句,所以 PROC TREEPLIT 默认使用熵度量,它计算增长树的增益。这 PRUNE 语句要求进行成本复杂性修剪。
这 PARTITION 声明要求将观察结果 Hmeq 划分为不相交的子集以进行模型训练和验证。随机选择观测值作为验证子集,概率为 0.3;为训练子集选择剩余的观察值。
FILE= 选项 CODE 语句请求将 SAS DATA 步得分代码保存到名为 trc.sas.
树形图
最终树的概览图
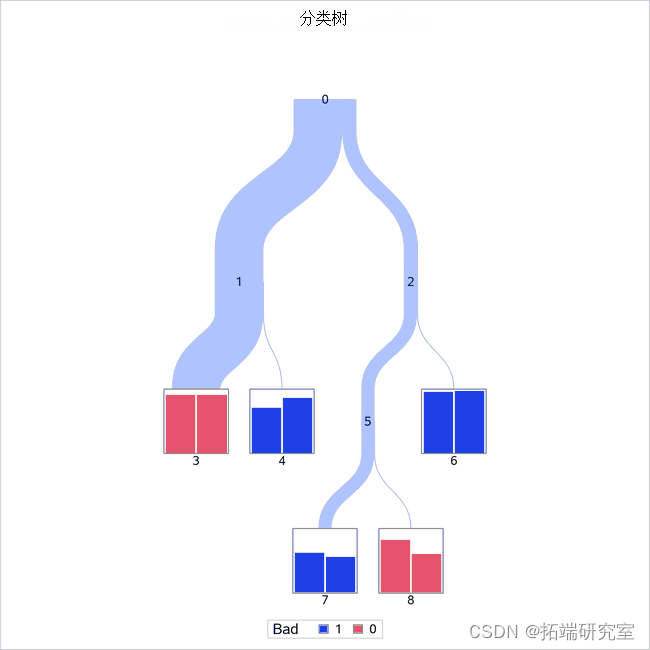
如绘图图例中的颜色所示,为终端节点中的观察分配了 Bad=0 或 =1 的预测。叶节点中的第一个条形显示与训练分区中=0 或 =1Bad的预测相匹配的因变量的比例, 叶节点中的第二个条形显示与验证分区中匹配的因变量的比例。线的粗细表示哪些节点具有更多的总观测值。
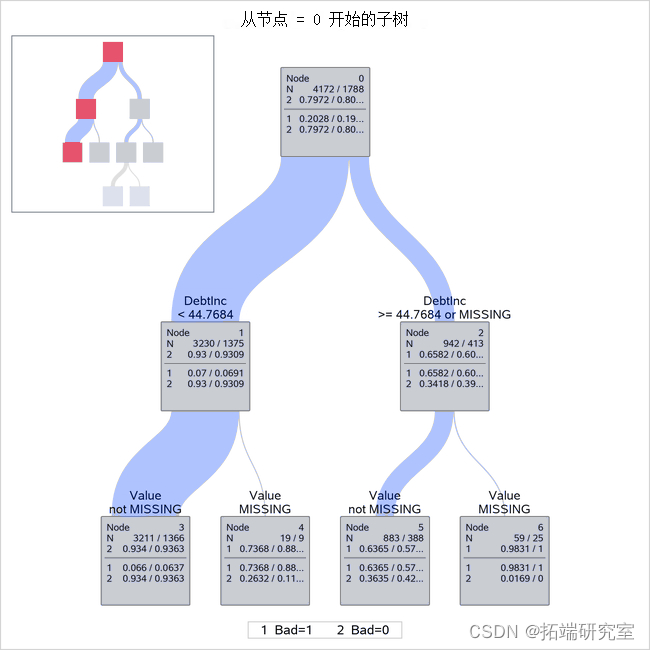
树形图在是树顶部的详细视图。

详细树形图
随时关注您喜欢的主题
默认情况下,此视图提供有关树的前三个级别的详细拆分信息,包括根级别。每个节点上方的拆分规则显示拆分变量和拆分值;该规则确定来自父节点的哪些观察值包含在节点中。节点内表的第一行提供节点标识符。第二行提供训练观察的数量,后跟反斜杠,然后是验证观察的数量。如果在该点发生分类,第三行显示该节点中观察的预测因变量,以及训练观察与观察到的因变量的比例。这通过反斜杠与验证观察的比例分开。
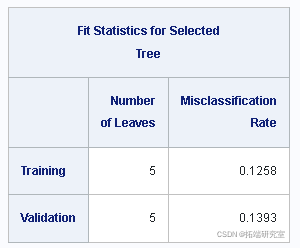
显示最终树的拟合统计量
输出 :树性能
树分裂程序
显示修剪图
修剪图
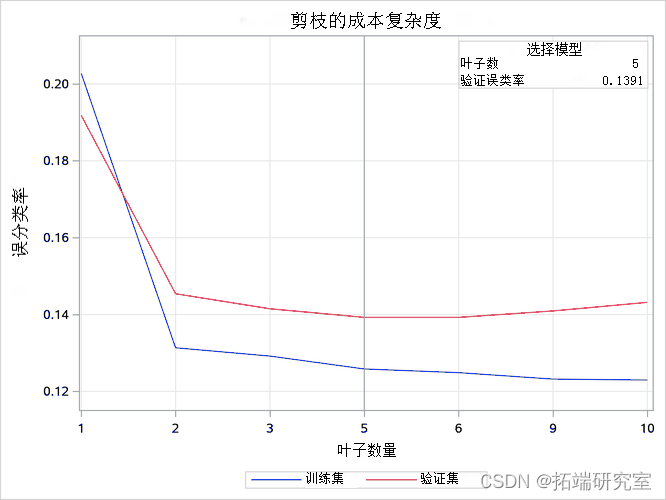
此图显示修剪树时训练和验证数据的错误分类率。垂直线显示选定的最终树,它对验证数据具有最低的误分类率。
创建评分代码并对新数据进行预测评分
除了查看有关树模型的信息之外,您可能有兴趣应用该模型来预测因变量未知的其他数据表中的因变量。您可以运行 SAS DATA 步代码对新数据进行评分。以下是示例:
data scd; set smo.hq; %include 'tc.sas'; run;
显示 的部分列表 。
输出 :评分 数据的部分列表

数据表包含由分数代码创建的 13 个原始变量和 4 个新变量。变量 PA1 是这片叶子中训练观察的比例 BAD=1;这个变量可以解释为违约概率。该变量 IAD 表示观测值的 BAD 预测值。
您可以使用前面的语句对新数据进行评分,方法是在 SET 语句中包含新数据表 。新数据表必须包含与用于构建树模型的数据相同的变量,但不能包含您现在要预测的未知因变量。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载



