本文主要介绍了如何帮助客户通过读取数据、查看部分数据、转换数据为因子并将数值变量归一化、进行描述性分析、建立knn模型等步骤对数据进行分析。
通过分别选择不同的k值进行建模,并对比它们的准确度,找到最优的参数k。
文章还介绍了如何扩大参数的范围,找到最优的k值,并绘制数据的散点图,查看每个分类的分布情况。
可下载资源
通过图表分析,得出了模型的预测点和实际点的符合程度较好的结论。
读取数据
credit <- read.table("man.data")
查看部分数据
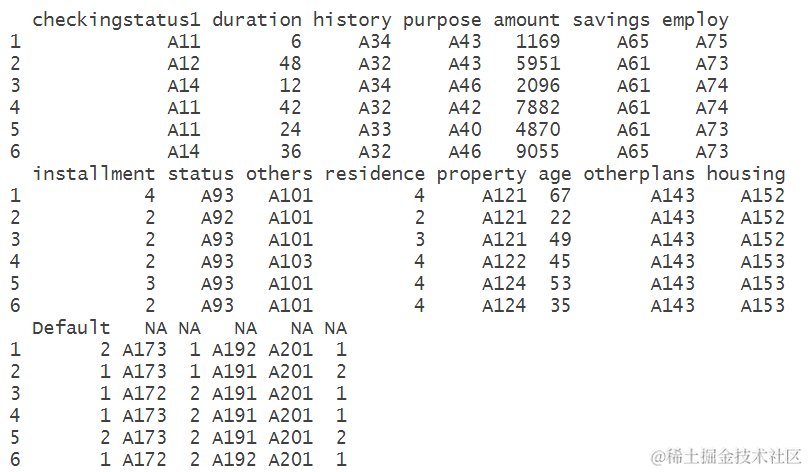
根据对数据集的命名和查看,可以看出数据集包含了多个变量,如checkingstatus1、duration、history等,这些变量代表了不同的个人和贷款信息。数据集的前几行展示了每个变量的取值情况,以及最后一列是目标变量”Default”,它表示了客户是否违约。这些信息对于理解数据集的结构和内容非常重要。在进一步的分析中,这些变量将被用于建立模型,以预测客户是否会违约。
转换数据为因子,并且将数值变量归一化
germalt <- factor(germanault)
gemadit[sapply(germt, is.numeric)] <- lapply(gerdit[sapply(germanit, is.numeric)], scale)
对数据进行描述性分析
summary(gerdit.subset)
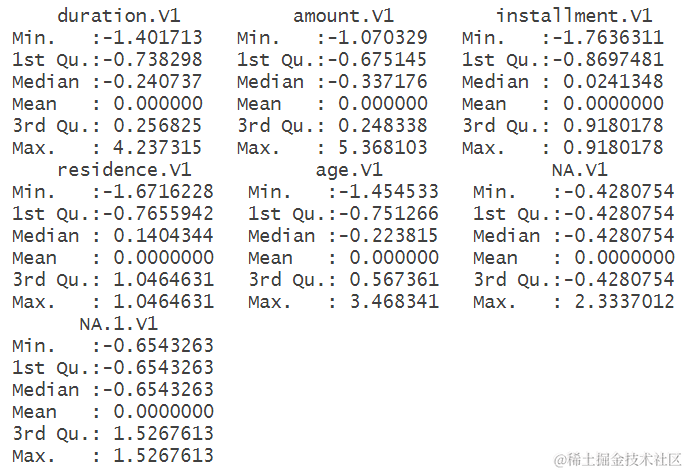
根据对数据进行描述性分析的结果,可以看出各个变量的分布情况。例如,duration.V1(借款周期)、amount.V1(借款金额)、installment.V1(分期付款)等变量的最小值、最大值、中位数和平均值等统计信息。通过这些统计信息,可以初步了解数据的范围和分布情况,为后续建模和分析提供基础。例如,可以看出借款周期和借款金额的方差较大,而分期付款的方差较小,这些信息对于理解数据的特点和规律具有重要意义。
knn模型
将数据分区,70%为训练集,30%为测试集,建立knn模型,然后对比模型的准确度
set.seed(111)
test <-sample(1:nrow(germ.subset),nrow(germubset)*0.2)
然后我们分别选取,不同的k作为knn模型的参数,得到模型的结果之后,对比它们的准确度,从而选出最优的参数k。
分别对不同的参数进行建模
knn.1 <- k train.def, k=1)
it, train.def, k=5)
kndef, k=20)
然后分别计算不同参数下的准确度:
## test.def
## knn.1 0 1
## 0 54 11
## 1 21 14
## [1] 0.535
## test.def
## knn.5 0 1
## 0 62 13
## 1 13 12
## [1] 0.545
## test.def
## knn.20 0 1
## 0 69 13
## 1 6 12
## [1] 0.605
从不同的近邻数的结果来看,我们可以发现当参数为二十的时候,模型的准确率最高为0.605。
因此我们可以认为最优的knn参数是20。
扩大参数的范围,使参数从2到30变化,并分别计算不同参数下的准确度,从而找到最优的参数。
随时关注您喜欢的主题
acc=numeric(0)
for(k in 2:30){
plot(acc,type="b",col="blue")
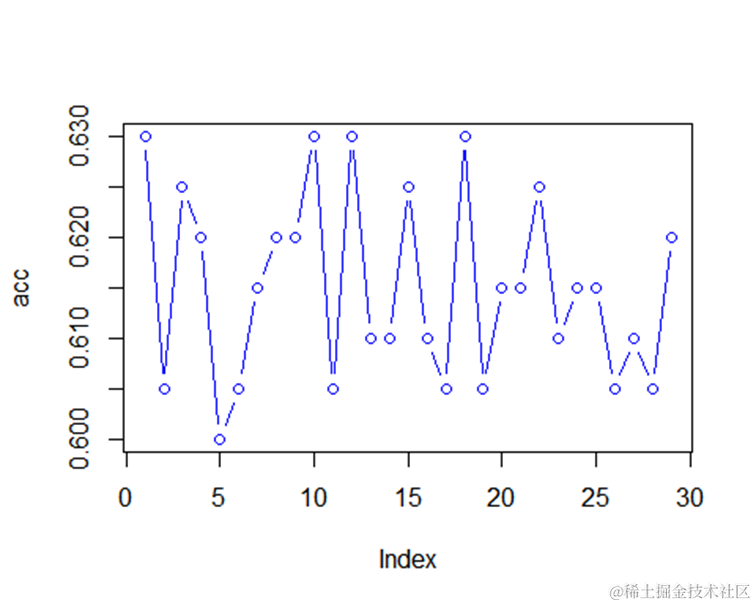
#查看最优k
which.max(acc)+1
## [1] 2
因此,最优的k为2。
绘制数据的散点图,查看每个分类的分布情况
plot(train.germancredit[,c("amount","duration")],
图中四种颜色的点分别表示以下四个种类的用户:
图中的圆形和三角形分别代表没有信贷的用户和有信贷的用户。实心点和空心点,分别代表着预测的数据和实际的数。从散点图的结果来看空心点和实心点的覆盖重合度较高,说明模型的预测点和实际点的符合程度较好。同时可以看到不同的客户,信用等级的分类出现了不同的分布情况。三角形代表信用较好的客户,他们的借款周期一般较短,借款金额也较少。而圆形的点代表没有信贷的用户,他们的借款周期较长,借款金额较大,存在信贷危机。

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据
Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据

