
这次,我们将使用k-Shape时间序列聚类方法检查与我们有业务关系的公司的股票收益率的时间序列。
在本研究中,我们将研究具有交易关系的公司的价格变化率的时间序列的相似性。
可下载资源
由于特定客户的销售额与供应商公司的销售额之比较大,当客户公司的股票价格发生变化时,对供应商公司股票价格的反应被认为更大。
时序数据的聚类分析不需要有标注的数据,人工成本低;通过聚类,可以发现数据中隐含的模式或相关性。因此,时序数据的聚类被广泛使用在各种场景。
由于时序数据的高度异质性,即包含噪声、缺失值、异常值,长度、采样率、变化速率不一,因此不能简单地视为高维向量,传统的基于欧式空间的聚类算法不能被直接利用。
聚类算法的好坏主要从两个方面来衡量:
-
准确性
-
效率
现有的聚类方法大致可以分为以下三类:
-
基于统计的聚类 这类方法从时序数据中抽取统计特征,如平均值、方差、倾斜度,以及一些高阶特征等,如ARIMA模型的系数、分形度量(fractal measures)等。或是划分窗口,在每个窗口内计算这些统计特征,再进行汇总。
-
基于形状的聚类 许多时序数据往往具有相同的变化模式(如上升、下降、上升等),因此可以根据这些时序数据的形状相似性将变化模式相似的序列聚在同一个类,可以忽略数据在整幅、时间尺度等的差异。 一些人工定义的距离(如DTW)具有尺度和平移不变性,因此被广泛用于基于形状的聚类。由于人工定义的距离是数据无关的,方便利用到各种领域的数据上,一个研究方向是定义新的距离度量,然后结合一个现成的聚类算法(k-means或层次化聚类等)。 这类方法中最先进的是[1], 该方法利用现有的距离度量的特性(scale-, translate-, and shift-invariant),提出了一种计算聚类中心的算法。
现有方法主要有两方面的缺点:
(1)时间复杂度高;
(2)易受到异常值、噪声的干扰
另一类是基于shapelets的方法[2,3],shapelets即一些短的序列,这些序列能够体现出整条序列的局部变化模式。 基于形状的聚类方法基本都有开源实现,python包tslearn中基本都包含了。3. 基于深度学习的聚类
该类方法主要基于autoencoder模型将时序数据转换为低维的隐空间,现有的变分自编码器(variational autoencoder)等虽然能够在一定程度上容忍噪声、异常值等。但目前存在两方面的不足:
-
缺乏一种通用的方法来捕获时序数据的特性,从而得到有效的隐空间。
-
在得到的隐空间中需要一种合适的相似性度量考虑时间上的特性。
目前最先进的方法是[4],该方法同时训练一个autoencoder和k-mean(基于KL散度的loss)。autoencoder模型中先用1D卷积,然后接一个双向的LSTM,因此考虑了时序数据的局部和时间上的特征,但这也是时序数据常用的处理套路。
目前基于静态数据(向量数据)的聚类算法也有一定的发展,主要可分为以下几类:
(1)联合优化stacked autoencoder和k-means目标[5-7]。其中k-mean目标是基于KL散度计算的。(论文[6]和[7]貌似发生了撞车 )
(2)将变分自编码器(VAE)和高斯混合模型(K个聚类对应K个高斯分量)结合[8]。
(3)同时训练K个autoencoders,每条数据根据哪个autoencoder得到的重建误差最小,该数据就属于哪个类[9,10]。(论文[9]和[10]貌似也发生了撞车 )
总结:基于深度学习的时序数据聚类还有较大的发展空间,目前基于静态数据的方法不能很好的考虑到时间序列在时间上的平移、伸缩等特性。
k-Shape
k-Shape [Paparrizos和Gravano,2015]是一种关注时间序列形状的时间序列聚类方法。在我们进入k-Shape之前,让我们谈谈时间序列的不变性和常用时间序列之间的距离测度。
时间序列距离测度
欧几里德距离(ED)和动态时间规整(DTW)通常用作距离测量值,用于时间序列之间的比较。
两个时间序列x =(x1,…,xm)和y =(y1,…,ym)的ED如下。

DTW是ED的扩展,允许局部和非线性对齐。
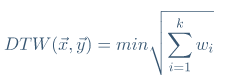
k-Shape提出称为基于形状的距离(SBD)的距离。
k-Shape算法
k-Shape聚类侧重于缩放和移位的不变性。k-Shape有两个主要特征:基于形状的距离(SBD)和时间序列形状提取。
SBD
互相关是在信号处理领域中经常使用的度量。使用FFT(+α)代替DFT来提高计算效率。
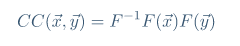
归一化互相关(系数归一化)NCCc是互相关系列除以单个系列自相关的几何平均值。检测NCCc最大的位置ω。
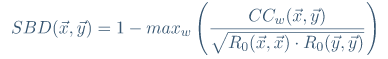
SBD取0到2之间的值,两个时间序列越接近0就越相似。
形状提取
通过SBD找到时间序列聚类的质心向量 。
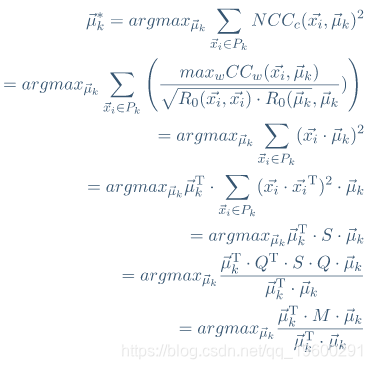
k-Shape的整个算法如下。
k-Shape通过像k-means这样的迭代过程为每个时间序列分配簇。
- 将每个时间序列与每个聚类的质心向量进行比较,并将其分配给最近的质心向量的聚类
- 更新群集质心向量
重复上述步骤1和2,直到集群成员中没有发生更改或迭代次数达到最大值。

R 语言k-Shape
> start <- "2014-01-01"
> df_7974 %>%
+ filter(date > as.Date(start))
# A tibble: 1,222 x 10
date open high low close volume close_adj change rate_of_change code
1 2014-01-06 14000 14330 13920 14320 1013000 14320 310 0.0221 7974
2 2014-01-07 14200 14380 14060 14310 887900 14310 -10 -0.000698 7974
3 2014-01-08 14380 16050 14380 15850 3030500 15850 1540 0.108 7974
4 2014-01-09 15520 15530 15140 15420 1817400 15420 -430 -0.0271 7974
5 2014-01-10 15310 16150 15230 16080 2124100 16080 660 0.0428 7974
6 2014-01-14 15410 15755 15370 15500 1462200 15500 -580 -0.0361 7974
7 2014-01-15 15750 15880 15265 15360 1186800 15360 -140 -0.00903 7974
8 2014-01-16 15165 15410 14940 15060 1606600 15060 -300 -0.0195 7974
9 2014-01-17 15100 15270 14575 14645 1612600 14645 -415 -0.0276 7974
10 2014-01-20 11945 13800 11935 13745 10731500 13745 -9缺失度量用前一个工作日的值补充。(K-Shape允许一些偏差,但以防万一)
每种股票的股票价格和股票价格变化率。
随时关注您喜欢的主题
将zscore作为“preproc”,“sbd”作为距离,以及centroid =“shape”,k-Shape聚类结果如下。
> df_res %>%
+ arrange(cluster)
cluster centroid_dist code name
1 1 0.1897561 1928 積水ハウス
2 1 0.2196533 6479 ミネベアミツミ
3 1 0.1481051 8411 みずほ
4 2 0.3468301 6658 シライ電子工業
5 2 0.2158674 6804 ホシデン
6 2 0.2372485 7974 任天堂Nintendo,Hosiden和Siray Electronics Industries被分配到同一个集群。Hosiden在2016年对任天堂的销售比例为50.5%,这表明公司之间的业务关系也会影响股价的变动。
另一方面,MinebeaMitsumi成为另一个集群,但是在2017年Mitsumi与2017年的Minebea合并, 没有应对2016年7月Pokemon Go发布时股价飙升的影响 。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据

