
贝叶斯分析的许多介绍都使用了相对简单的教学实例(例如根据伯努利数据给出成功概率的推理)。
虽然这可以很好地介绍贝叶斯原理,但是将这些原理扩展到回归并不是直接的。
可下载资源
这篇文章将概述这些原理如何扩展到简单的线性回归。我将导出感兴趣参数的后验条件分布,给出用于实现Gibbs采样器的R代码,并提出所谓的网格方法。
贝叶斯模型
假设我们观察数据
对于我们的模型是
Gibbs采样是一种特殊的马尔可夫链算法,常被用于解决包括矩阵分解、张量分解等在内的一系列问题,也被称为交替条件采样(alternating conditional sampling),其中,“交替”一词是指Gibbs采样是一种迭代算法,并且相应的变量会在迭代的过程中交替使用,除此之外,加上“条件”一词是因为Gibbs采样的核心是贝叶斯理论,围绕先验知识和观测数据,以观测值作为条件从而推断出后验分布。
简单来说,已知观测值为 ,给定一个带有参数的向量
,若
表示第
个参数
在第
次迭代的采样值,则该采样值随机地取自概率分布
.
[示例] 多元正态分布
问题描述:假设观测值 服从均值(未知)为
,协方差(已知)为
,且变量
服从均匀分布,如何利用Gibbs采样估计
?
在贝叶斯分析中,后验分布 通常被定义为
其中, 是先验分布,
是关于观测值的似然函数,符号
表示“正比于”。
因此,这里的后验分布为
尽管 可以直接通过这里的联合后验分布得到,但需要注意的是,Gibbs采样要求参数
和
在迭代过程中交替采样,即
[示例] Gibbs采样过程
假设协方差矩阵中的 ,观测值为
,并给定四个独立变量
,相应的初始值为
,
,
,
,如图1.
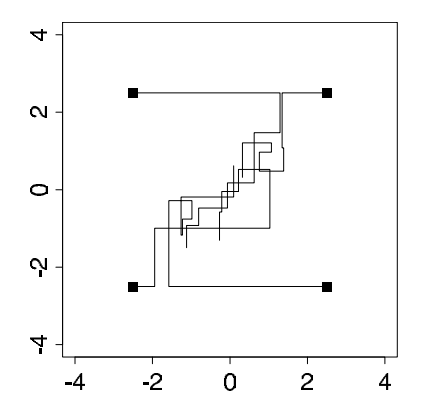
迭代500次后,参数 趋于收敛,如图2.
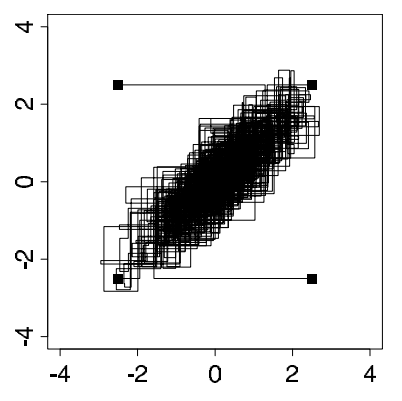
有趣的是推断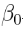
和
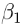
。如果我们将正态先验放在系数上,将反伽玛先验放在方差项上,则此数据的完整贝叶斯模型可以写为:
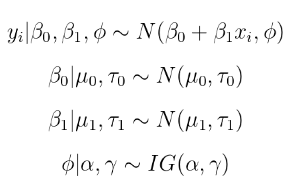
假设超参数是已知的,后验可以被写入到一个比例常数,
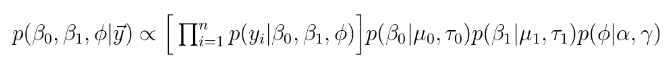
括号中的项是是数据的联合分布或概率。其他项包括参数的联合先验分布。
R代码从指定的“真实”参数模型生成数据。我们稍后将用这个数据估计贝叶斯回归模型来检查是否可以恢复这些真实的参数。
tphi<-rinvgamma(1, shape=a, rate=g)
tb0<-rnorm(1, m0, sqrt(t0) )
tb1<-rnorm(1, m1, sqrt(t1) )
tphi; tb0; tb1;
y<-rnorm(n, tb0 + tb1*x, sqrt(tphi))吉布斯采样器
要从这种后验分布中得出,我们可以使用Gibbs采样算法。吉布斯采样是一种迭代算法,从每个感兴趣的参数的后验分布生成样本。它通过以下方式从每个参数的条件后验分布依次得出的:
可以看出,剩下的1,000个样本是从后验分布中抽取的。这些样本不是独立的。每个步骤都取决于先前的位置。
条件后验分布
要使用Gibbs,我们需要确定每个参数的条件后验。
为了找到参数的条件后验,我们简单地删除不包含参数后验的所有项。例如,常数项条件后验:
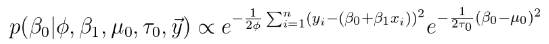
相似地,
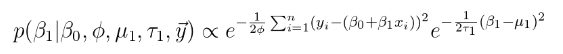
条件后验可以被认为是另一个逆伽马分布。
条件后验不那么容易识别。但是如果使用网格方法,我们不需要通过代数方法。
考虑网格方法。网格方法是暴力方法,从其条件后验分布进行抽样。这个条件分布只是一个函数
。所以我们可以评估密度
值。在R中,可以是grid = seq(-10,10,by = .001)。这个序列是点的“网格”。
那么在每个网格点评估的条件后验分布告诉我们这个抽样的相对概率。
然后,我们可以使用R中的sample()函数从这些网格中抽取,抽样概率与网格处的密度评估成比例。
for(i in 1:length(p) ){
p[i]<- (-(1/(2*phi))*sum( (y - (grid[i]+b1*x))^2 )) + ( -(1/(2*t0))*(grid[i] - m0)^2)
}
draw<-sample(grid, size = 1, prob = exp(1-p/max(p))) 
这在R代码的第一部分的函数rb0cond()和rb1cond()中实现。
使用网格方法时遇到数值问题是很常见的。由于我们在评估网格中未标准化的后验,因此结果可能会变得相当大或很小。可能会在R中产生Inf和-Inf值。
例如,在函数rb0cond()和rb1cond()中,我实际上评估了条件后验分布的对数。然后,我进行归一化和对数化。
我们不需要使用网格方法来从后验条件抽样,因为它来自已知的分布。
请注意,这种网格方法有一些缺点。
首先,这在计算上是复杂的。通过代数,希望得到一个已知的后验分布,从而在计算上更有效率。
其次,网格方法需要指定网格点的区域。如果条件后验在我们指定的[-10,10]的网格区间之外具有显着的密度,在这种情况下,我们不会从条件后验得到准确的样本。并且需要广泛的网格区间进行实验。所以,我们需要灵活地处理数字问题,例如在R中接近Inf和-Inf值的数字。
仿真结果
现在我们可以从每个参数的条件后验进行采样,我们可以实现Gibbs采样器。
iter<-1000
burnin<-101
phi<-b0<-b1<-numeric(iter)
phi[1]<-b0[1]<-b1[1]<-6 随时关注您喜欢的主题
结果很好。下图显示了1000个吉布斯(Gibbs)样本的序列。红线表示我们模拟数据的真实参数值。第四幅图显示了截距和斜率项的后验联合分布,红线表示等高线。
z <- kde2d(b0, b1, n=50)
plot(b0,b1, pch=19, cex=.4)
contour(z, drawlabels=FALSE, nlevels=10, col='red', add=TRUE)
总结一下,我们首先推导了一个表达式,用于参数的联合分布。然后我们概述了从后验抽取样本的Gibbs算法。在这个过程中,我们认识到Gibbs方法依赖于每个参数的条件后验分布,这是容易识别的已知的分布。对于斜率和截距项,我们决定用网格方法来规避代数方法。这样做的好处是我们可以绕开很多代数运算。代价是增加了计算复杂性。
 Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据
Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据 Python用PSO优化SVM与RBFN在自动驾驶系统仿真、手写数字分类应用研究
Python用PSO优化SVM与RBFN在自动驾驶系统仿真、手写数字分类应用研究



