
我们已经看到了如何考虑风险敞口,计算包含风险敞口的多个数量(经验均值和经验方差)的非参数估计量。让我们看看如果要对二项式变量建模。
让我们看看如果要对二项式变量建模。
可下载资源
这里的模型如下:
- 未观察到
- 索偿的数量

考虑一种情况,其中关注变量不是索偿的数量,而仅仅是索偿发生的标志。然后,我们希望将事件模型
逻辑回归算法是机器学习分类算法中的一种,是广义线性回归模型 。该算法常用于二分类或多分类问题。在数据挖掘、经济预测、医疗疾病的自动诊断等领域经常会被应用。
假定自变量X与因变量Y,逻辑回归用来描述因变量Y与自变量X的关系,最后预测因变量Y。具体步骤如下:
(1) 首先需要找一个合适的预测函数,表示为h函数,该函数是我们要找的分类函数,也是预测输入数据的判断结果 。利用Sigmoid函数和线性回归函数可以得出h函数。
Sigmoid函数:
(1)
线性回归函数公式为:
(2)
利用(1)与(2)式可以得到h函数如下:
(3)
(2) 构建能够描述模型预测值 与真实值y之间的偏差函数 ,称为代价函数。代价函数求平均值记作 ,一个模型的优劣可以通过 来行判断,当 函数越小,表明当前模型与参数更适合训练样本。基于最大似然估计可以达到 :
(4)
(3) 求 的最小值使用梯度下降法,使用梯度下降法来求最小值是常用的方法。各个参数的偏导数就是 的梯度,机器学习的过程中参数下降的方向就是偏导数的方向,学习率用 表示,通过偏导数使用梯度下降法求出使 最小的 ,在对参数进行更新。推导后可得出 如下:
(5)
这意味着在一年的前六个月中没有索赔的概率是一年中没有索赔的平方根。假设可以

现在,因为我们确实观察到
我们有
我们将使用的数据集
> T1= contrat$nocontrat[I==FALSE]
> nombre2 = data.frame(nocontrat=T1,nbre=0)
> sinistres = merge(contrat,nombre)
> sinistres$nonsin = (sinistres$nbre==0)我们可以考虑的第一个模型基于标准的逻辑回归方法,即
很好,但是很难用标准函数处理。尽管如此,始终有可能通过数值计算给定的最大似然估计量
> optim(fn=logL,par=c(-0.0001,-.001),
+ method="BFGS")
$par
[1] 2.14420560 0.01040707
$value
[1] 7604.073
$counts
function gradient
42 10
$convergence
[1] 0
$message
NULL
现在,让我们看看基于标准回归模型的替代方案。例如对数线性模型(Logistic回归算法)。因为暴露数是年概率的幂,所以如果
现在,我们对其进行编码,
Error: no valid set of coefficients has been found: please supply starting values尝试了所有可能的方法,但是无法解决该错误消息,
> reg=glm(nonsin~ageconducteur+offset(exposition),
+ data=sinistresI,family=binomial(link="log"),
+ control = glm.control(epsilon=1e-5,trace=TRUE,maxit=50),
+ start=startglm,
+ etastart=etaglm,mustart=muglm)
Deviance = NaN Iterations - 1
Error: no valid set of coefficients has been found: please supply starting values所以我决定放弃。实际上,问题出在
其中
在这里,暴露数不再显示为概率的幂,而是相乘。如果我们考虑对数链接函数,那么我们可以合并暴露数的对数。
现在可以完美运行了。
现在,要查看最终模型,我们回到Poisson回归模型,因为我们确实有概率模型
现在我们可以比较这三个模型。我们还应该包括没有任何解释变量的预测。对于第二个模型(实际上,它运行时没有任何解释变量),我们运行
> regreff=glm((1-nonsin)~1+offset(log(exposition)),
+ data=sinistres,family=binomial(link="log"))预测
> exp(coefficients(regreff))
(Intercept)
0.06776376可与逻辑回归比较,
> 1-exp(param)/(1+exp(param))
[1] 0.06747777但是与泊松模型有很大的不同,
(Intercept)
0.07279295我们产生一个图表比较那些模型,
> lines(age,1-yml1,type="l",col="purple")
> abline(h=exp(coefficients(regreff)),lty=2)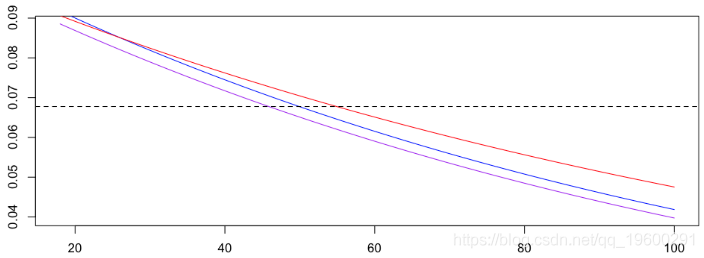
在这里观察到这三个模型是完全不同的。实际上,使用两个模型,可以进行更复杂的回归分析(例如使用样条曲线),以可视化年龄对发生或不发生交通事故概率的影响。如果将泊松回归(仍为红色)和对数二项式模型与泰勒展开进行比较,我们得到
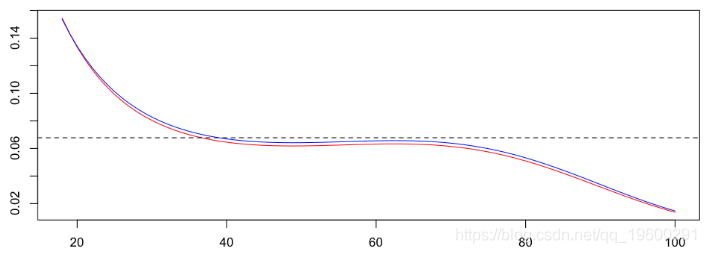
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据