在这篇文章中,我们将探讨基于随机森林模型的酒店收入和产量预测分析。
我们将使用4月9日至4月15日的数据作为测试集,评估预测的准确度。
我们将分别对单个酒店在三个预订渠道的总收入和总产量进行分析,并使用随机森林模型进行预测。
通过对比每家酒店的间夜预测值(或收入)与实际值的结果,以及产量排名前四分之一酒店的平均误差值,我们将得出对酒店收入和产量的有效预测和分析。
可下载资源

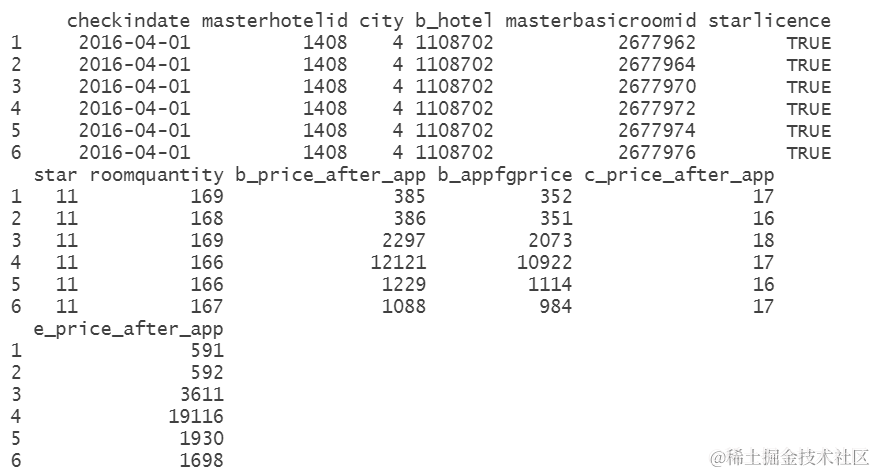
单酒店在三个预订渠道的 总收入
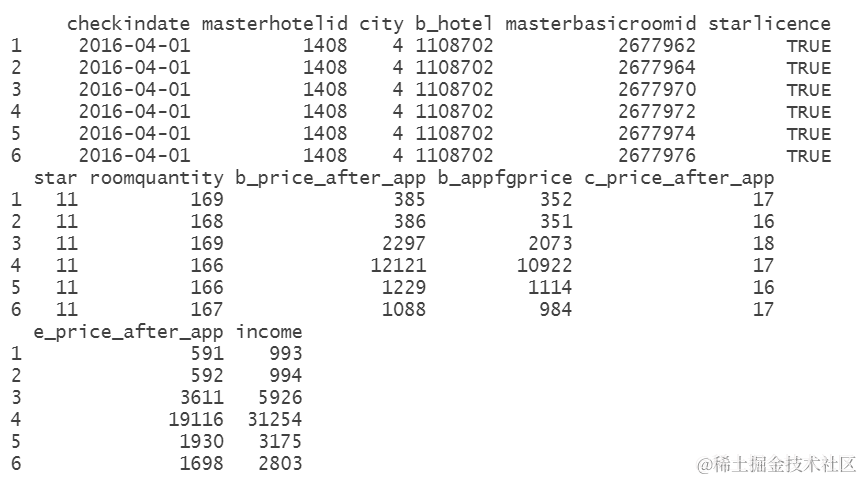
为了预测酒店的总收入,我们需要将来自三个不同预订渠道的收入相加。这一步骤对于训练集和测试集都需要进行。
data$income=data$b_price_after_app +data$c_price_after_app +data$e_price_after_app
test$income=test$b_price_after_app +test$c_price_after_app +test$e_price_after_app
随机森林预测识别的模型
接下来,我们将使用随机森林算法来建立预测模型。在此之前,我们需要对数据进行预处理,包括转换数据框格式、剔除缺失值等。
#转换数据,拟合随机森林模型
data=data.frame(data)
##剔除缺失数据
data=na.omit(data)
#建立随机森林
rfmodel = randva")

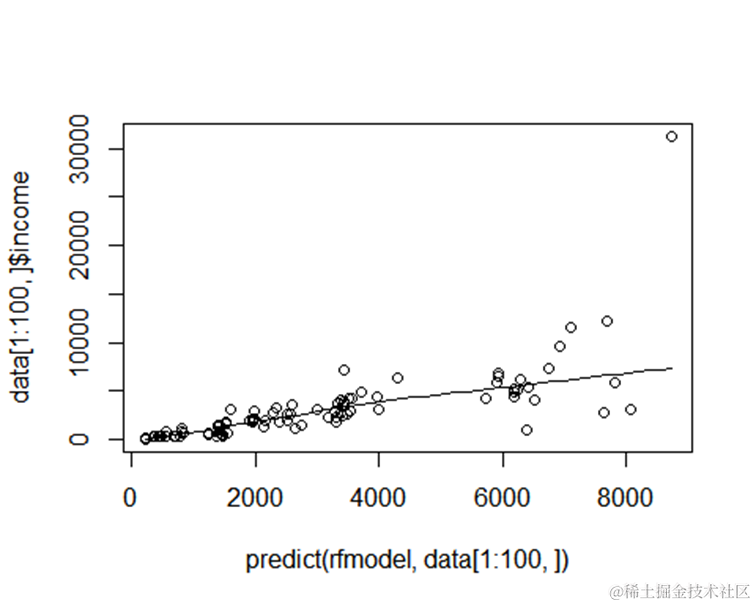
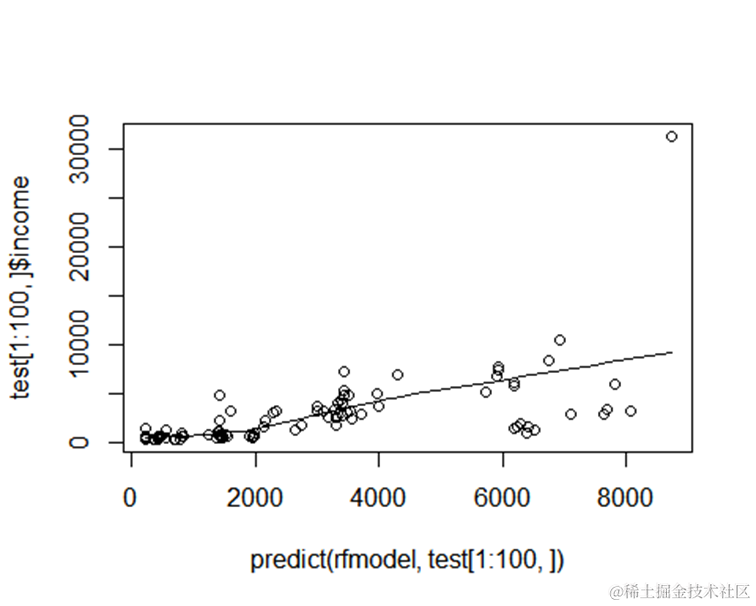
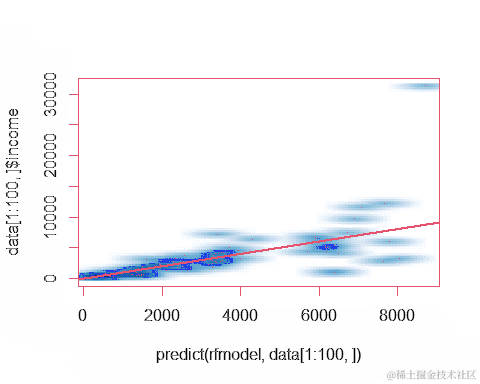
每家酒店的间夜预测值(或收入)与实际值的对比结果
完成模型的建立后,我们将使用测试集来评估模型的预测性能。通过对比每家酒店的预测收入与实际收入,我们可以了解模型的准确性。
随时关注您喜欢的主题
训练集
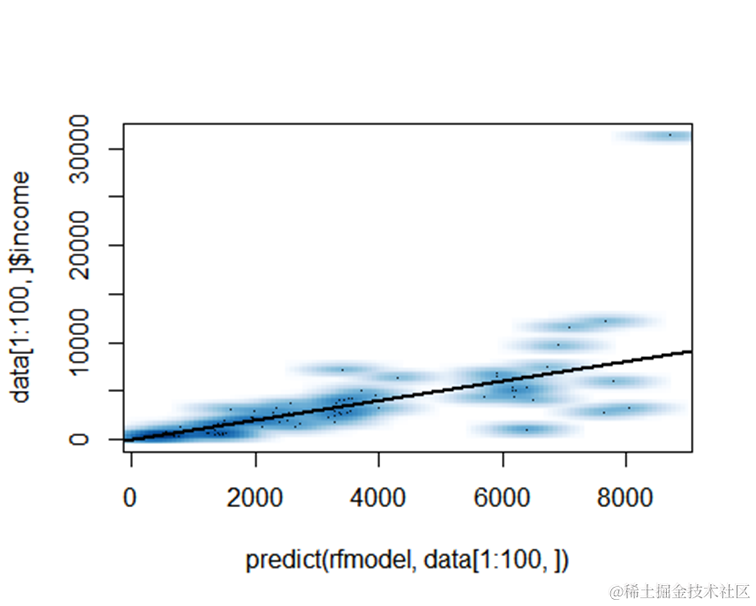
类似地,我们也可以预测酒店的产量,即每个酒店的总房间数。
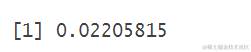
产量排名前四分之一酒店平均误差值

sum(abs(predict(rfmodel,test )-test$income)/test$income)/length( (test
单酒店在三个预订渠道的总产量
data$roomquantity=as.numeric(data$roomquantity)
test$roomquantity=as.numeric(test$roomquantity)
预测识别的模型方法代码
rfmodel = randst( roomquantit

每家酒店的间夜预测值(或收入)与实际值的对比结果
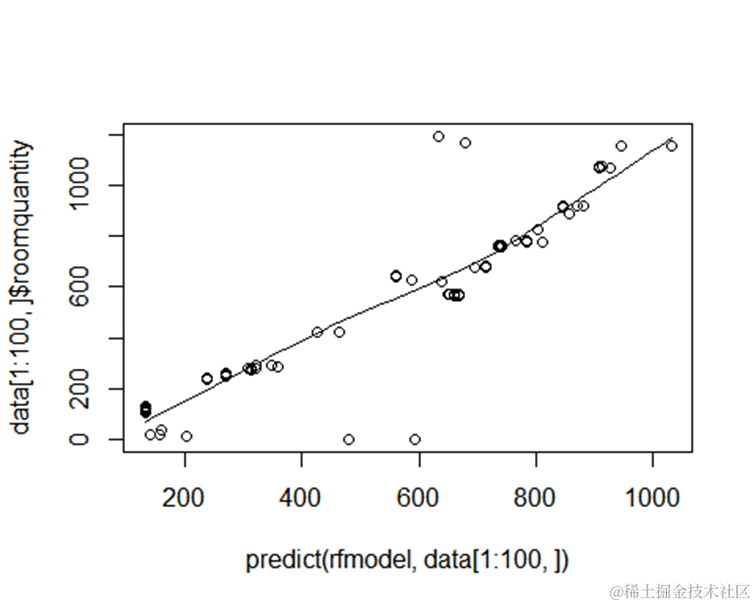
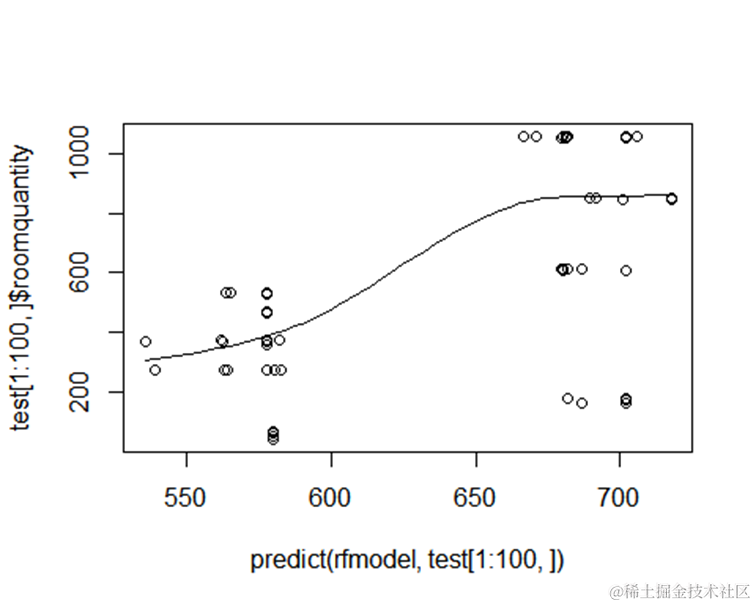
产量排名前四分之一酒店平均误差值

(∑|每天酒店预测值-每天酒店实际值|/每天酒店实际值)/天数
test=test[test$masterhotelid %in% s40,]
产量排名前四分之一酒店平均误差:
sum(abs(predict(rfmodel,test )-test$roomquantity)/test$roomquantity)/le
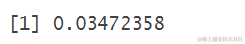
结论
通过上述步骤,我们可以得到一个关于酒店收入和产量的预测模型,并通过测试集来评估其性能。此外,我们还可以分析模型在关键酒店上的表现,从而了解模型在实际应用中的潜在价值。需要注意的是,随机森林模型中的参数(如ntree)应根据具体情况。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据
Python用DGCRN、Informer序列蒸馏与GRU、LSTM组合模型PM2.5浓度预测对比分析|附代码数据 Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据
Python GCN图卷积神经网络分子亲脂性LogD预测附代码数据 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码



