
该项目包括探索一个现实世界的数据集-CDC的2013年 行为风险因素监视系统 -并针对三个选择的研究问题创建报告。
执行摘要
选择的研究问题及其各自的结果是:
- 被访者对其健康状况的看法是否与他们的体重指数(BMI)有关?性别之间有什么区别吗?
- 是的,健康观念和BMI之间存在明显的关系,并且存在性别差异。
- 身为幼儿的父母如何影响所报告的睡眠时间?这在性别上有何不同?
- 作为幼儿的父母,据报道睡眠较少,包括性别差异。
- 对一般健康感的回答是否与调查的时间有关?各州之间如何显示差异?
- 在国家一级,冬季和非冬季反应之间没有显着差异,但有迹象表明各州的反应有所不同。
加载包
library(ggplot2)
library(dplyr)
载入资料
数据是从文件的本地副本加载的。
load("brfss2013.RData")
dim(brfss2013)
## [1] 491775 330
从上面可以看出,该数据集包含近500,000个观察值以及330个可能的变量。
第1部分:数据
BRFSS的背景
根据CDC 网站的说法 ,“行为风险因素监视系统(BRFSS)是美国首屈一指的健康相关电话调查系统,该系统收集有关美国居民有关健康相关风险行为,慢性健康状况以及预防措施使用情况的状态数据服务。
方法
根据疾病预防控制中心的说法,“ BRFSS是一项横断面电话调查,州卫生部门每月通过座机电话和蜂窝电话进行电话调查,并获得标准化的问卷调查以及疾病预防控制中心的技术和方法支持。
此外,考虑到BRFSS的方法,还有一些关于偏差的担忧:
- 通过使用电话调查,可能会漏报几种类型的个人:
- 那些无法使用座机或手机的人。
- 那些原则上不回应电话调查的人。
- 进行调查时无法进行调查的项目。
- 由于访谈问题的答案尚未得到验证,因此受访者可能会以多种方式改变他们的回答:
- 过度报告理想的行为和特质,同时低估不良行为。
- 系统地夸大身高或收入等特征。
- 由于要求您记住30天内或更长时间的详细信息,所以记错了关键信息。
- 最后,参与的国家机构之间的面试做法和问题集可能存在不一致之处。
为了将来参考,如果数据集包含有关每个采访的详细信息,那么该收集是关于一天中的什么时间以及花费了多长时间的信息。
第2部分:研究问题
研究问题1:
被访者对其健康状况的看法是否与他们的体重指数(BMI)有关?性别之间有什么区别吗?
这是一个有趣的问题,因为它寻求人们对自己健康状况的看法与总体健康状况的较为客观的衡量指标之间的联系。它已得到广泛认可。性别之间的差异也很有趣,因为人们可以挑出社会中不同的观念和压力。
使用以下变量进行了分析:
- genhlth-对应于一般健康
- X_bmi5cat-将BMI分为4类的计算变量。BMI来自报告的身高和体重。
- 性别-报告的性别
研究问题2:
身为幼儿的父母如何影响所报告的睡眠时间?这在性别上有何不同?
这是一个有趣的问题,可以估算作为年幼子女的父母可能会对受访者产生的影响。了解男性和女性之间的这种影响是否显着不同也很有用。
使用以下变量进行了分析:
- sleptim1-报告的每晚睡眠时间
- rcsrltn2-受访者与同一家庭中随机孩子的关系
- X_impcage-估算变量,将孩子年龄分为4种可能的类别。
- 性别-报告的性别
研究问题3:
对一般健康感的回答是否与调查的时间有关?各州之间如何显示差异?
这个问题着眼于可能的季节性因素如何影响响应。在这种情况下,关注的是冬季对整体健康反应的潜在影响。作为后续,它考察了美国各州的样本,以考虑可能的地区差异。
使用以下变量进行了分析:
- genhlth-对应于一般健康
- imonth-进行采访的月份
- X_state-受访者的居住状态
第3部分:探索性数据分析
研究问题1:
被访者对其健康状况的看法是否与他们的体重指数(BMI)有关?性别之间有什么区别吗?
# Select appropriate variables from dataset and omit NAs
q1 <- select(brfss2013,genhlth,sex,X_bmi5cat) %>% na.omit()
dim(q1)
## [1] 463274 3
prop.table(table(q1$genhlth,q1$X_bmi5cat),2)
##
## Underweight Normal weight Overweight Obese
## Excellent 0.19990243 0.26019496 0.17373887 0.07933813
## Very good 0.26393463 0.35069868 0.35401238 0.26824837
## Good 0.26149530 0.24667514 0.30698451 0.37088006
## Fair 0.15831199 0.09751640 0.11943759 0.19913468
## Poor 0.11635565 0.04491484 0.04582665 0.08239876初始加载数据(超过460,000次观察)后,我们可以初步查看频率,然后考虑它们的比例。
解释上表的方式是,对于每一列(“体重不足”,“正常体重”,……),表示健康状况为“优秀”,“非常好”,……的受访者比例是多少?列总和为1。
可以在下面看到更简单的图形表示:
g <- ggplot(q1) + aes(x=X_bmi5cat,fill=genhlth) + geom_bar(position = "fill")
g <- g + xlab("BMI category") + ylab("Proportion") + scale_fill_discrete(name="Reported Health")
g
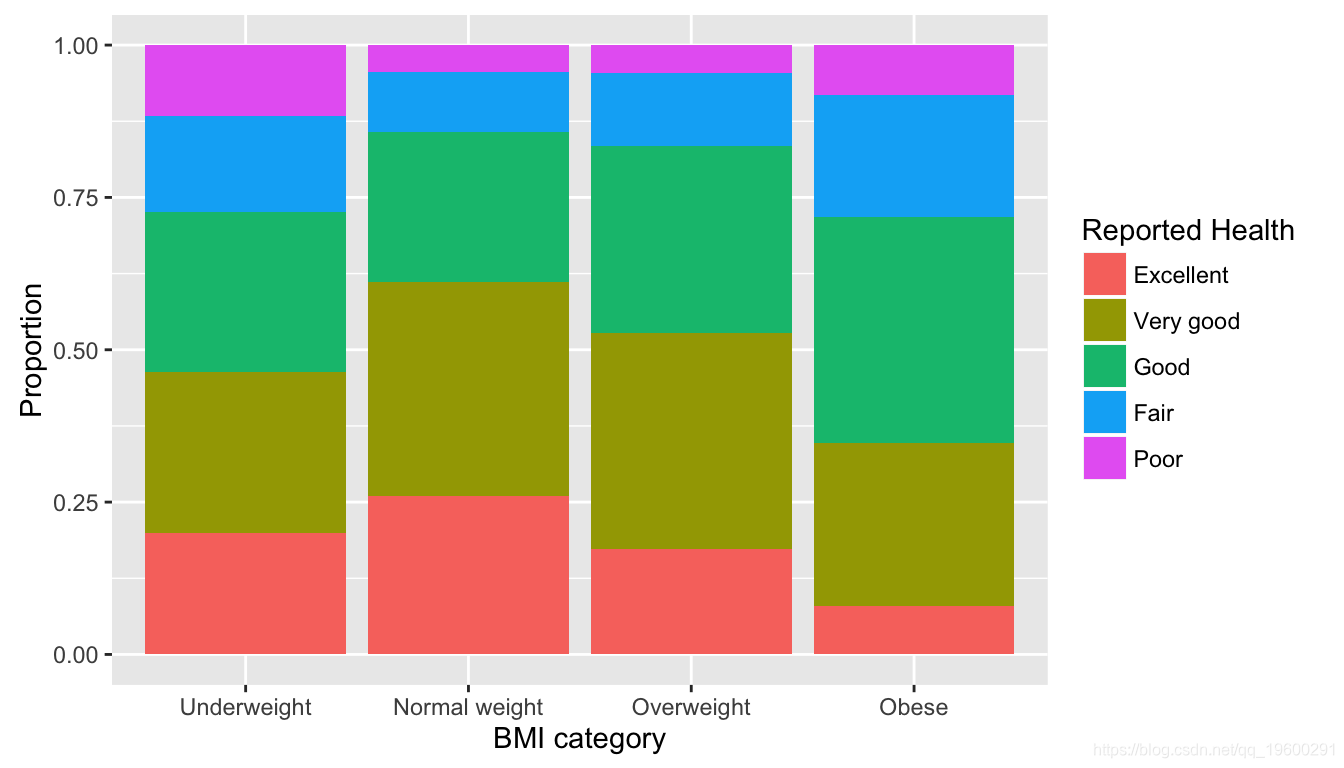

有一些有趣的趋势需要观察:
- 从“体重不足”到“正常体重”的报告,“健康”状况良好的报告比例增加,但从“正常体重”到肥胖的报告比例显着下降。这表明可能对整体健康状况有所了解。
- 在报告“健康”状况差的人中,“显着”下降的幅度似乎大于增长趋势。这可能表明缺乏对什么构成健康的意识/教育。
性别的影响如何?
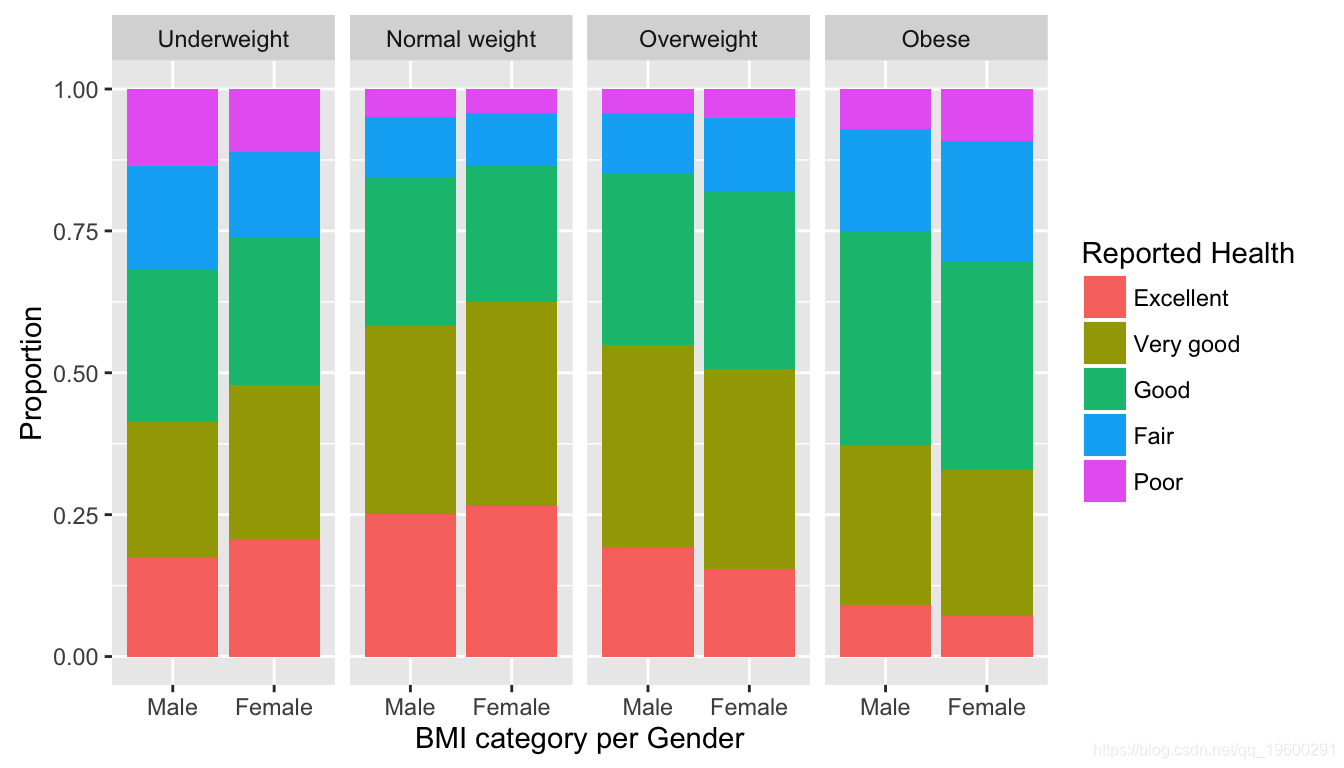

在这种情况下,我们可以观察到以下内容:
- 当BMI分类为“体重不足”或“正常体重”时,女性报告的“良好”健康状况比例高于男性。这可能表明健康与苗条之间的联系更加紧密,反映出更广泛的社会观点。
- 当女性的BMI分类为“超重”或“肥胖”时,女性报告的“良好”健康状况比例低于男性。这可能表明对体重过度敏感是整体健康的一个组成部分。
总而言之,健康感知与BMI之间存在明显的关系,并且存在性别差异。
但是,在进行了分析的情况下,这些关系不能用来推断因果关系。
研究问题2:
身为幼儿的父母如何影响所报告的睡眠时间?这在性别上有何不同?
##
## 0 1 2 3 4 5 6 7 8 9
## 1 228 1076 3496 14261 33436 106197 142469 141102 23800
## 10 11 12 13 14 15 16 17 18 19
## 12102 833 3675 199 447 367 369 35 164 13
## 20 21 22 23 24 103 450
## 64 3 10 4 35 1 1
初始数据加载表明数据中存在编码错误。清理工作涉及删除每天超过16小时的睡眠时间。
## [1] 484056 2
## [1] 57857 5
此数据加载执行两个数据选择操作:
- 首先,它从原始数据集中选择合适的列进入q2数据框。
- 然后,它创建两个单独的数据框进行分析:
- q2_pop:针对更广泛的人群,省略了错误编码的值。
- q2_parent:利用来自BRFSS的“随机子选择”问题集,并选择那些将自己标识为“父母”的问题。此外,它还增加了一个列以识别10岁以下的儿童。
重要的是要注意,尽管总体人口约为480,000个样本,但BRFSS的“随机子选择”模块产生的样本数略少于60,000。
对于一般人群,我们有以下报告的睡眠分布(红线对应于平均值):
## avg sd
## 1 7.042784 1.431061
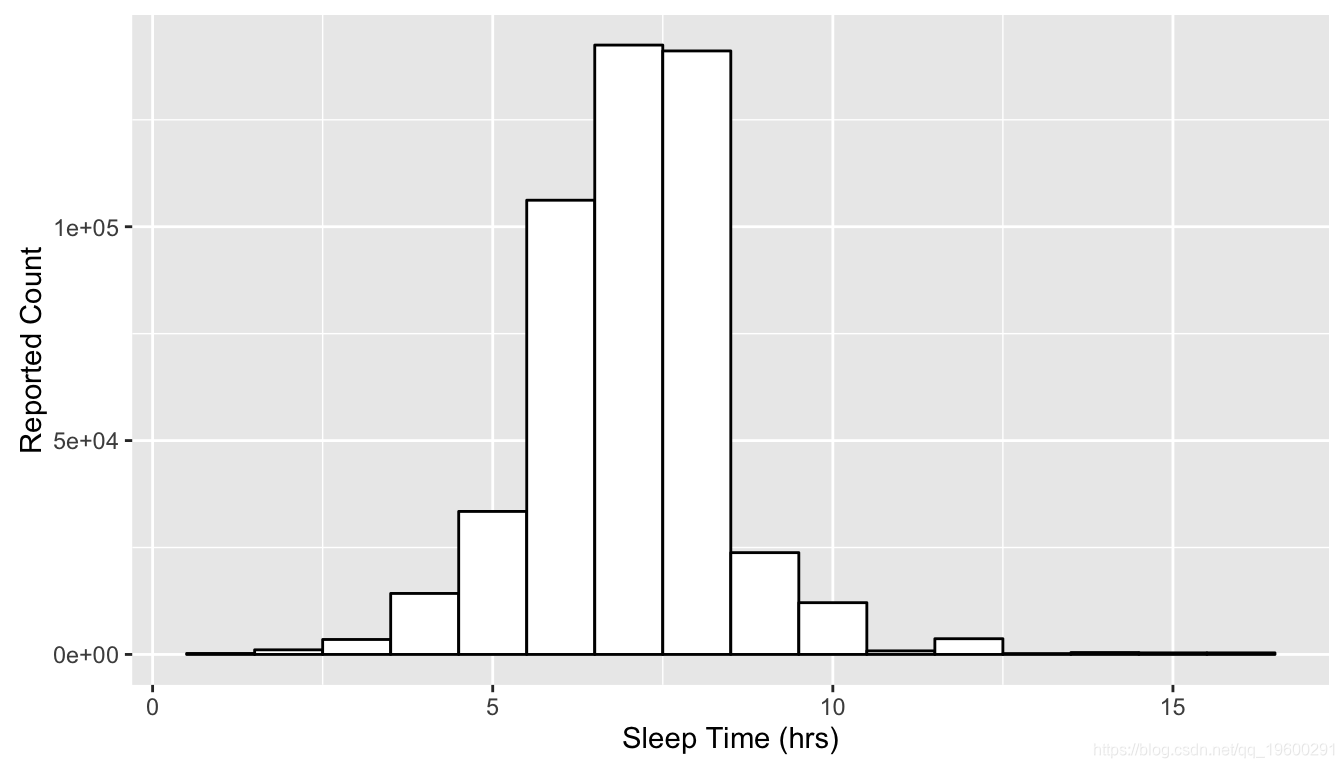

对于父母群体,分布的特征是:
## avg sd
## 1 6.854521 1.315791
对于小孩的父母,分布看起来像:
## avg sd
## 1 6.847745 1.31827
最后,看看有小孩的父母的性别差异:
## # A tibble: 2 x 3
## sex avg sd
## <fctr> <dbl> <dbl>
## 1 Male 6.755862 1.230122
## 2 Female 6.909699 1.371082
从分布的特征和最初的研究问题来看,似乎总的人口与作为小孩父母的儿童之间报告的睡眠小时数之间存在性别差异。期望进一步的统计技术将使我们能够量化这种差异的重要性。
研究问题3:
对一般健康感的回答是否与调查的时间有关?各州之间如何显示差异?
## [1] 489790 4
##
## FALSE TRUE
## Excellent 0.17393076 0.17643433
## Very good 0.32401281 0.32724673
## Good 0.30769272 0.30641019
## Fair 0.13705171 0.13362268
## Poor 0.05731200 0.05628606
此问题的初始数据加载产生了大约490,000个样本。根据研究问题,提取的变量是报告的总体健康状况,访问的月份以及受访者的居住状态。
为了进行此分析,增加了一个额外的列,指示采访是否在通常与冬季相关的月份进行。
查看比例表(向下查看FALSE和TRUE列),也可以在下图中可视化:
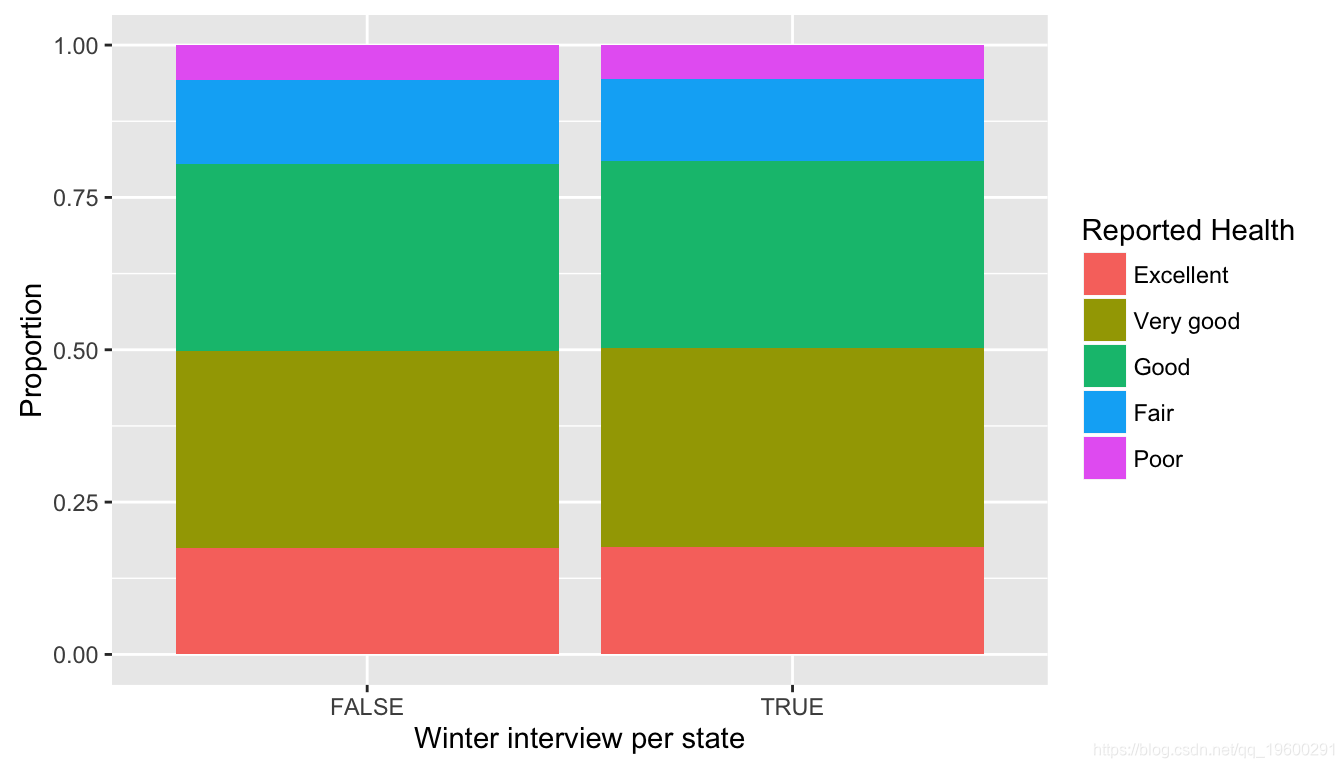

有趣的是,当我们查看特定于州的数据时,会出现稍微不同的情况。选择了美国各州的样本进行进一步分析:
## [1] 43608 4
## Source: local data frame [10 x 3]
## Groups: X_state [?]
##
## X_state winter count
## <fctr> <lgl> <int>
## 1 Alaska FALSE 3432
## 2 Alaska TRUE 1129
## 3 California FALSE 11105
## 4 California TRUE 403
## 5 Massachusetts FALSE 10631
## 6 Massachusetts TRUE 4411
## 7 New Hampshire FALSE 4525
## 8 New Hampshire TRUE 1539
## 9 Wyoming FALSE 5685
## 10 Wyoming TRUE 748
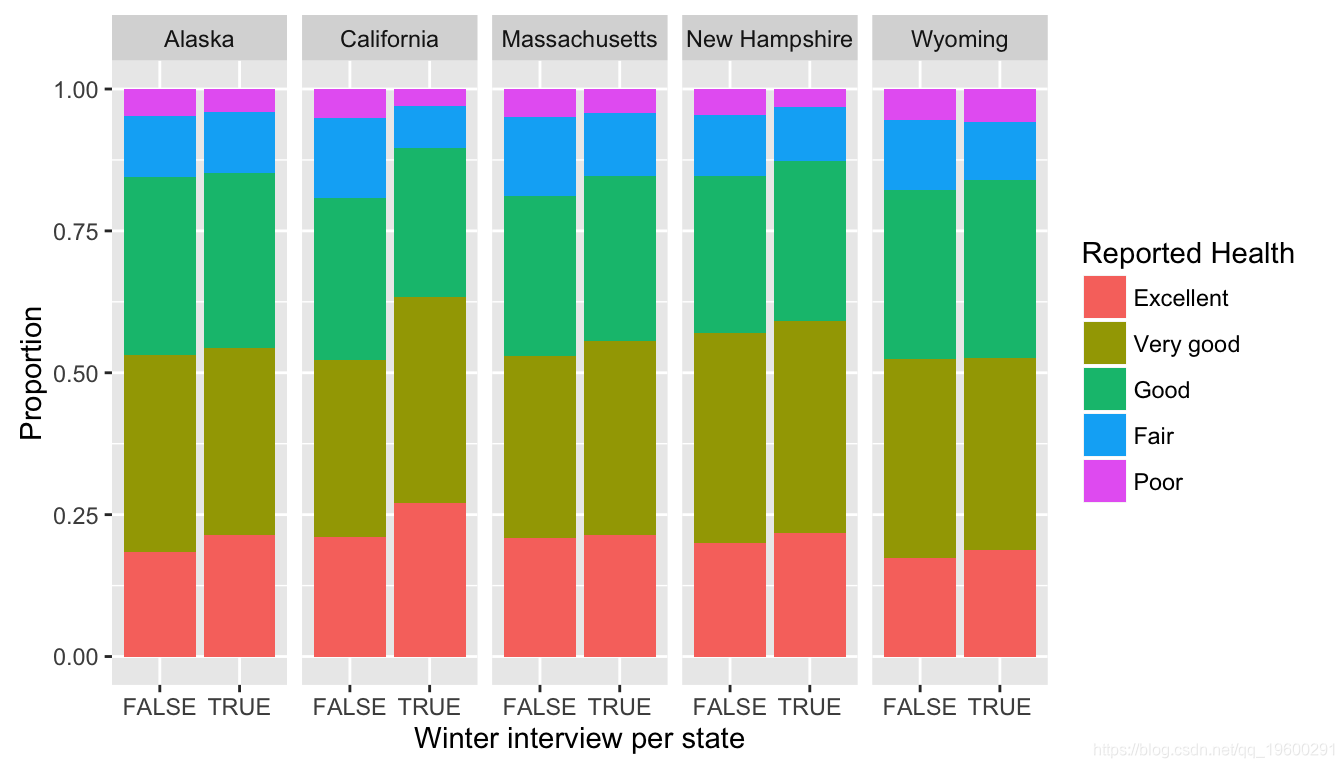

在这种情况下,该图显示出表明冬季健康状况良好的受访者比例存在明显差异。这可能归因于不同的因素,例如:
- 冬季的心情(与全国其他地方相比,气温较低或气温较高)
- 各州数据收集的差异-以加利福尼亚州为例,冬季的病例数量很少
- 其他因素。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
