电力负荷预测是电网规划的基础,其水平的高低将直接影响电网规划质量的优劣。
为了准确预测电力负荷,有必要进行建模。本文在R语言中使用分位数回归、GAM样条曲线、指数平滑和SARIMA模型对电力负荷时间序列预测并比较。
用电量
本文使用的数据是1996年至2010年之间的每周用电量数据,序列![]()
电力负荷预测是电网规划的基础,对电力电量平衡、主变定容选址、网架规划等环节具有重要的理论支撑作用。可以说,电力负荷预测贯穿于规划工作始终,预测水平的高低将直接影响电网规划质量的优劣。负荷预测已经有不短的研究历史,涌现了大量比较成熟有效的预测方法。
主要分为确定性预测方法和非确定性预测方法。
确定性预测方法多把负荷用一个或一组方程来描述,负荷与影响其变化的因素之间有着明确的对应关系,包括回归分析法、时间序列法、负荷密度法、相关分析法、年最大负荷利用小时数法等。
而不确定性方法认为电力负荷的变化受众多模糊的、不确定的因素影响,它不可能用精确的显式数学方程来描述,包括专家经验法、神经网络法、模糊预测法、灰色模型法等。负荷预测的各种方法根据其自身的特点被应用于不同的场合。随着我国新型城镇化建设的推进,农村地区基本功能不断加强,人口迁移加剧、产业结构升级、生活方式及生活理念发生转变,负荷预测的复杂性进一步加深 。前瞻性的开展农村电力负荷预测研究,可以满足地区城镇化发展对电网安全稳定、灵活调度的要求,适应长期可持续发展的需要,具有重大的现实意义。
load ("Load.RData")
plot (ts( data = Load , start= 1996 , frequency = 52) )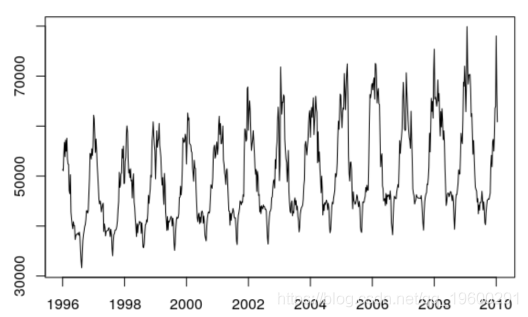
用电量变量及其影响因素:
•星期几(离散)
•时间小时(离散或非参数)
•年(连续)
交互影响:
•日期和时间
•年份和时间
活动
•公共假期
温度对模型的影响:高温、低温和极冷温度
模型:
分段线性函数,
GAM模型中的样条曲线
数据探索
时间对电力负荷的影响
> plot ( NumWeek , Load )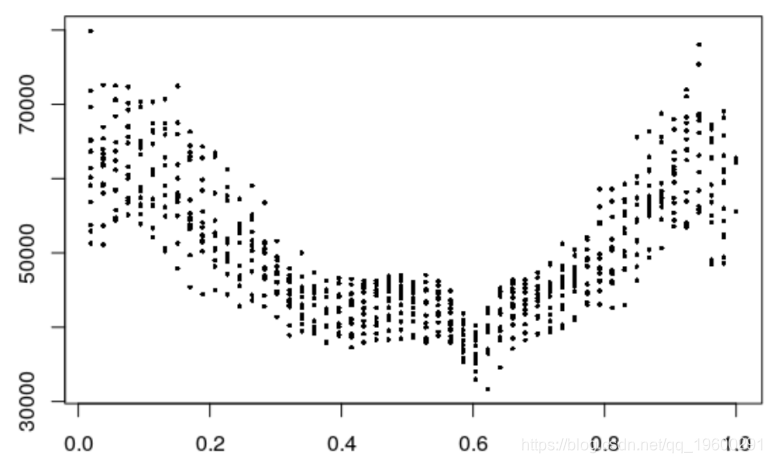
温度对电力负荷的影响,(Tt,Yt)
> plot ( Temp , Load )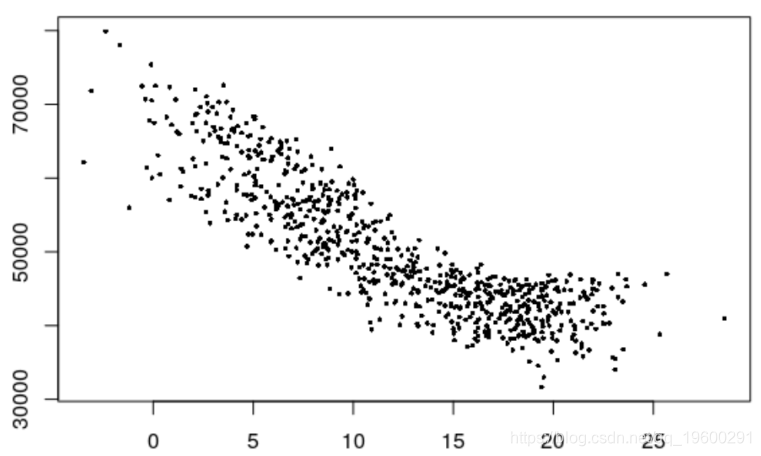
负荷序列(Yt)的自相关的影响,
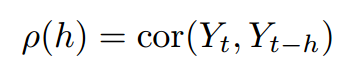
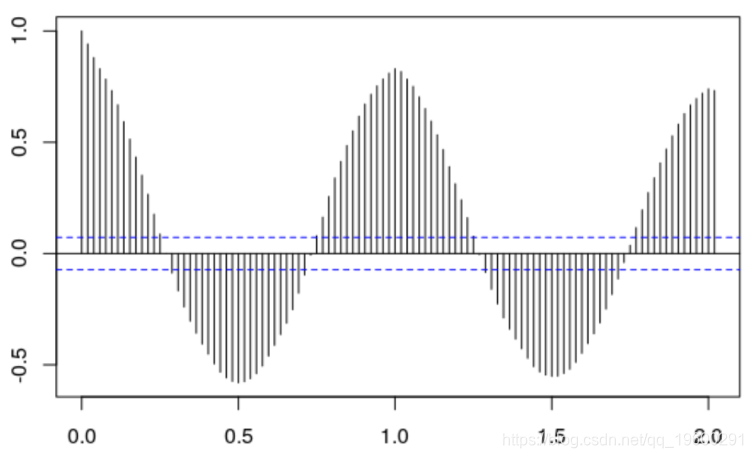
> acf (Load )

OLS与 中位数回归
中位数回归通过单调变换是稳定的。![]()
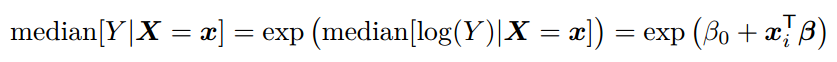
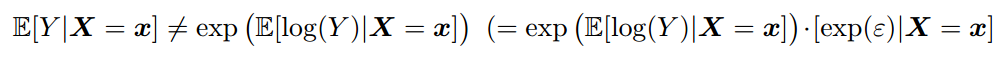
lm(y˜x, data =df)
lm(y˜x, data =df , tau =.5)现在,中位数回归将始终有两个观察结果。
which ( predict ( fit ))
21 46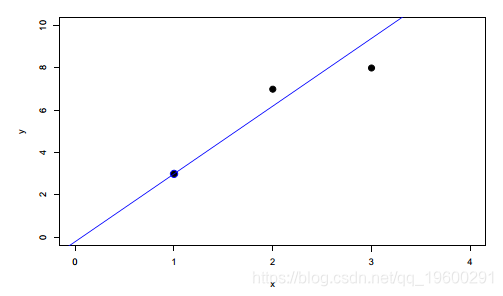
分位数回归和指数平滑
简单的指数平滑:![]()
经典地,我们寻找使预测误差最小的α,即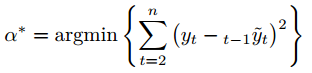
X=as. numeric ( Nile )
SimpleSmooth = function (a){
for (t in 2:T{L[t=a*X[t+(1 -a)*L[t -1
}lines ( SimpleSmooth (.2) ,col =" red ")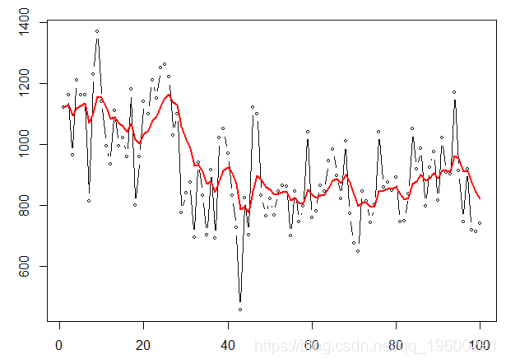
V= function (a){
for (t in 2:T){
L[t]=a*X[t]+(1 -a)*L[t -1]
erreur [t]=X[t]-L[t -1] }
return ( sum ( erreur ˆ2) )
optim (.5 ,V)$ par
[1] 0.2464844
hw= HoltWinters (X, beta =FALSE
hw$ alpha
[1] 0.2465579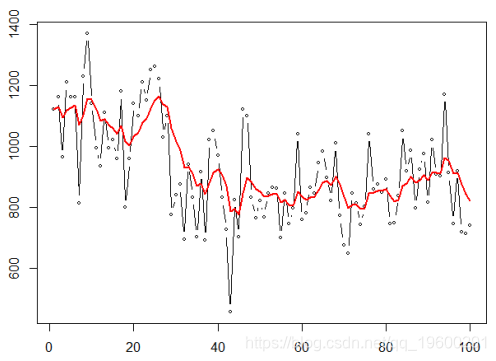
随时关注您喜欢的主题
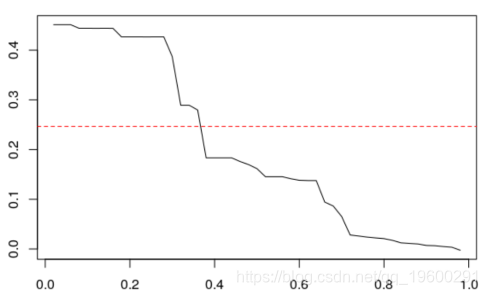
我们可以考虑分位数误差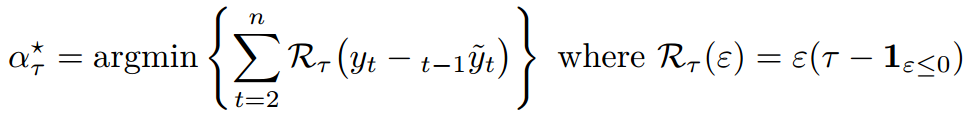
HWtau = function ( tau ){
loss = function (e) e*(tau -(e< ;=0) *1)
V= function (a){
for (t in 2:T){
L[t]=a*X[t+(1 -a)*L[t -1
erreur [t=X[t-L[t -1
return ( sum ( loss ( erreur
optim (.5 ,V)$ par
plot (X, type ="b",cex =.6
lines ( SimpleSmooth ( HWtau (.8,col=" blue ",
lwd =2)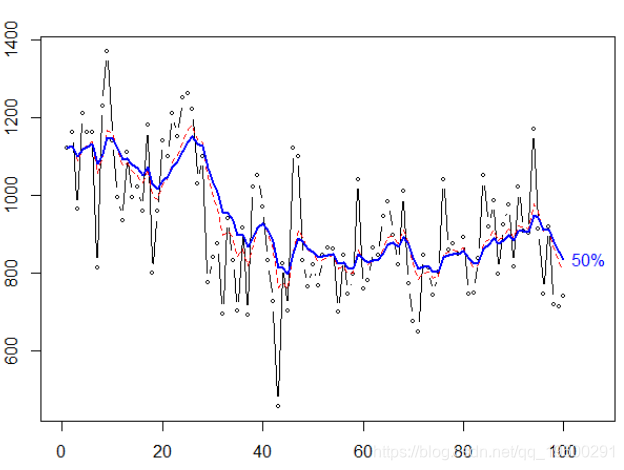
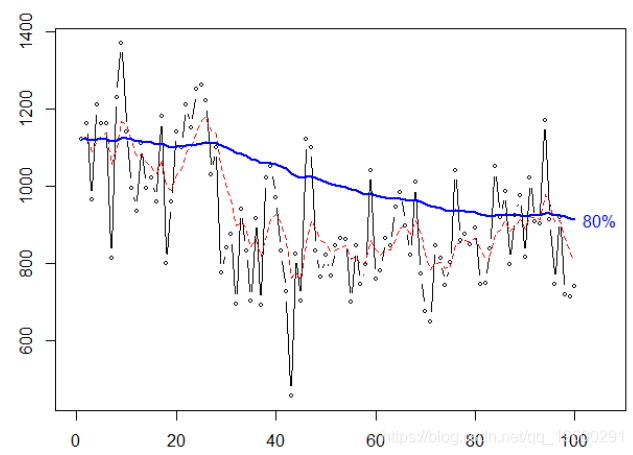
双指数平滑
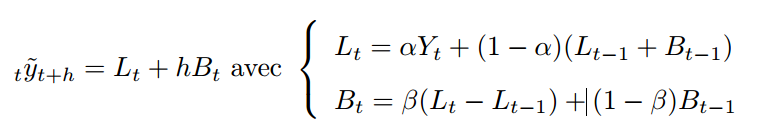
我们考虑分位数误差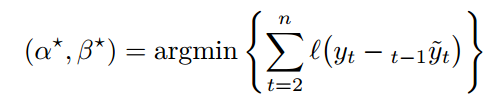
其中![]() 。
。
hw= HoltWinters (X, gamma =FALSE ,l. start =X[1])
hw$ alpha
alpha
0.4223241
hw$ beta
beta
0.05233389
DouSmo = function (a,b){
for (t in 2:T){
L[t]=a*X[t+(1 -a*(L[t -1]+ B[t -1]
B[t]=b*(L[t]-L[t -1]) +(1 -b*B[t -1]
return (L+B)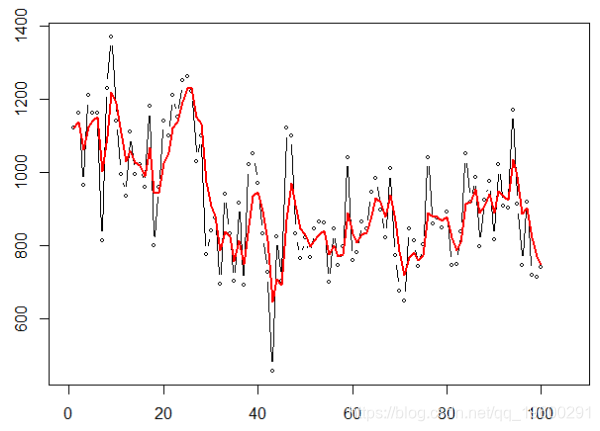
预测
数理统计建立在对概率模型参数的估计和假设检验的基础上。
统计中的预测:当模型拟合观测值时,它会提供良好的预测。
相反,我们使用没有出现过的场景,它使我们能够评估未来的主要趋势,而不是预测极端事件的能力。
预测变量的构造
plot (ts( data = Load $Load , start =
1996 , frequency = 52) ,col =" white "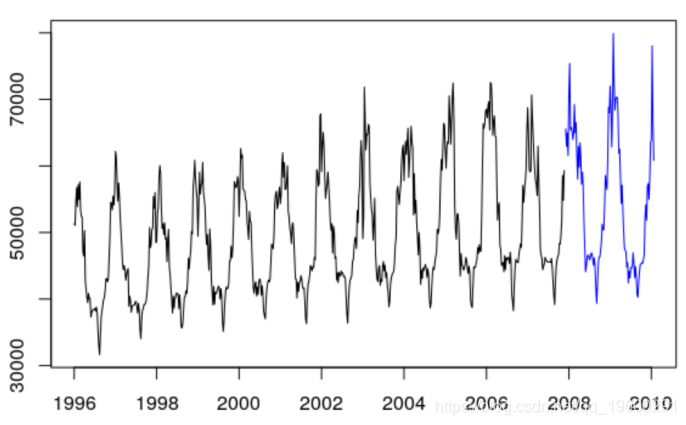
回归
plot (ts( data = Temp , start =
1996 , frequency = 52) ,
lines (ts( data = train $Temp , start =
1996 , frequency = 52) )
lines (ts( data = test $Temp , start =
1996+620 /52, frequency = 52) 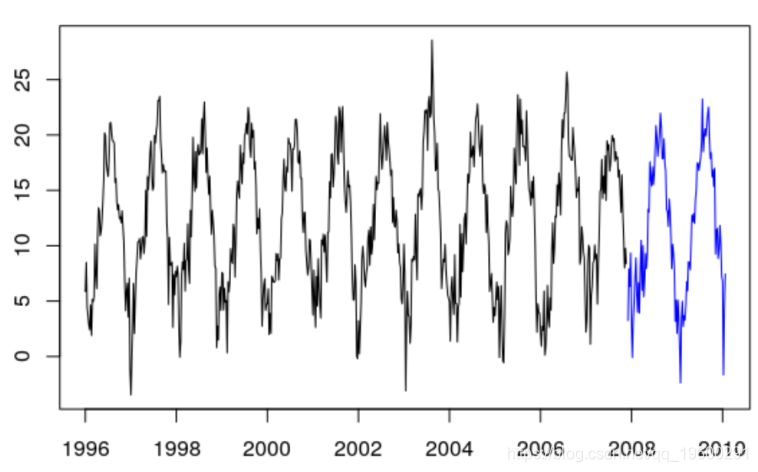
SARIMA模型
s = 52![]()
ARIMA = arima (z, order =c(1 ,0 ,0 ,seasonal =list ( order =c(0 ,1 ,0 ,period =52
plot ( forecast (ARIMA ,h =112 )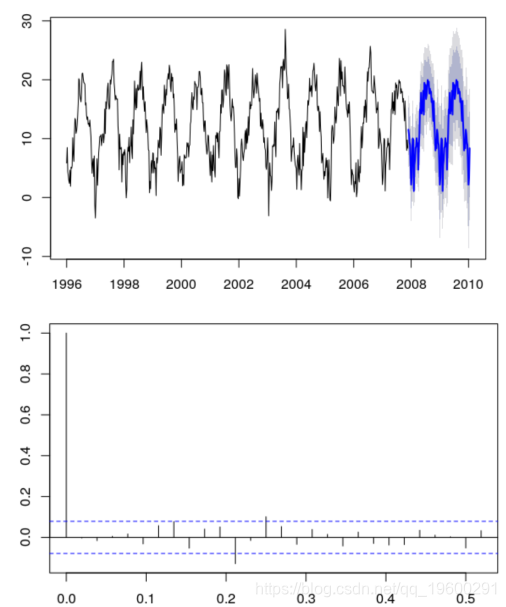

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



