“预测非常困难,特别是关于未来”。-丹麦物理学家尼尔斯·波尔(Neils Bohr)
很多人都会看到这句名言。预测是这篇博文的主题。在这篇文章中,我们将介绍流行的ARIMA预测模型,以预测股票的收益,并演示使用R编程的ARIMA建模的逐步过程。
可下载资源
时间序列中的预测模型是什么?
预测涉及使用其历史数据点预测变量的值,或者还可以涉及在给定另一个变量的值的变化的情况下预测一个变量的变化。预测方法主要分为定性预测和定量预测。时间序列预测属于定量预测的范畴,其中统计原理和概念应用于变量的给定历史数据以预测同一变量的未来值。使用的一些时间序列预测技术包括:
什么是 ARIMA模型
1. ARIMA的优缺点
2. 判断是时序数据是稳定的方法。
-
稳定的数据是没有趋势(trend),没有周期性(seasonality)的; 即它的均值,在时间轴上拥有常量的振幅,并且它的方差,在时间轴上是趋于同一个稳定的值的。
-
可以使用Dickey-Fuller Test进行假设检验。(另起文章介绍)
3. ARIMA的参数与数学形式
-
p–代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做AR/Auto-Regressive项
-
d–代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项。
-
q–代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项

ARIMA建模基本步骤
-
获取被观测系统时间序列数据;
-
对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
-
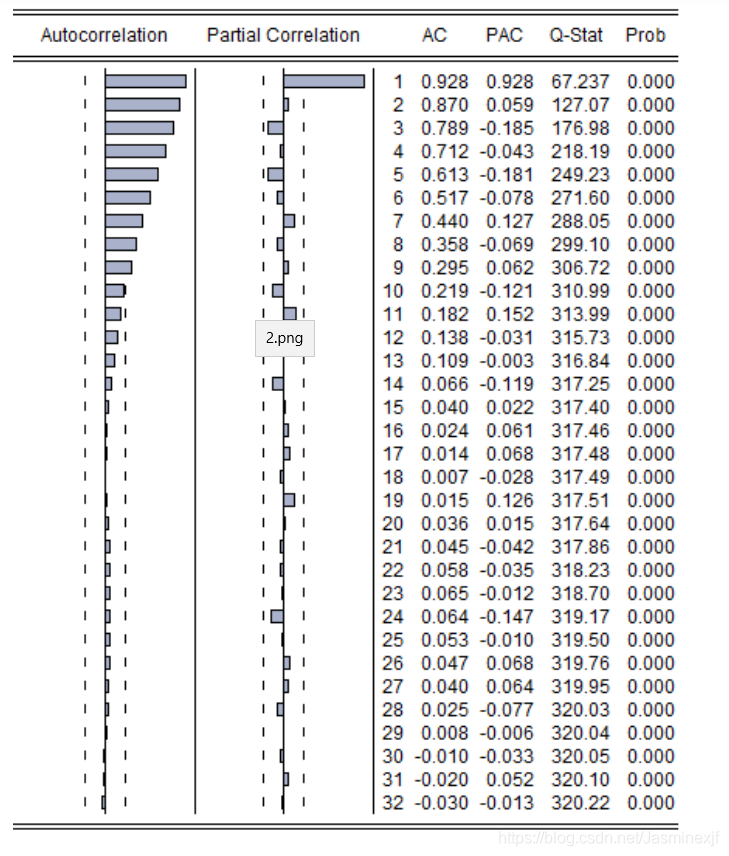
经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
-
由以上得到的d、q、p,得到ARIMA模型。然后开始对得到的模型进行模型检验。

- 自回归模型(AR)
- 移动平均模型(MA)
- 季节回归模型
- 分布式滞后模型
什么是自回归移动平均模型(ARIMA)?
ARIMA代表Autoregressive Integrated Moving Average。ARIMA也被称为Box-Jenkins方法。Box和Jenkins声称,通过对系列Y t进行差分,可以使非平稳数据平稳。Y t的一般模型写成,
ARIMA模型结合了三种基本方法:
- 自回归(AR) – 在自回归的一个给定的时间序列数据在他们自己的滞后值,这是由在模型中的“P”值表示回归的值。
- 差分(I-for Integrated) – 这涉及对时间序列数据进行差分以消除趋势并将非平稳时间序列转换为平稳时间序列。这由模型中的“d”值表示。如果d = 1,则查看两个时间序列条目之间的差分,如果d = 2,则查看在d = 1处获得的差分的差分,等等。
- 移动平均线(MA) – 模型的移动平均性质由“q”值表示,“q”值是误差项的滞后值的数量。
该模型称为自回归整合移动平均值或Y t的 ARIMA(p,d,q)。我们将按照下面列举的步骤来构建我们的模型。
第1步:测试和确保平稳性
要使用Box-Jenkins方法对时间序列进行建模,该系列必须是平稳的。平稳时间序列表示没有趋势的时间序列,其中一个具有恒定的均值和随时间的方差,这使得预测值变得容易。
测试平稳性 –我们使用Augmented Dickey-Fuller单位根测试测试平稳性。对于平稳的时间序列,由ADF测试得到的p值必须小于0.05或5%。如果p值大于0.05或5%,则可以得出结论:时间序列具有单位根,这意味着它是一个非平稳过程。
差分 –为了将非平稳过程转换为平稳过程,我们应用差分方法。区分时间序列意味着找出时间序列数据的连续值之间的差分。差分值形成新的时间序列数据集,可以对其进行测试以发现新的相关性或其他有趣的统计特性。
我们可以连续多次应用差分方法,产生“一阶差分”,“二阶差分”等。
在我们进行下一步之前,我们应用适当的差分顺序(d)使时间序列平稳。
第2步:识别p和q
在此步骤中,我们通过使用自相关函数(ACF)和偏相关函数(PACF)来确定自回归(AR)和移动平均(MA)过程的适当顺序。
识别AR模型的p阶
对于AR模型,ACF将以指数方式衰减,PACF将用于识别AR模型的顺序(p)。如果我们在PACF上的滞后1处有一个显着峰值,那么我们有一个1阶AR模型,即AR(1)。如果我们在PACF上有滞后1,2和3的显着峰值,那么我们有一个3阶AR模型,即AR(3)。
识别MA模型的q阶
对于MA模型,PACF将以指数方式衰减,ACF图将用于识别MA过程的顺序。如果我们在ACF上的滞后1处有一个显着的峰值,那么我们有一个1阶的MA模型,即MA(1)。如果我们在ACF上的滞后1,2和3处有显着的峰值,那么我们有一个3阶的MA模型,即MA(3)。
第3步:估算和预测
一旦我们确定了参数(p,d,q),我们就可以估算ARIMA模型在训练数据集上的准确性,然后使用拟合模型使用预测函数预测测试数据集的值。最后,我们交叉检查我们的预测值是否与实际值一致。
使用R编程构建ARIMA模型
现在,让我们按照解释的步骤在R中构建ARIMA模型。有许多软件包可用于时间序列分析和预测。我们加载相关的R包进行时间序列分析,并从雅虎财经中提取股票数据。
#从雅虎财经中提取数据
getSymbols('TECHM.NS',from ='2012-01-01',to =''2015-01-01')
#选择相关的收盘价序列
stock_prices = TECHM.NS [,4]在下一步中,我们计算股票的对数收益,因为我们希望ARIMA模型预测对数收益而不是股票价格。我们还使用绘图函数绘制了对数收益序列。
#计算股票 一阶差分
stock = diff(log(stock_prices),lag = 1)
plot(stock,type ='l',main ='log return plot')
接下来,我们对收益序列数据调用ADF测试以检查平稳性。来自ADF测试的p值为0.01告诉我们该序列是平稳的。如果序列是非平稳的,我们首先会对回归序列进行差分,使其序列平稳。
在下一步中,我们将数据集拆分为两部分 – 训练和测试
acf.stock = acf(stock [c(1:breakpoint),],main ='ACF Plot',lag.max = 100)
我们可以观察这些图并得出自回归(AR)阶数和移动平均(MA)阶数。
我们知道,对于AR模型,ACF将呈指数衰减,PACF图将用于识别AR模型的阶数(p)。对于MA模型,PACF将以指数方式衰减,ACF图将用于识别MA模型的阶数(q)。
从这些图中我们选择AR order = 2和MA order = 2.因此,我们的ARIMA参数将是(2,0,2)。
我们的目标是从断点开始预测整个收益序列。我们将在R中使用For循环语句,在此循环中,我们预测测试数据集中每个数据点的收益值。
在下面给出的代码中,我们首先初始化一个序列,它将存储实际的收益,另一个系列来存储预测的收益。在For循环中,我们首先根据动态分割点划分训练数据集和测试数据集。
我们在训练数据集上调用arima函数,其指定的阶数为(2,0,2)。我们使用这个拟合模型通过使用forecast.Arima函数来预测下一个数据点。该功能设置为99%置信水平。可以使用置信度参数来增强模型。我们将使用模型中的预测点估计。预测函数中的“h”参数表示我们要预测的值的数量。
我们可以使用摘要功能确认ARIMA模型的结果在可接受的范围内。在最后一部分中,我们将每个预测收益和实际收益分别附加到预测收益序列和实际收益序列。
#初始化实际对数收益率的xts对象
Actual_series = xts(0,as.Date(“2014-11-25”,“%Y-%m-%d”))
#初始化预测收益序列的数据
fit = arima(stock_train,order = c(2,0,2),include.mean = FALSE)
#绘制残差的acf图
acf(适合$ residuals,main =“Residuals plot”)
arima.forecast = forecast.Arima(fit,h = 1,level = 99)
#绘制预测
#为预测期创建一系列预测收益
forecasted_series = rbind(forecasted_series,arima.forecast $ mean [1])
#为预测期创建一系列实际收益
Actual_series = c(Actual_series,xts(Actual_return))
RM(Actual_return)
}随时关注您喜欢的主题
在我们转到代码的最后部分之前,让我们从测试数据集中检查ARIMA模型的结果以获取样本数据点。
从得到的系数,收益方程可写为:
Y t = 0.6072 * Y (t-1) -0.8818 * Y (t-2) -0.5447ε (t-1)+0.8972ε (t-2)
系数给出了标准误差,这需要在可接受的范围内。Akaike信息标准(AIC)评分是ARIMA模型准确性的良好指标。模型更好地降低AIC得分。我们还可以查看残差的ACF图; 良好的ARIMA模型的自相关性将低于阈值限制。预测的点收益为-0.001326978,在输出的最后一行中给出。
让我们通过比较预测回报与实际回报来检查ARIMA模型的准确性。代码的最后一部分计算此准确性信息。
#调整实际收益率序列的长度
Actual_series = Actual_series [-1]
#创建预测序列的时间序列对象
forecasted_series = xts(forecasted_series,index(Actual_series))
#创建两个回归系列的图 - 实际与预测
#创建一个表格,用于预测的准确性
comparsion = merge(Actual_series,forecasted_series)
comparsion $ Accuracy = sign(comparsion $ Actual_series)== sign(comparsion $ Precasted)
#计算准确度百分比指标
Accuracy_percentage = sum(comparsion $ Accuracy == 1)* 100 / length(comparsion $ Accuracy)模型的准确率百分比达到55%左右。可以尝试运行模型以获得(p,d,q)的其他可能组合,或者使用auto.arima函数选择最佳的最佳参数来运行模型。
结论
最后,在本文中,我们介绍了ARIMA模型,并将其应用于使用R编程语言预测股票价格收益。我们还通过实际收益检查了我们的预测结果。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



