随着大数据时代的来临,数据挖掘和机器学习在诸多领域中的应用价值日益凸显。
手机评论数据作为消费者对产品和服务的主观反馈,具有巨大的商业价值。本文旨在帮助客户通过R语言实现支持向量机(SVM)模型在文本挖掘分类方面的研究,并对手机评论数据进行词云可视化分析,以深入挖掘消费者意见,为企业决策提供有力支持。
支持向量机(SVM)
感知机学习算法会因采用的初值不同而得到不同的超平面。而SVM试图寻找一个最佳的超平面来划分数据,怎么算最佳呢?
可下载资源
我们自然会想到用最中间的超平面就是最好的。如下图 :
感知机与支持向量机的区别
感知机是支持向量机的基础,由感知机误分类最小策略可以得到分离超平面(无穷多个),支持向量机利用间隔最大化求得最优分离超平面(1个)。
间隔最大化就是在分类正确的前提下提高确信度。比如,A离超平面远,若预测点就是正类,就比较确信是正确的。点C离超平面近,就不那么确信正确。
视频
支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
视频
文本挖掘:主题模型(LDA)及R语言实现分析游记数据
同时SVM具有核函数,线性支持向量机解决线性分类问题。对于非线性分类问题,可以采用非线性支持向量机解决。具体为:
采取一个非线性变换,将非线性问题转变为线性问题。再通过线性支持向量机解决,这就是核技巧。
设T是输入空间(欧式空间或离散集合),H为特征空间(希尔伯特空间)。如果存在一个映射
使得对于所有的
在学习与预测中只定义核函数,而不显式地定义映射函数.
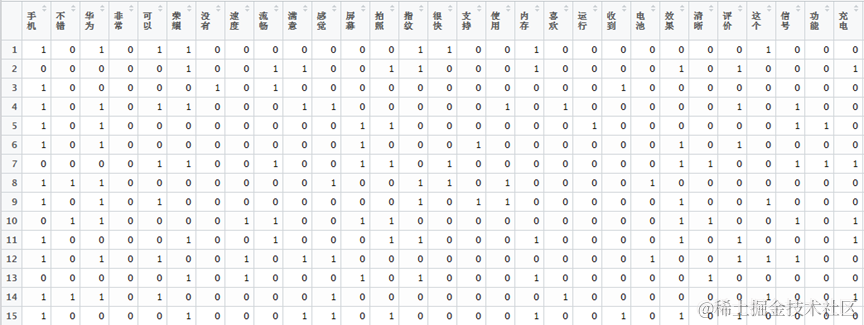
基于距离的聚类算法
层次分析(Clustering Analysis):根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内的对象互相之间是相似的(相关的),不同组中的对象是不同的(不相关的)。组内的余弦距离越小,相似性越大,组间差别越大,聚类就越好。就理解数据而言,簇是潜在的类,而聚类分析就是研究自动发现这些类的技术。
文本挖掘中的分类模型
支持向量机方法能在训练样本数很小的情况下达到很好分类推广能力的学习算法,它能做到与数据的维数无关。以线性可分的问题为例,从图<可直观地理解 算法。算法所得到的决策面为:将两类分开最大缝隙的超平面。对决策面设计起作用的点(图中圈中的点)称为支持向量 。分类线方程 可以对它进行归一化 使得对线性可分的样本集。它被成功的应用于手写数字识别和文本自动分类等很多领域。
数据预处理
用SVM实现文本分类,先要从原始空间中抽取特征,将原始空间中的样本映射为高维特征空间中的一个向量,以解决原始空间中线性不可分的问题.
文本分类(Text Categorization 或Text Classification)是在已给定的分类体系下(文本集),依据文本的内容或对文本的标识信息等,通过分类程序的学习和运算等处理方式,自动地确定文本所关联的类别。从数学角度来看,文本分类是一个映射的过程,即系统根据已经掌握的每类若干样本的数据信息,总结出分类的规律从而建立并关联判别公式和判别规则;当分类器遇到输入的未标明类属的新文本时,根据总结出的判别规则,确定该文本相关联的类别。
手机评论数据:
#剔除特殊词和回车等特殊符号
res=gsub(pattern="[我|你|的|了|是]"," ",res);
res=gsub(pattern="[1|2|3|4|5|6|7|8|9|0]"," ",res);
首先需要一个训练样本集作为输入,以便分类器能够学习模式并找到分类函数。训练集(Training set) 由一组数据库纪录或元组构成,每个记录是一个由有关字段值组成的特征向量,这些字段称做属性(Feature),用于分类的属性叫做标签(Label)。训练集中标签属性的类型必须是离散的。为降低分类器错误率,提高分类效率,标签属性的可能值越少越好。对于经典支持向量分类机来说,正负二类分类值{+1,-1}(binary classification)是最理想的分类值状态。
从训练集中自动地构造出分类器的算法叫做训练。得到的分类器常要进行分类测试以确定其分类准确性。测试集使用的数据和训练集通常具有相同的数据格式。在实际应用中常用一个数据集的2/3作为训练集,1/3作为测试集。
特征选取
将文本转换成为适合分类任务后,本文对各个关键词的词频进行统计。而词频较小的特征词汇对许多任务影响相对较小。因此本文筛选出词频最高的20个特征词汇,并使用这些词频来建模,从而提高准确度。
# 降序排序
v=rev(sort(v));
d=data.frame(word=names(v), freq=v);
高频特征词汇词云图如下:
随时关注您喜欢的主题
wordcloud(d$word,d$freq.Freq,random.order=FALSE,random.color=FALSE,colors=mycolors,family="myFont3")
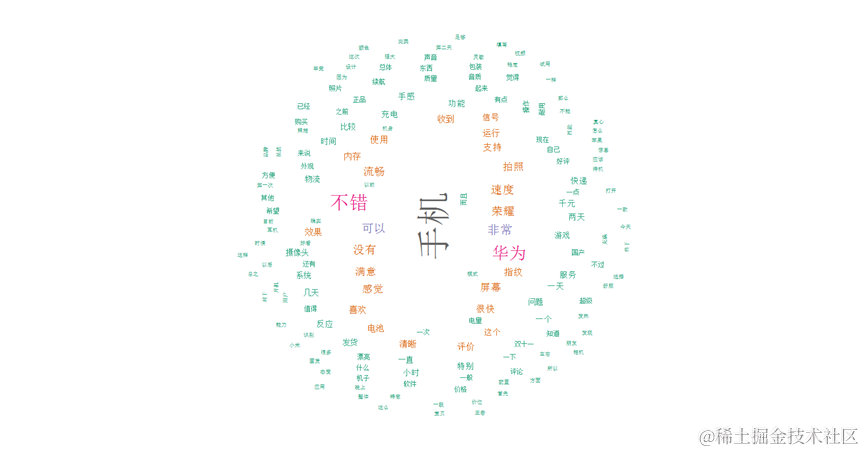
得到的高频词汇频数。
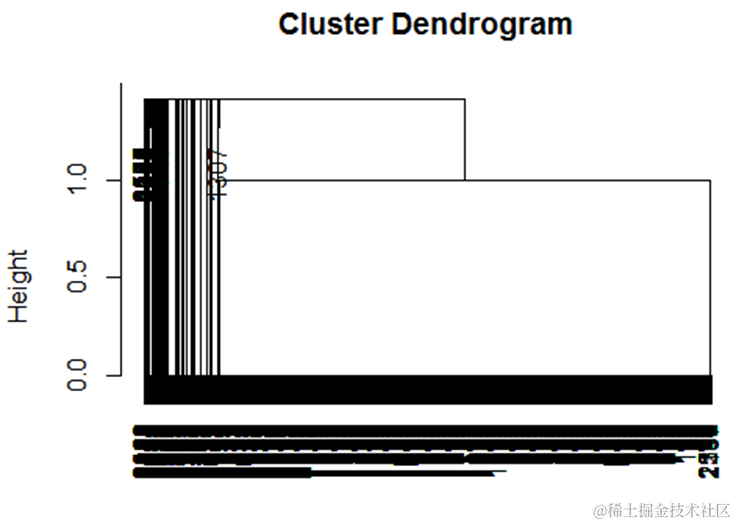
层次聚类结果
clust(dist(cldata))
plot(hc)

3个聚类类别的数据词云可视化
#cluster 1
y1=cldata[memb==1,]
#cluster 2
y2=cldata[memb==2,]



从词频云图可以看到,第一个类中评价的主要关键词是发货速度等,从这些关键词来看,本文可以推测这类用户主要看重的是购买体验,并且主要集中在物流。也可以推测这些用户比较关注物流 。
第二个类别中主要的关键词是物流、好评、性价比等。从这些关键词我们大致可以推测这类用户主要看重的是购物的综合评价。他们比较看重手机的物流、好评,更在乎购物给他们使用的直观体验。
第三个类别中主要的关键词是正品,满意 。从这些关键词我们可以推测这类用户主要看重手机的品质,当然这类手机一般都是高端的定制手机。因此,这类手机大多是手机玩家,发烧友。如果手机能很好满足他们的需求,他们愿意做出较好的评价。因此针对这类用户,我们可以体检性能好、功能强大的手机。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化
Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据 Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
Python糖尿病预测融合模型构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用 2025金融服务行业的数据和AI现状报告330+份汇总解读|附PDF下载
2025金融服务行业的数据和AI现状报告330+份汇总解读|附PDF下载


