
NASA有32,000多个数据集,并且NASA有兴趣了解这些数据集之间的联系,以及与NASA以外其他政府组织中其他重要数据集的联系。
有关NASA数据集的元数据有JSON格式在线获得。让我们使用主题建模对描述字段进行分类,然后将其连接到关键字。
可下载资源
什么是主题建模?
主题建模是一种无监督的文档分类方法。此方法将每个文档建模为主题的混合,将每个主题建模为单词的混合。我将在这里用于主题建模的方法称为 潜在Dirichlet分配(LDA), 但还有其他适合主题模型的可能性。在本文中,每个数据集描述都是一个文档。我们将看看是否可以将这些描述文本作为主题进行建模。
获取和整理NASA元数据
让我们下载32,000多个NASA数据集的元数据 。
library(jsonlite)
library(dplyr)
library(tidyr)
names(metadata$dataset)
## [1] "_id" "@type" "accessLevel" "accrualPeriodicity"
## [5] "bureauCode" "contactPoint" "description" "distribution"
## [9] "identifier" "issued" "keyword" "landingPage"
## [13] "language" "modified" "programCode" "publisher"
## [17] "spatial" "temporal" "theme" "title"
## [21] "license" "isPartOf" "references" "rights"
## [25] "describedBy"nasadesc <- data_frame(id = metadata$dataset$`_id`$`$oid`, desc = metadata$dataset$description)
nasakeyword <- data_frame(id = metadata$dataset$`_id`$`$oid`,
keyword = metadata$dataset$keyword) %>%
unnest(keyword)
nasakeyword <- nasakeyword %>% mutate(keyword = toupper(keyword))检查一下,最常用的关键字是什么?
nasakeyword %>% group_by(keyword) %>% count(sort = TRUE)
## # A tibble: 1,616 x 2
## keyword n
## <chr> <int>
## 1 EARTH SCIENCE 14386
## 2 OCEANS 10033
## 3 PROJECT 7463
## 4 OCEAN OPTICS 7324
## 5 ATMOSPHERE 7323
## 6 OCEAN COLOR 7270
## 7 COMPLETED 6452
## 8 ATMOSPHERIC WATER VAPOR 3142
## 9 LAND SURFACE 2720
## 10 BIOSPHERE 2449
## # ... with 1,606 more rows
制作DocumentTermMatrix
要进行主题建模,我们需要从tm包中创建一种 特殊的矩阵(当然,“文档矩阵”只是一个通用概念)。行对应于文档(在本例中为描述文字),列对应于术语(即单词);它是一个稀疏矩阵。
让我们使用停用词来清理一下文本,以除去HTML或其他字符编码中残留的一些废话“词”。
## # A tibble: 1,909,215 x 3
## id word n
## <chr> <chr> <int>
## 1 55942a8ec63a7fe59b4986ef suit 82
## 2 55942a8ec63a7fe59b4986ef space 69
## 3 56cf5b00a759fdadc44e564a data 41
## 4 56cf5b00a759fdadc44e564a leak 40
## 5 56cf5b00a759fdadc44e564a tree 39
## 6 55942a8ec63a7fe59b4986ef pressure 34
## 7 55942a8ec63a7fe59b4986ef system 34
## 8 55942a89c63a7fe59b4982d9 em 32
## 9 55942a8ec63a7fe59b4986ef al 32
## 10 55942a8ec63a7fe59b4986ef human 31
## # ... with 1,909,205 more rows
现在让我们来制作 DocumentTermMatrix。
## <<DocumentTermMatrix (documents: 32003, terms: 35911)>>
## Non-/sparse entries: 1909215/1147350518
## Sparsity : 100%
## Maximal term length: 166
## Weighting : term frequency (tf)
LDA主题建模
现在,让我们使用 topicmodels 包创建一个LDA模型。我们将告诉算法进行多少个主题?这个问题很像k-means聚类中的问题;我们不提前知道。我们可以尝试一些不同的值,查看模型如何拟合文本。让我们从8个主题开始。
## A LDA_VEM topic model with 8 topics.
这是一种随机算法,根据算法的起始位置,其结果可能会有所不同。
探索建模
让我们整理模型,看看我们能找到什么。
## # A tibble: 287,288 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 suit 2.591273e-40
## 2 2 suit 9.085227e-61
## 3 3 suit 1.620165e-61
## 4 4 suit 2.081683e-64
## 5 5 suit 9.507092e-05
## 6 6 suit 5.747629e-04
## 7 7 suit 1.808279e-63
## 8 8 suit 4.545037e-40
## 9 1 space 2.332248e-05
## 10 2 space 2.641815e-40
## # ... with 287,278 more rows
β列告诉我们从该主题的文档中生成该术语的可能性。
每个主题的前5个词是什么?top_terms
## # A tibble: 80 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 data 0.047596842
## 2 1 set 0.014857522
## 3 1 soil 0.013231077
## 4 1 land 0.007874196
## 5 1 files 0.007835032
## 6 1 moisture 0.007799017
## 7 1 surface 0.006913904
## 8 1 file 0.006495391
## 9 1 collected 0.006350559
## 10 1 measurements 0.005521037
## # ... with 70 more rows
让我们看一下。
ggplot(top_terms, aes(beta, term, fill = as.factor(topic))) +
geom_barh(stat = "identity", show.legend = FALSE, alpha = 0.8) +
labs(title = "Top 10 Terms in Each LDA Topic",
subtitle = "Topic modeling of NASA metadata description field texts",
caption = "NASA metadata from https://data.nasa.gov/data.json",
y = NULL, x = "beta") +
facet_wrap(~topic, ncol = 2, scales = "free") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_x_continuous(expand=c(0,0)) +
theme(strip.text=element_text(hjust=0)) +
theme(plot.caption=element_text(size=9))
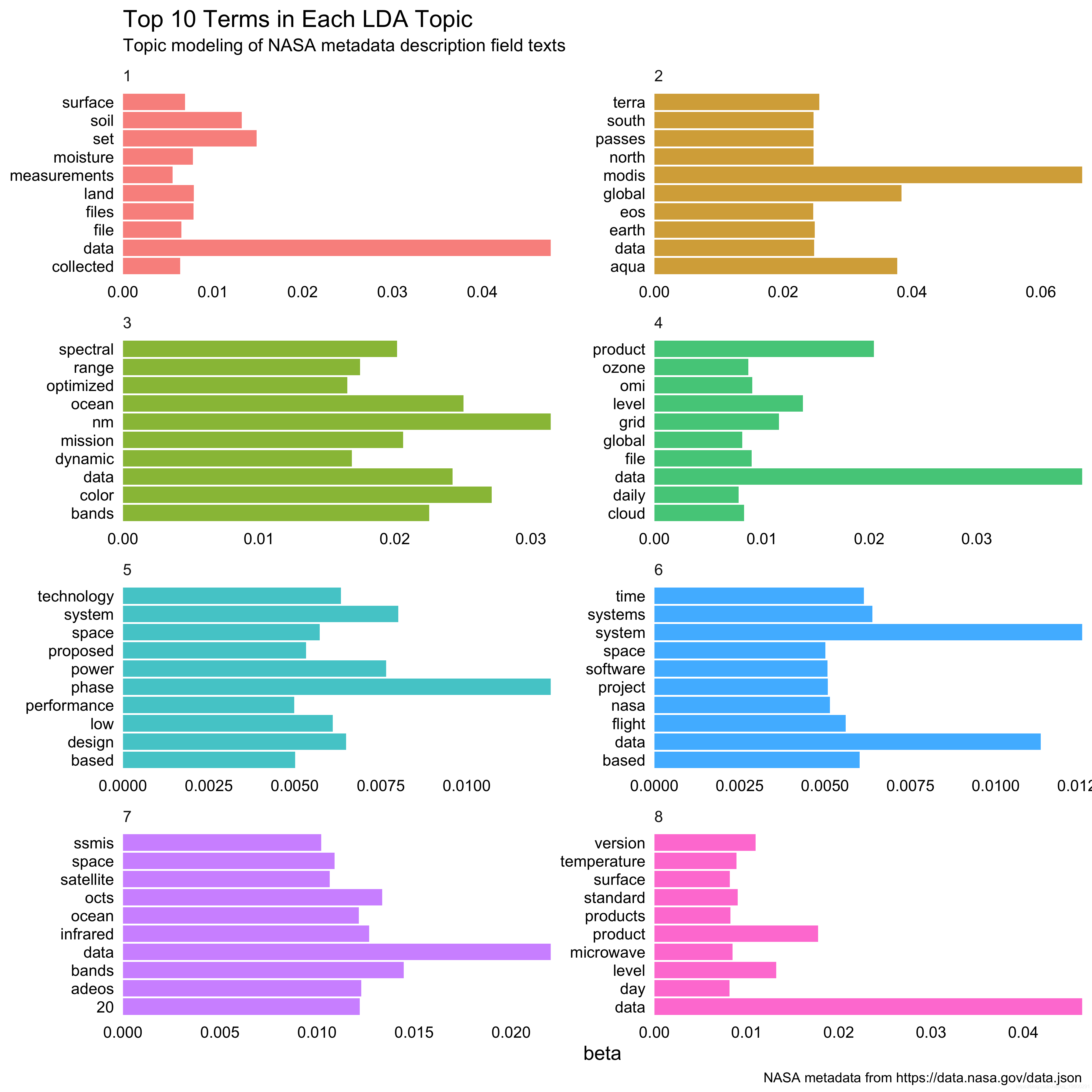

我们可以看到在这些描述文本中占主导地位的词“数据”是什么。从关于土地和土地的术语到关于设计,系统和技术的术语,这些术语集合之间确实存在着有意义的差异。绝对需要进一步探索,以找到合适数量的主题并在这里做得更好。另外,标题和描述词是否可以结合用于主题建模?
每个文档都属于哪个主题?
让我们找出哪些主题与哪些描述字段(即文档)相关联。
lda_gamma
## # A tibble: 256,024 x 3
## document topic gamma
## <chr> <int> <dbl>
## 1 55942a8ec63a7fe59b4986ef 1 7.315366e-02
## 2 56cf5b00a759fdadc44e564a 1 9.933126e-02
## 3 55942a89c63a7fe59b4982d9 1 1.707524e-02
## 4 56cf5b00a759fdadc44e55cd 1 4.273013e-05
## 5 55942a89c63a7fe59b4982c6 1 1.257880e-04
## 6 55942a86c63a7fe59b498077 1 1.078338e-04
## 7 56cf5b00a759fdadc44e56f8 1 4.208647e-02
## 8 55942a8bc63a7fe59b4984b5 1 8.198155e-05
## 9 55942a6ec63a7fe59b496bf7 1 1.042996e-01
## 10 55942a8ec63a7fe59b4986f6 1 5.475847e-05
## # ... with 256,014 more rows
此处的γ列是每个文档属于每个主题的概率。请注意,有些非常低,有些更高。概率如何分布?
ggplot(lda_gamma, aes(gamma, fill = as.factor(topic))) +
geom_histogram(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~topic, ncol = 4) +
scale_y_log10() +
labs(title = "Distribution of Probability for Each Topic",
subtitle = "Topic modeling of NASA metadata description field texts",
caption = "NASA metadata from https://data.nasa.gov/data.json",
y = NULL, x = "gamma") +
theme_minimal(base_family = "Arial", base_size = 13) +
theme(strip.text=element_text(hjust=0)) +
theme(plot.caption=element_text(size=9))
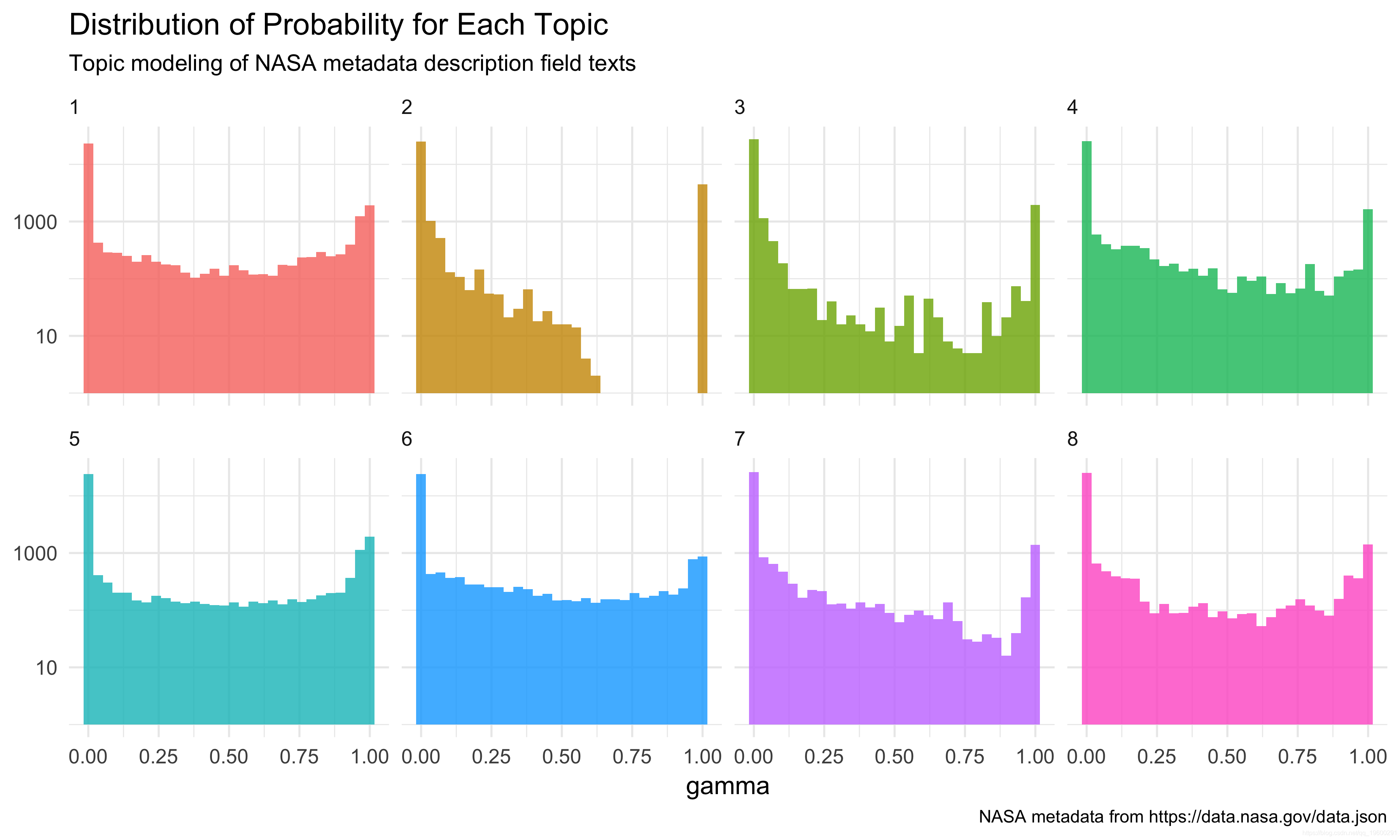

y轴在此处以对数刻度绘制,因此我们可以看到一些东西。大多数文档都被归类为以下主题之一:许多文档被归类为主题2,而文档被归类为主题1和5则较不明确。一些主题的文档较少。对于任何单个文档,我们都可以找到它具有最高归属概率的主题。
将主题建模连接到关键字
让我们将这些主题模型与关键字联系起来,看看会发生什么。让我们 将此数据框添加到关键字,然后查看哪些关键字与哪个主题相关联。
lda_gamma
## # A tibble: 1,012,727 x 4
## document topic gamma keyword
## <chr> <int> <dbl> <chr>
## 1 55942a8ec63a7fe59b4986ef 1 7.315366e-02 JOHNSON SPACE CENTER
## 2 55942a8ec63a7fe59b4986ef 1 7.315366e-02 PROJECT
## 3 55942a8ec63a7fe59b4986ef 1 7.315366e-02 COMPLETED
## 4 56cf5b00a759fdadc44e564a 1 9.933126e-02 DASHLINK
## 5 56cf5b00a759fdadc44e564a 1 9.933126e-02 AMES
## 6 56cf5b00a759fdadc44e564a 1 9.933126e-02 NASA
## 7 55942a89c63a7fe59b4982d9 1 1.707524e-02 GODDARD SPACE FLIGHT CENTER
## 8 55942a89c63a7fe59b4982d9 1 1.707524e-02 PROJECT
## 9 55942a89c63a7fe59b4982d9 1 1.707524e-02 COMPLETED
## 10 56cf5b00a759fdadc44e55cd 1 4.273013e-05 DASHLINK
## # ... with 1,012,717 more rows
让我们保留属于某个主题的文档(概率> 0.9),然后为每个主题找到最重要的关键字。
top_keywords
## Source: local data frame [1,240 x 3]
## Groups: topic [8]
##
## topic keyword n
## <int> <chr> <int>
## 1 2 OCEAN COLOR 4480
## 2 2 OCEAN OPTICS 4480
## 3 2 OCEANS 4480
## 4 1 EARTH SCIENCE 3469
## 5 5 PROJECT 3464
## 6 5 COMPLETED 3057
## 7 8 EARTH SCIENCE 2229
## 8 3 OCEAN COLOR 1968
## 9 3 OCEAN OPTICS 1968
## 10 3 OCEANS 1968
## # ... with 1,230 more rows
我们也对它们进行可视化。
ggplot(top_keywords, aes(n, keyword, fill = as.factor(topic))) +
geom_barh(stat = "identity", show.legend = FALSE, alpha = 0.8) +
labs(title = "Top 10 Keywords for Each LDA Topic",
subtitle = "Topic modeling of NASA metadata description field texts",
caption = "NASA metadata from https://data.nasa.gov/data.json",
y = NULL, x = "Number of documents") +
facet_wrap(~topic, ncol = 2, scales = "free") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_x_continuous(expand=c(0,0)) +
theme(strip.text=element_text(hjust=0)) +
theme(plot.caption=element_text(size=9))
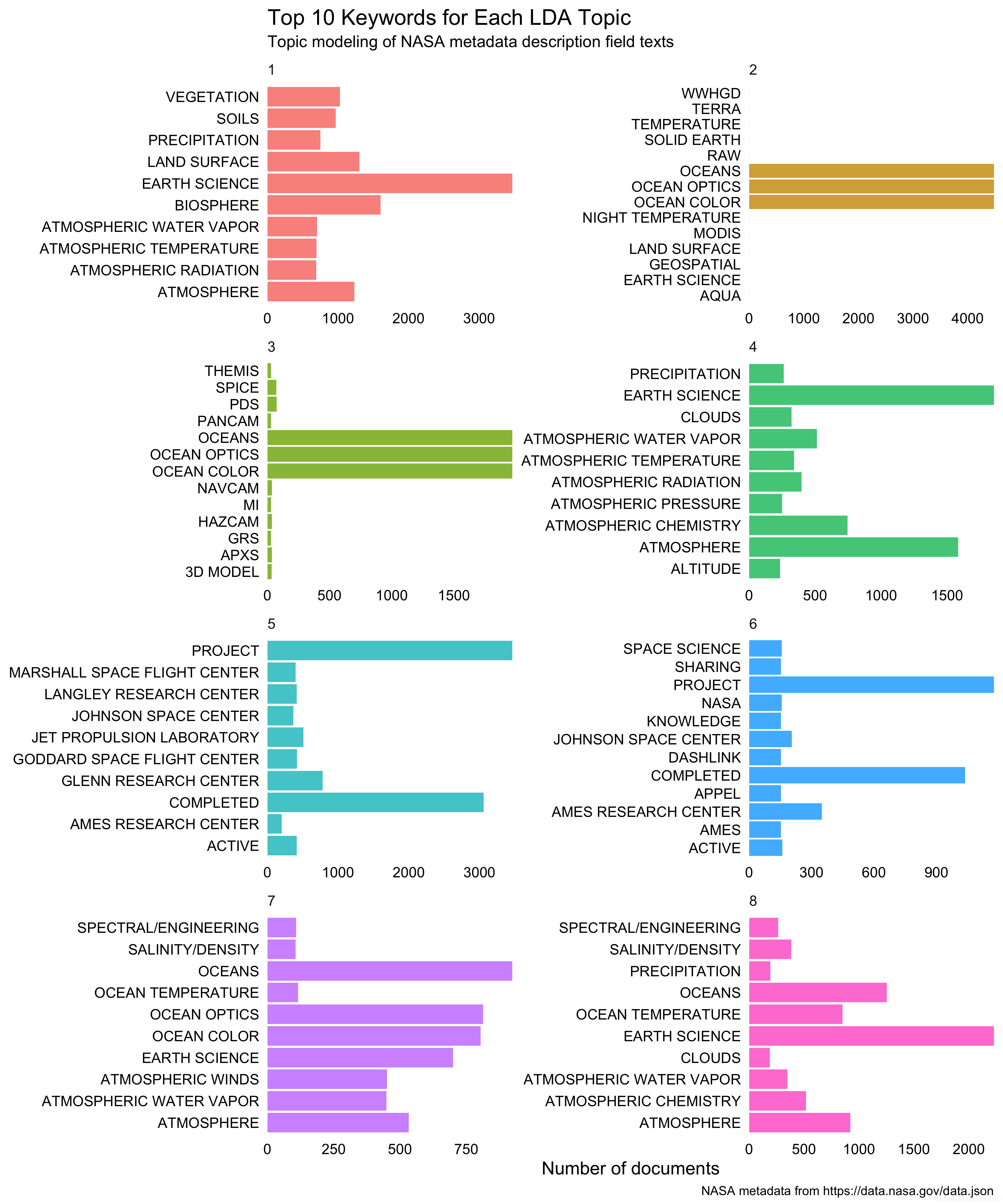

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 【视频】文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化
【视频】文本挖掘专题:Python、R用LSTM情感语义分析实例合集|上市银行年报、微博评论、红楼梦数据、汽车口碑数据采集词云可视化 短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计|附数据代码
短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计|附数据代码
