澳大利亚在2008 – 2009年全球金融危机期间发生了这种情况。澳大利亚政府发布了一揽子刺激计划
其中包括2008年12月的现金支付,恰逢圣诞节。 因此,零售商报告销售强劲,经济受到刺激。因此,收入增加了。
可下载资源
VAR面临的批评是他们是理论上的; 也就是说,它们不是建立在一些经济学理论的基础上,这些理论强加了方程式的理论结构。假设每个变量都影响系统中的其他变量,这使得估计系数的直接解释变得困难。尽管如此,VAR在几种情况下都很有用:
向量自回归模型的英文名称为Vector Autoregressive model,常被简写成VAR。向量自回归的出现由来已久,可以追溯到上个世纪80年代,人们构建向量自回归模型主要出于以下考虑:
-
时间序列分析从单一时间序列 (time series data) 拓展到了多元时间序列 (multivariate time series),在任意第
个时间间隔 (time interval),观测样本从
变成了
,其中,
-
标准的自回归模型 (Autoregressive model, 简称AR) 其表达式过于简单,无法很好地在多元时间序列分析中发挥作用。
1 标准的自回归模型
在统计学、经济学乃至信号处理等领域,自回归模型被广泛应用于描述随时间变化的过程 (简称时变过程),其中,最为经典的应用当属时间序列分析,在这里,自回归模型假设变量之间存在一个线性的依赖关系,即输出变量 (output variables) 如 与输入的历史变量 (previous variables) 如
存在一个线性表达式。
不妨先看一下标准的自回归模型:给定单一时间序列 ,其时间间隔的数量为
,则对于任意第
个时间间隔,存在如下的线性表达式:
其中, 表示回归系数;常数
表示自回归模型的阶数 (order),也可以将
简单地理解成当前时间点关联过去时间点的数量。
在自回归模型中,我们的目标是从观测数据中学习出参数 。现假设观测数据为
,首先,我们需要对自回归模型的线性表达式进行改写:
其中, ;
;
. 在这里,写成这种形式完全是为了简化后续的推导。
如果进一步将 作为高斯噪声,采用最小二乘法,则回归系数
的最优解为
2 多元时间序列
实际上,相比单一的时间序列数据,多元时间序列数据反而更为常见,是由单一的时间序列构成,如下面的矩阵
就是一般形式的多元时间序列数据。在矩阵 中,任意第
个时间间隔下,观测值为
观测值的数量为 .
3 向量自回归模型
针对多元时间序列数据,向量自回归模型采用了一种更为灵活的时序建模策略:给定多元时间序列数据为 ,则对于任意第
个时间间隔,存在如下的线性表达式:
其中, 表示向量自回归模型的系数矩阵;
可视为高斯噪声。
为方便后续推导,与自回归模型类似,令
将向量自回归模型进行改写:
其中,公式中的矩阵 和
定义如下:
由此,采用最小二乘法,系数矩阵 的最优解为
在这里,我们用到了F-范数与矩阵迹 (trace) 之间的等价变换,它的意义是为了方便推导,如何简单理解这种等价变换呢?举一个例子:给定任意大小为的矩阵
由于F-范数是矩阵所有元素的平方和开根号,即
另外,
因此,根据矩阵迹的定义,有![[公式]](https://www.zhihu.com/equation?tex=%5Ctext%7Btr%7D%5Cleft%28A%5E%5Ctop+A%5Cright%29%3Da_%7B11%7D%5E%7B2%7D%2Ba_%7B12%7D%5E%7B2%7D%2Ba_%7B21%7D%5E%7B2%7D%2Ba_%7B22%7D%5E%7B2%7D%3D%5C%7CA%5C%7C_%7BF%7D%5E2.)
- 预测相关变量的集合,不需要明确的解释;
- 测试一个变量是否有助于预测另一个变量(格兰杰因果关系检验的基础);
- 脉冲响应分析,其中分析了一个变量对另一个变量的突然但暂时的变化的响应;
- 预测误差方差分解,其中每个变量的预测方差的比例归因于其他变量的影响。
示例:用于预测美国消费的VAR模型
VARselect(uschange[,1:2], lag.max=8,
type="const")[["selection"]]
#> AIC(n) HQ(n) SC(n) FPE(n)
#> 5 1 1 5R输出显示每个信息标准选择的滞后期。由AIC选择的VAR(5)与BIC选择的VAR(1)之间存在很大差异。因此,我们首先拟合由BIC选择的VAR(1)。
var1 <- VAR(uschange[,1:2], p=1, type="const")
serial.test(var1, lags.pt=10, type="PT.asymptotic")
var2 <- VAR(uschange[,1:2], p=2, type="const")
serial.test(var2, lags.pt=10, type="PT.asymptotic")与单变量ARIMA方法类似,我们使用Portmanteau测试残差是不相关的。VAR(1)和VAR(2)都具有一些残差序列相关性,因此我们拟合VAR(3)。
var3 <- VAR(uschange[,1:2], p=3, type="const")
serial.test(var3, lags.pt=10, type="PT.asymptotic")
#>
#> Portmanteau Test (asymptotic)
#>
#> data: Residuals of VAR object var3
#> Chi-squared = 34, df = 28, p-value = 0.2该模型的残差通过了序列相关性检验。VAR(3)生成的预测如图所示。
forecast(var3) %>%
autoplot() + xlab("Year")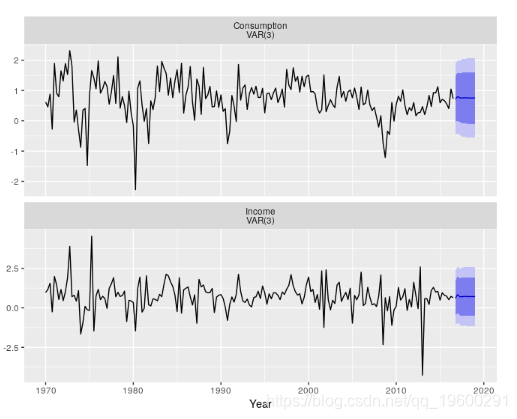
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究



