R语言与关联规则挖掘—购物篮分析
关联挖掘通常用于通过识别经常一起购买的产品来提出产品推荐。但是,如果您不小心,则规则在某些情况下可能会产生误导性的结果。
关联挖掘通常是根据零售市场或在线电子商务商店的交易数据进行的。由于大多数交易数据很大,因此该apriori算法使更容易快速找到这些模式或规则。
可下载资源
那么,什么是规则?
规则是一种符号,表示经常购买哪些商品和哪些商品。它具有LHS和RHS部分,可以表示如下:
关联是两个或多个变量取值之间存在的一类重要的可被发现的某种规律性。关联分析目的是寻找给定数据记录集中数据项之间隐藏的关联关系,描述数据之间的密切度。
几个基本概念
1. 项集
这是一个集合的概念,在一篮子商品中的一件消费品即为一项(Item),则若干项的集合为项集,如{啤酒,尿布}构成一个二元项集。
2. 关联规则
一般记为的形式,X为先决条件,Y为相应的关联结果,用于表示数据内隐含的关联性。如:,表示购买了尿布的消费者往往也会购买啤酒。
关联性强度如何,由三个概念——支持度、置信度、提升度来控制和评价。
例:有10000个消费者购买了商品,其中购买尿布1000个,购买啤酒2000个,购买面包500个,同时购买尿布和面包800个,同时购买尿布和面包100个。
3. 支持度(Support)
支持度是指在所有项集中{X, Y}出现的可能性,即项集中同时含有X和Y的概率:
该指标作为建立强关联规则的第一个门槛,衡量了所考察关联规则在“量”上的多少。通过设定最小阈值(minsup),剔除“出镜率”较低的无意义规则,保留出现较为频繁的项集所隐含的规则。
设定最小阈值为5%,由于{尿布,啤酒}的支持度为800/10000=8%,满足基本输了要求,成为频繁项集,保留规则;而{尿布,面包}的支持度为100/10000=1%,被剔除。
4. 置信度(Confidence)
置信度表示在先决条件X发生的条件下,关联结果Y发生的概率:
这是生成强关联规则的第二个门槛,衡量了所考察的关联规则在“质”上的可靠性。相似的,我们需要对置信度设定最小阈值(mincon)来实现进一步筛选。
具体的,当设定置信度的最小阈值为70%时,置信度为800/1000=80%,而的置信度为800/2000=40%,被剔除。
5. 提升度(lift)
提升度表示在含有X的条件下同时含有Y的可能性与没有X这个条件下项集中含有Y的可能性之比:
该指标与置信度同样衡量规则的可靠性,可以看作是置信度的一种互补指标。
项目集A =>项目集B
这意味着,右侧的商品经常与左侧的商品一起购买。
如何衡量规则的强度?
将apriori()产生最相关集从给定的交易数据的规则。它还显示了这些规则的支持度,置信度和提升度。这三个度量可用于确定规则的相对强度。那么这些术语是什么意思呢?
让我们考虑规则A => B,以便计算这些指标。
![]()
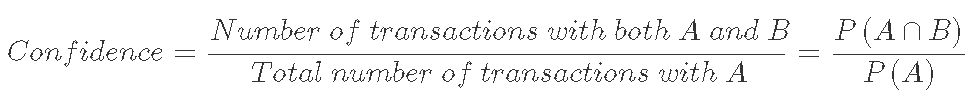
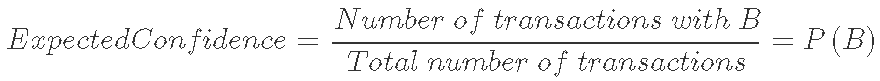

提升是A和B的并存超过独立的A和B并存的预期概率的因素。因此,提升度越高,A和B一起发生的机会就越高。
让我们看看如何使用R获取规则,置信度,提升度等。
例
交易数据与数据框不同,使用head(Groceries)不会在数据中显示交易项目。要查看交易,请改用inspect()函数。
由于关联挖掘处理交易,因此必须将数据转换为class transactions。这是必要的步骤,因为该apriori()函数transactions仅接受交易类的数据。
library(arules)
class(Groceries)
#> [1] "transactions"
#> attr(,"package")
#> [1] "arules"
inspect(head(Groceries, 3))
#> items
#> 1 {citrus fruit,
#> semi-finished bread,
#> margarine,
#> ready soups}
#> 2 {tropical fruit,
#> yogurt,
#> coffee}
#> 3 {whole milk} 如果您必须从文件中读取数据作为交易数据,请使用read.transactions()。
tdata <- read.transactions("transactions_data.txt", sep="\t")
如果您已经将交易存储为数据框,则可以将其转换为类transactions,如下所示:
tData <- as (myDataFrame, "transactions") # 转换为“交易”类
这里有一些其他有用的实用程序函数:
size(head(Groceries)) # 每个观察项的数量
#> [1] 4 3 1 4 4 5
LIST(head(Groceries, 3)) # 将'交易'类转换为列表,注意CAPS中的LIST
#> [[1]]
#> [1] "citrus fruit" "semi-finished bread" "margarine"
#> [4] "ready soups"
#>
#> [[2]]
#> [1] "tropical fruit" "yogurt" "coffee"
#>
#> [[3]]
#> [1] "whole milk"
如何查看最常出现的项目?
在eclat()交易对象中获取并给出根据您提供的支持数据的最常见物品supp。该maxlen定义频繁项中的每个项目集项目的最大数量。
frequentItems <- eclat (Groceries, parameter = list(supp = 0.07, maxlen = 15)) # 计算对频繁物品的支持度
inspect(frequentItems)
#> items support
#> 1 {other vegetables,whole milk} 0.07483477
#> 2 {whole milk} 0.25551601
#> 3 {other vegetables} 0.19349263
#> 4 {rolls/buns} 0.18393493
#> 5 {yogurt} 0.13950178
#> 6 {soda} 0.17437722
itemFrequencyPlot(Groceries, topN=10, type="absolute", main="Item Frequency") # 绘制频繁项目如何获得推荐规则?
inspect(head(rules_conf)) # 显示所有规则的支持度,提升度和置信度
#> lhs rhs support confidence lift
#> 113 {rice,sugar} => {whole milk} 0.001220132 1 3.913649
#> 258 {canned fish,hygiene articles} => {whole milk} 0.001118454 1 3.913649
#> 1487 {root vegetables,butter,rice} => {whole milk} 0.001016777 1 3.913649
#> 1646 {root vegetables,whipped/sour cream,flour} => {whole milk} 0.001728521 1 3.913649
#> 1670 {butter,soft cheese,domestic eggs} => {whole milk} 0.001016777 1 3.913649
#> 1699 {citrus fruit,root vegetables,soft cheese} => {other vegetables} 0.001016777 1 5.168156
rules_lift <- sort (rules, by="lift", decreasing=TRUE) # 'high-lift' rules.
inspect(head(rules_lift)) #
#> lhs rhs support confidence lift
#> 53 {Instant food products,soda} => {hamburger meat} 0.001220 0.6315789 18.995
#> 37 {soda,popcorn} => {salty snack} 0.001220 0.6315789 16.697
#> 444 {flour,baking powder} => {sugar} 0.001016 0.5555556 16.408
#> 327 {ham,processed cheese} => {white bread} 0.001931 0.6333333 15.045
#> 55 {whole milk,Instant food products} => {hamburger meat} 0.001525 0.5000000 15.038
#> 4807 {other vegetables,curd,yogurt,whipped/sour cream} => {cream cheese } 0.001016 0.5882353 14.834置信度为1(见rules_conf上文)的规则意味着,每当购买LHS物品时,也100%的时间购买了RHS物品。
提升为18(见rules_lift上文)的规则意味着,与假设无关的购买相比,LHS和RHS中的物品一起购买的可能性要高18倍。
如何控制输出中的规则数量?
调整maxlen,supp并conf在所述参数apriori函数来控制生成的规则数。您将不得不根据数据的冗余性对此进行调整。
parameter = list (supp = 0.001, conf = 0.5, maxlen=3) # maxlen = 3 限制规则中最大物品数量为 3- 要获得“强”规则,请增加“ conf”参数的值。
- 要获得“更长”的规则,请增加“ maxlen”。
如何删除冗余规则?
有时希望删除作为较大规则子集的规则。为此,请使用以下代码过滤冗余规则。
rules <- rules[-subsetRules] #删除规则子集随时关注您喜欢的主题
如何查找与给定项目相关的规则?
这可以通过修改函数中的appearance参数来实现apriori()。例如,
找出哪些因素影响了产品X的购买
在购买“全脂牛奶”之前找出顾客购买了什么。这将帮助您了解导致购买“全脂牛奶”的频繁模式。
sort ( by="confidence", decreasing=TRUE) # 按置信度排列
#> lhs rhs support confidence lift
#> 196 {rice,sugar} => {whole milk} 0.001220132 1 3.913649
#> 323 {canned fish,hygiene articles} => {whole milk} 0.001118454 1 3.913649
#> 1643 {root vegetables,butter,rice} => {whole milk} 0.001016777 1 3.913649
#> 1705 {root vegetables,whipped/sour cream,flour} => {whole milk} 0.001728521 1 3.913649
#> 1716 {butter,soft cheese,domestic eggs} => {whole milk} 0.001016777 1 3.913649
#> 1985 {pip fruit,butter,hygiene articles} => {whole milk} 0.001016777 1 3.913649找出在产品X之后/与产品X一起购买的产品
这是找出购买“全脂牛奶”的顾客的案例。在等式中,“全脂牛奶”以LHS(左侧)表示。
list(default="rhs",lhs="whole milk" #
#> lhs rhs support confidence lift
#> 6 {whole milk} => {other vegetables} 0.07483477 0.2928770 1.5136341
#> 5 {whole milk} => {rolls/buns} 0.05663447 0.2216474 1.2050318
#> 4 {whole milk} => {yogurt} 0.05602440 0.2192598 1.5717351
#> 2 {whole milk} => {root vegetables} 0.04890696 0.1914047 1.7560310
#> 1 {whole milk} => {tropical fruit} 0.04229792 0.1655392 1.5775950
#> 3 {whole milk} => {soda} 0.04006101 0.1567847 0.8991124这样做的一个缺点是,无论支持,置信度或最小参数如何,您在RHS上只能得到一项。
使用提升时,规则的方向性将丢失。也就是说,任何规则A => B和规则B => A的提升都将相同。请参阅以下计算:
使用提升度的提示
A-> B
- 支持度:
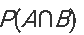
- 置信度:
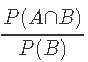
- 期望置信度:P(B)
- 提升度:
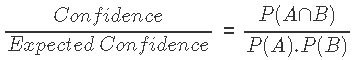
重要的提示
对于规则A-> B和B-> A而言,提升和支持度的值都相同。这意味着我们不能使用提升为特定方向的 “规则” 提出建议。它只能用于将经常购买的物品分组。
使用置信度的提示
在现实世界中提出产品建议时,尤其是在提出附加产品建议时,规则的置信度可能是一种误导性的度量。让我们考虑以下涉及4个事务的数据,涉及iPhone和耳机:
- Iphone,耳机
- Iphone,耳机
- 苹果手机
- 苹果手机
我们可以为这些交易创建2条规则,如下所示:
- iPhone->耳机
- 耳机-> iPhone
从apriori输出中选择规则时,您可能会猜测规则的置信度越高,则规则越好。但是对于这种情况,头戴式耳机-> iPhone规则将比iPhone->头戴式耳机具有更高的置信度(2倍)。你知道为什么吗?下面的计算显示了如何。
置信度计算:
iPhone->耳机: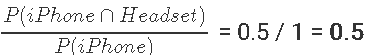
耳机-> iPhone: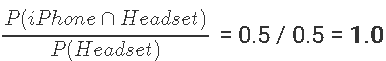
在现实世界中,将耳机推荐给刚买了iPhone的人而不是反过来是很现实的。想象一下,当您刚购买完耳机时,就被推荐为iPhone。不太好!
如您所见,耳机-> iPhone推荐具有更高的置信度,这具有误导性和不现实性。因此,置信度不应成为您提出产品建议的唯一方法。
因此,在推荐产品之前,您可能需要检查更多标准,例如产品价格,产品类型等,尤其是在交叉销售的情况下。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据 SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究
SPSS modeler用关联规则Apriori模型对笔记本电脑购买事务销量研究 WEKA关联规则挖掘Apriori算法在学生就业数据中的应用
WEKA关联规则挖掘Apriori算法在学生就业数据中的应用


