Python-Flask企业网页平台深度Q网络DQN强化学习推荐系统设计与实现
在当今数字化时代,推荐系统已成为企业连接用户与产品的重要桥梁。无论是电商平台的商品推荐,还是内容平台的信息推送,精准的推荐都能显著提升用户体验和企业效益。然而,传统推荐方法往往难以捕捉用户兴趣的动态变化,无法实现长期优化。

完整项目代码和数据文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。
我们曾为客户完成了一个推荐系统优化咨询项目,在该项目中,我们深刻认识到传统推荐方法的局限性,并探索出基于强化学习的解决方案。这个项目的核心是构建一个能够根据用户实时行为不断学习和调整的推荐系统,以实现长期收益最大化。本文将详细介绍我们如何利用Python的Flask框架搭建企业网页平台,实现用户的批量注册登录功能,为推荐系统提供用户交互的基础环境。同时,重点阐述基于深度Q网络(DQN)的强化学习推荐系统的设计与实现,包括算法原理、数据处理、模型训练和结果评估等方面。通过这个实际案例,我们展示了强化学习在推荐系统领域的应用价值,为企业提供了一种新的推荐策略优化思路。
文章脉络流程图
用户行为数据收集 → 数据预处理(用户行为序列构建) → 基于DQN的推荐模型训练 → 模型评估(推荐成功率) → Flask网页平台部署(用户注册登录与推荐展示)
Flask企业网页平台设计与实现
平台功能概述
为了实现推荐系统与用户的交互,我们使用Python的Flask框架搭建了一个企业网页平台,主要包含用户注册和登录功能。该平台不仅为用户提供了使用推荐系统的入口,还能收集用户的行为数据,为推荐模型的训练提供支持。
注册功能实现
注册功能允许新用户创建账号,系统会对用户密码进行加密处理后存储到数据库中,保障用户信息安全。
# 注册功能
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
# 获取用户提交的用户名和密码
user_name = request.form['username']
pass_word = generate_password_hash(request.form['password']) # 密码加密存储
# 连接数据库
database = get_db()
try:
# 将用户信息插入数据库
database.execute('INSERT INTO users (username, password) VALUES (?, ?)',
(user_name, pass_word))
database.commit()
# 注册成功后跳转到登录页面
return redirect(url_for('login'))
except sqlite3.IntegrityError:
# 处理用户名已存在的情况
return "用户名已存在,请返回重新注册。"
# 显示注册页面
return render_template('register.html')
运行结果展示了用户注册页面的界面,用户可以在该页面输入用户名和密码完成注册。
登录功能实现
登录功能用于验证用户身份,登录成功后会设置用户的登录状态,便于后续跟踪用户行为和提供个性化推荐。
# 登录功能
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
# 获取用户提交的用户名和密码
user_name = request.form['username']
pass_word = request.form['password']
# 连接数据库
database = get_db()
# 查询用户信息
user = database.execute('SELECT * FROM users WHERE username = ?',
(user_name,)).fetchone()
# 验证用户名和密码
if user and check_password_hash(user['password'], pass_word):
# 设置登录状态
session['user_id'] = user['id']
session['username'] = user['username']
# 登录成功后跳转到首页
return redirect(url_for('index'))
else:
# 处理登录失败的情况
return "用户名或密码错误,请返回重试。"
# 显示登录页面
return render_template('Login.html')
运行结果展示了用户登录页面的界面,用户输入正确的用户名和密码后即可登录系统。
登录成功后,用户将进入系统首页,首页会根据用户的历史行为展示推荐的商品。
管理员可以通过后台管理页面查看用户信息和系统运行情况。
基于DQN的强化学习推荐系统
推荐系统设计背景
在电商平台中,如何向用户推荐合适的商品是提升销售额和用户满意度的关键。传统的推荐方法多基于协同过滤或内容推荐,这些方法往往只考虑用户的历史偏好,难以应对用户兴趣的动态变化,也无法实现长期收益的最大化。强化学习作为一种能够在与环境的交互中不断学习和优化策略的方法,为解决推荐系统的上述问题提供了新的思路。深度Q网络(DQN)结合了深度学习的感知能力和强化学习的决策能力,能够从复杂的用户行为数据中学习到有效的推荐策略。
训练算法原理
我们采用深度强化学习方法对用户行为进行建模,将推荐任务构建为一个交互式决策过程,使用深度Q网络(DQN)作为核心学习框架。
- 核心思想
系统以用户的历史行为为状态输入,通过策略网络从候选商品集合中选择最优商品进行推荐,然后根据用户的实际反馈获得相应奖励,进而更新策略。其目标是让模型学会在给定用户历史行为状态下,推荐一个商品,使得长期的用户反馈最大化,可用公式表示为:
Q*(s,a) = E[r + γmaxQ*(s’,a’)]
其中,s为状态(包括用户的购买、点击、浏览、加购物车等行为序列),a为动作(表示对当前用户推荐某个商品),r为奖励(表示用户的反馈行为映射成分值),γ为折扣因子,Q为推荐商品a得到的未来可能得到的回报值,E()为期望。 - 状态、动作与奖励
- 状态:以用户过往行为序列为基础,提取用户交互过的商品、对应的时间特征,通过嵌入层和循环神经网络(GRU)提取状态表示。
- 动作:动作空间为当前步骤的候选商品集合,系统需从中选出一个商品作为推荐结果。
- 奖励:根据用户的反馈类型设定,点击=0.1,收藏=0.3,加购=0.5,购买=0.8+0.01*epoch(epoch为训练次数)。
- 模型训练关键技术
- 目标网络:引入目标网络以提高训练稳定性,目标网络与策略网络结构相同,但参数更新频率较低。
- ε-greedy策略:控制探索与利用的平衡,以一定概率随机选择动作(探索),以其余概率选择当前Q值最大的动作(利用)。
- 经验回放机制:将每一步交互生成的五元组(状态、动作、奖励、下一个状态、是否结束)存储到经验池中,网络更新时从经验池中采样批量数据,缓解样本相关性问题。训练过程中,通过计算当前Q值与目标Q值之间的均方误差进行反向传播,更新网络参数。该方法能利用用户与系统的历史交互进行长期策略优化,不依赖人工特征构造,可适应用户兴趣的动态变化。
实现细节
- 数据预处理
对原始行为日志数据按用户进行划分,根据时间顺序构建每位用户的历史行为序列。每条样本包含用户编号、商品交互序列及时间信息,目标行为为用户在当前时间步实际发生的行为。对商品和用户进行离散映射,构建统一的稠密索引,支持嵌入式建模。数据集时间范围为2014年11月18日至12月18日,我们使用前一个月的数据进行模型训练,12月18日当日的行为作为测试集,以确保预测任务与真实业务流程相符。
def build_train_data(df, epoch, max_seq_len, num_candidates=5):
# 定义不同行为对应的奖励值
behavior_reward = {
1: 0.1, # 点击
2: 0.3, # 收藏
3: 0.5, # 加购
4: min(1.0, 0.8 + 0.01 * epoch) # 购买,奖励随训练轮次增加
}
# 按用户ID和时间排序
df = df.sort_values(by=['user_id', 'time'])
# 存储每个用户的行为序列
sequences = defaultdict(list)
# 获取所有商品ID
all_items = list(df["item_id"].unique())
# 构建用户行为序列
for row in df.itertuples():
sequences[row.user_id].append({
'item_id': row.item_id,
'time': row.time.hour,
'behavior_type': row.behavior_type,
'reward': behavior_reward.get(row.behavior_type, 0.0),
'raw_time': row.time
})
data = []
# 生成训练数据
for user_id, seq in sequences.items():
for i in range(1, len(seq)):
# 取用户的历史行为作为状态
history = seq[max(0, i - max_seq_len):i]
# 此处可根据需要对history进行处理,生成训练样本
# ...
data.append(...) # 将处理后的样本添加到数据列表
return data
- 模型实现
DQN代理类实现了策略学习和动作选择等功能。
class DQNAgent:
def __init__(self, q_net, target_net, optimizer, buffer, config):
self.q_net = q_net # Q网络
self.target_net = target_net # 目标网络
self.optimizer = optimizer # 优化器
self.buffer = buffer # 经验回放缓冲区
self.gamma = config["gamma"] # 折扣因子
self.epsilon = config["epsilon"] # ε-greedy策略中的探索概率
self.target_update_freq = config["target_update_freq"] # 目标网络更新频率
self.step_count = 0 # 步数计数
def select_action(self, state, candidate_items):
# 采用ε-greedy策略选择动作
if random.random() < self.epsilon:
# 随机选择一个候选商品(探索)
idx = random.randint(0, candidate_items.size(1) - 1)
return candidate_items[:, idx]
else:
# 选择Q值最大的商品(利用)
q_values = self.q_net(state, candidate_items)
max_indices = q_values.argmax(dim=1)
return candidate_items[torch.arange(candidate_items.size(0)), max_indices]
- 模型评估
每经过一轮迭代(一个epoch),使用当前策略在验证集上进行离线评估,评估指标为推荐成功率(Recall@K),计算公式为:
Recall@K = 推荐的K个商品中用户实际交互过的商品数量 / 用户实际交互过的商品总数
该指标用于衡量预测结果中是否包含用户实际交互的商品。
结果展示
训练过程中,模型的学习任务是在当前状态s下,使动作a在未来带来的期望总回报最大。设计的标签为:
y = r + γmaxQ’(s’,a’)
其中,r为当前状态动作带来的奖励,右边式子表示未来可能动作a’带来的最优价值。通过设计损失函数MSE(均方误差),使模型学习到采取当前动作能够使得Q值最大,即推荐的商品最能让用户满意,损失函数为:
L = (y - Q(s,a))²
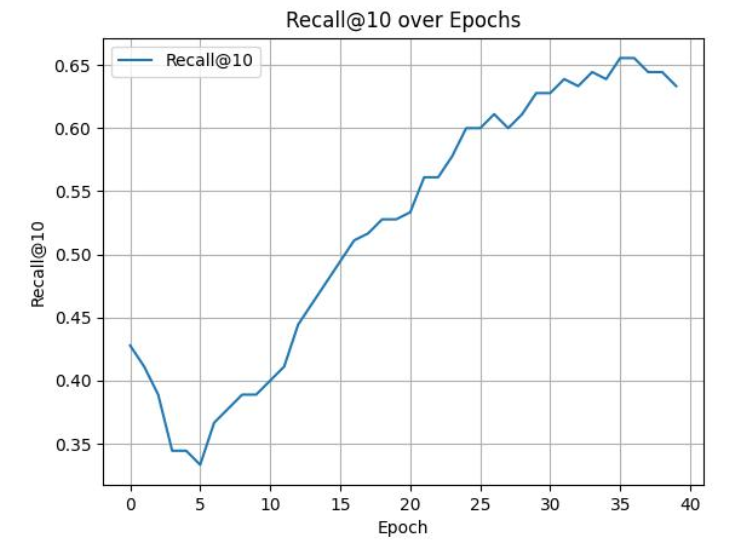
测试的推荐结果显示,每十次训练测试一次,最后的推荐覆盖率能够达到0.65,也就是说推荐4个商品,能够满足用户65%的需求,即预测出该用户将要查看的商品。
模型的整体框架如下:
训练目标的标签定义:
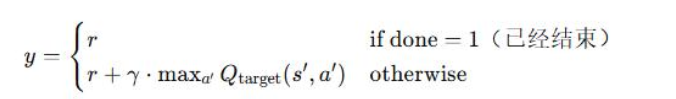
损失函数定义: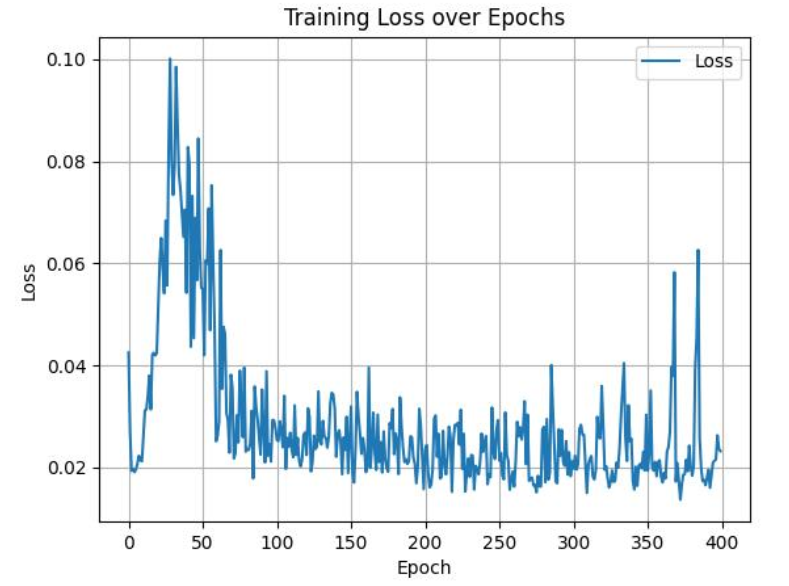
Python深度强化学习智能体DDPG自适应股票交易策略优化道琼斯30股票数据可视化研究
本文介绍了如何使用深度确定性策略梯度(DDPG)算法构建自适应股票交易智能体,对道琼斯30指数成分股进行交易策略优化,并通过数据可视化展示交易效果。
探索观点总结
本文介绍了基于Python-Flask的企业网页平台和基于深度Q网络(DQN)的强化学习推荐系统的设计与实现。通过Flask框架搭建的网页平台实现了用户的注册登录功能,为推荐系统提供了用户交互的基础。基于DQN的推荐系统能够根据用户的历史行为和实时反馈,不断优化推荐策略,实现长期收益的最大化。实际应用结果表明,该推荐系统具有较好的推荐效果,推荐成功率达到了65%,能够有效提升用户体验和企业效益。未来,我们将进一步优化模型结构和训练算法,提高推荐系统的性能和稳定性,同时拓展平台的功能,为企业提供更全面的推荐解决方案。通过这个项目,我们展示了强化学习在推荐系统领域的应用潜力,为企业提供了一种新的思路和方法。我们相信,随着技术的不断发展,强化学习推荐系统将在更多领域得到广泛应用。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!

 DT-GPT大语言模型LLM学习:强化学习RL智能体与DJIA股票数据实证研究|附代码数据
DT-GPT大语言模型LLM学习:强化学习RL智能体与DJIA股票数据实证研究|附代码数据 时序预测、深度强化学习与蒙特卡洛模拟融合:LSTM、GRU、Attention、DQN及多策略智能体的股票交易决策体系构建——以Google股价为例 | 附代码数据
时序预测、深度强化学习与蒙特卡洛模拟融合:LSTM、GRU、Attention、DQN及多策略智能体的股票交易决策体系构建——以Google股价为例 | 附代码数据 Python、Flask、ECharts及MySQL疫情数据可视化系统设计与实现——多模块联动实时展示优化|附代码数据
Python、Flask、ECharts及MySQL疫情数据可视化系统设计与实现——多模块联动实时展示优化|附代码数据 专题:2025年游戏市场洞察报告:市场规模、用户行为、投资趋势|附320+份报告PDF、数据、可视化模板汇总下载
专题:2025年游戏市场洞察报告:市场规模、用户行为、投资趋势|附320+份报告PDF、数据、可视化模板汇总下载



