自2019年12月以来,传染性冠状病毒疾病2019(COVID-19)迅速席卷全球,并在短短几个月内达到了大流行状态。
迄今为止,全球已报告了超过6800万例病例。为了应对这一大流行病,实施了公共卫生政策,通过实施“居家令”政策来减缓COVID-19的传播。
因此,为了检查全球范围内采取的限制措施对人员流动性的有效性,我们帮助客户研究死亡人数与时间的关系。
可下载资源
问题陈述:
该项目的目标是分析各国政府采取的各种限制措施对人员流动性的影响,以控制COVID-19病例和由此导致的死亡人数对经济和失业率的影响。我们使用汇率数据来查看这些限制措施对经济的影响,并在此期间检查失业率的变化。我开发了一个模型来预测由于病例增加而导致的COVID-19相关死亡人数。
使用 read csv 读取数据,然后使用数据可视化探索数据
#columns in the data df.columns视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
数据信息
-数据集中的分类变量:dateRep、countriesAndTerritories、geoId、countryterritoryCode、continentExp -数据集中的无限变量:日、月、年、病例数、死亡数、popData2019、Cumulative_number_for_14_days_of_COVID-19_cases_per_100000
#info about the data df.info()数据集中有 49572 个观测值和 12 个特征值
df.shape
(49572, 12)
#属性/特征之间的相关性
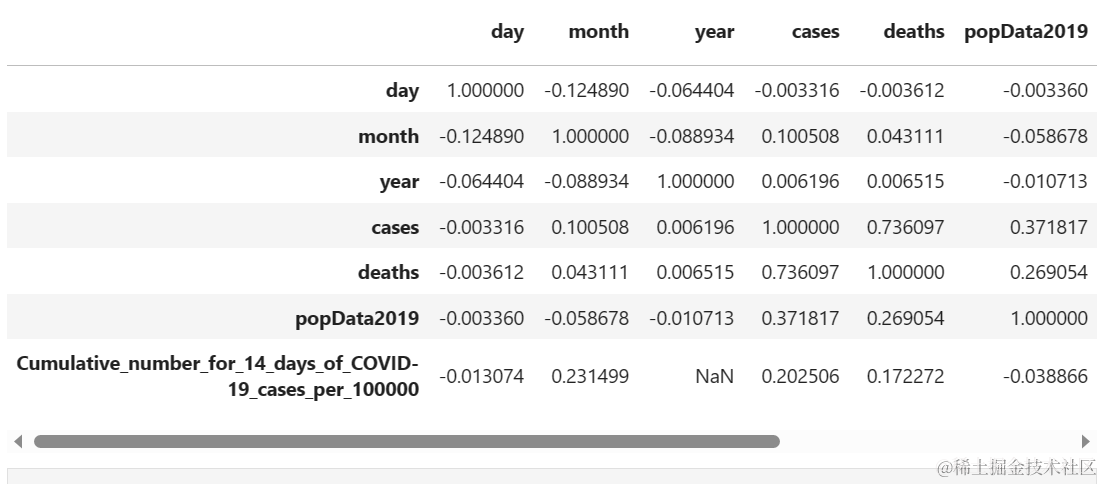
df.corr()
#数据集说明 df.describe()
每天的 14 天累计病例数、病例数和死亡数。
-2783 14 天累计病例数不为零的天数 -报告的 14 天累计病例数为零的天数。 -报告的 14 天累计死亡人数为零的天数。
# 数据清洗-检查是否存在空值 df.isnull() # 这些似乎是数据集中的真实读数,因此将其从数据集中删除可能会改变分析结果。所以保持原样。 print(df["Cumulative_number_for_14_days_of_COVID-19_cases_per_100000"].isnull().value_counts()) # 2783天中没有累积14天病例为零
#可视化
import seaborn as sns
In [107]:
df.columns
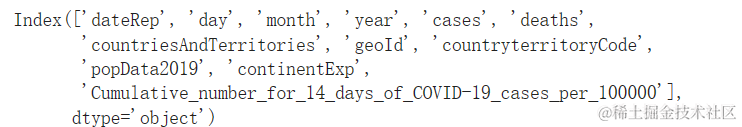
# 该函数接受特征/列名作为输入。
# 绘制特征在天数和月份上的计数情况。
def plots_days_mnths(x):
plt.figure(figsize = (30,20))
feature = ['day','month']
- 病例数的日分析和月分析
- 从病例图中我们可以看出,报告病例从 1 月份开始迅速增加,到 2020 年 7 月至 9 月达到最高峰。
- 而各月每天的报告病例数大致相等。
plots_days
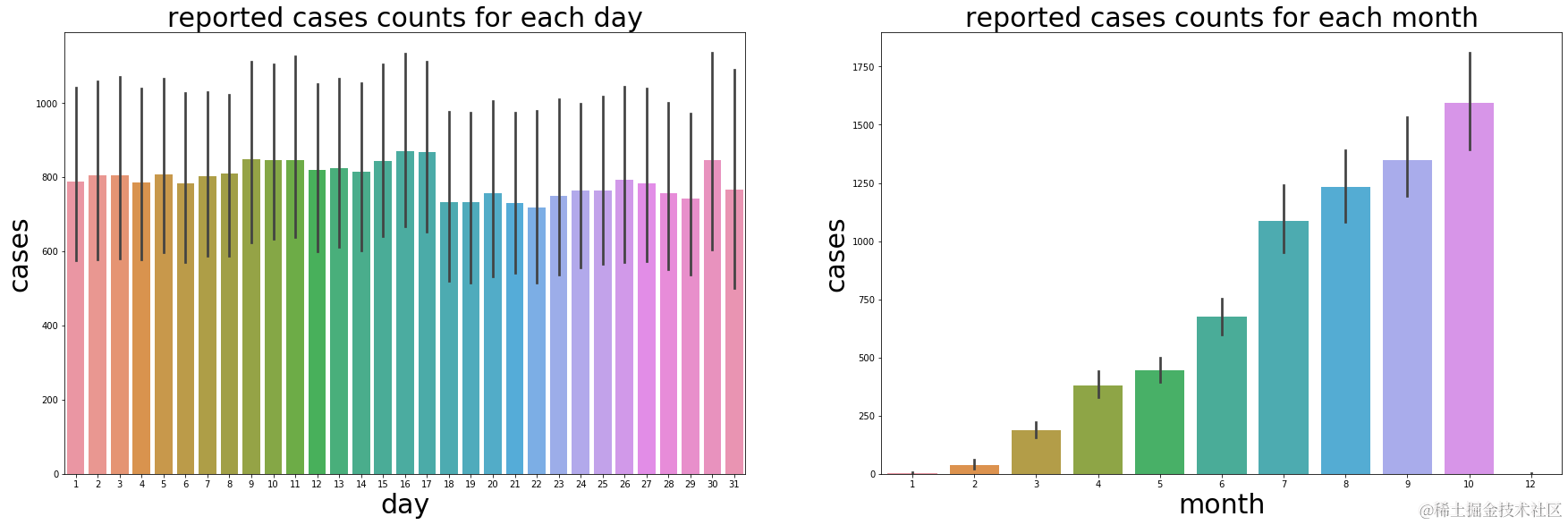
最初几个月报告的死亡病例有所增加,但从图中可以看出,自 7 月份以来已得到控制。
每月各天的报告死亡病例数大体相当,但略有不同。
plots_days_m
import numpy as np
截至 2010 年 10 月,全世界报告的病例总数约为 39400032 例。
df['cases'].sum()

plt.ylabel('Counts', fontsize =14)
plt.title("Histogram of cases ", fontsize = 16)
Out[114]:
[0, 100000, 0, 100]
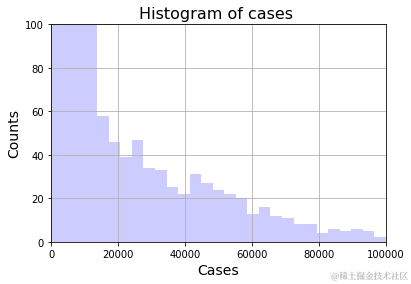
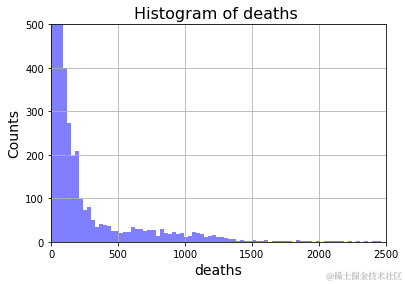
在大多数情况下,每天报告的死亡人数在 500 人及以下。
在大多数天数中,约有 50%的天数每天报告的新病例超过 40000 例。
全世界平均每天报告的死亡人数约为 795 人,平均每天报告的死亡人数为 23 人。
随时关注您喜欢的主题
df[['deaths', 'cases']].mean(axis = 0, skipna = True)

截至 2010 年 10 月,全世界报告的死亡总人数约为 1105353 人
df['deaths'].sum()
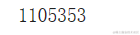
plt.xlabel('deaths', fontsize = 14)
plt.ylabel('Counts', fontsize =14)
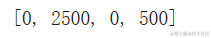
# 将日期列转换为日期时间格式,以便绘制图表。
date = pd.to_datetime(df['dateRep'])
plt.figure(figsize =(15,10))
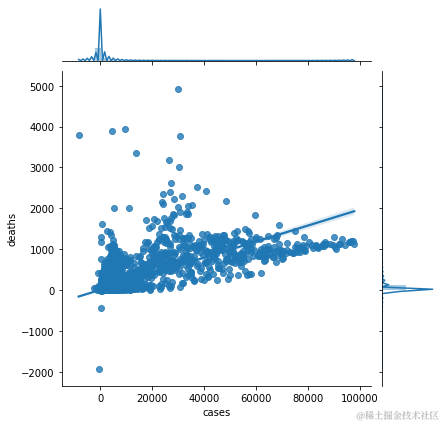
用回归法直观显示病例和死亡人数及其分布情况
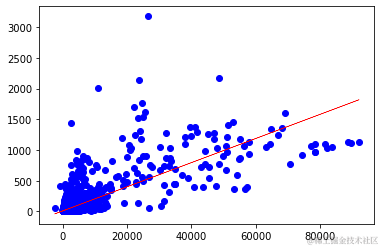
-从图中可以看出,随着病例数的增加,死亡人数也在增加。 -显示出这两个特征之间的正线性关系。
#用回归法直观显示病例和死亡人数及其分布情况 sns.jointplot(x='cases' , y='deaths' , data=df, kind='reg')
按年分析失业率
导入失业数据并将其转换为数据框架
删除列名 “1960 “至 “1990 “之间的所有列,因为它们是空列,数据中没有各县报告的这些年份的数据,还删除了 “指标名称 “和 “指标代码 “这两列,因为分析不需要它们。
#
unemp = unemp.drop(unemp.loc[:, 'Indicator Name':'1990'].columns, axis = 1)
In [590]:
unemp.head(5)
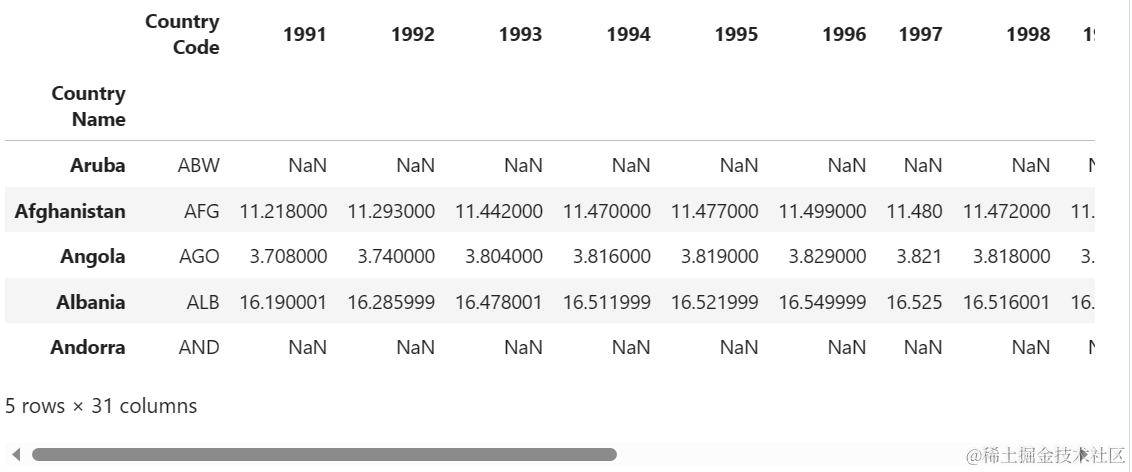
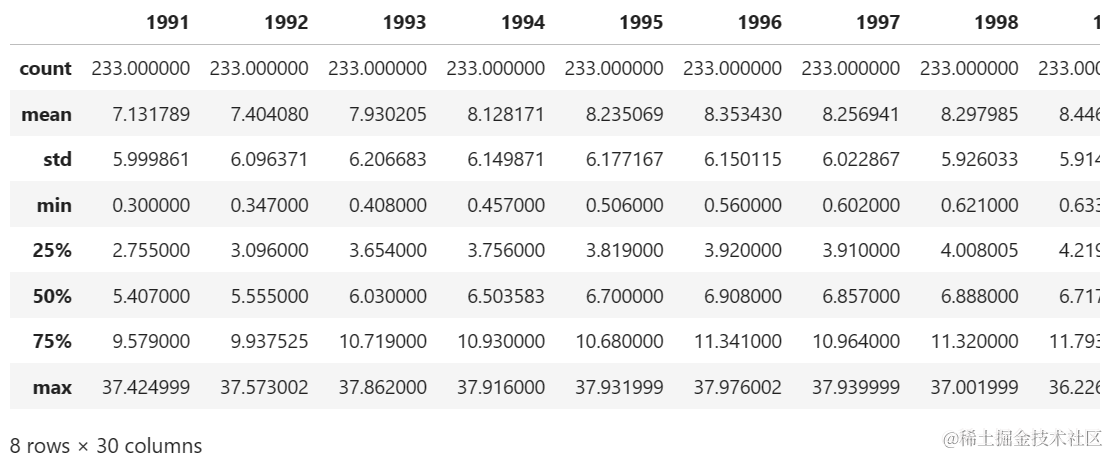
查看 1991 年至 2020 年各国的基本统计数据摘要
unemp.describe()
绘制 1991 年至 2020 年各国就业率曲线的函数
def plot_unemp_region(country):
for c in country:
plt.plot(unemp.loc[c][1:],label = c)
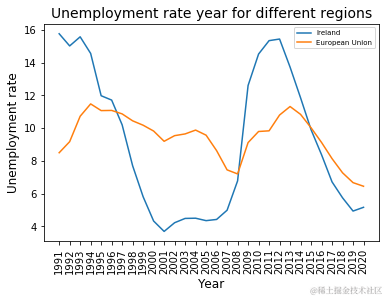
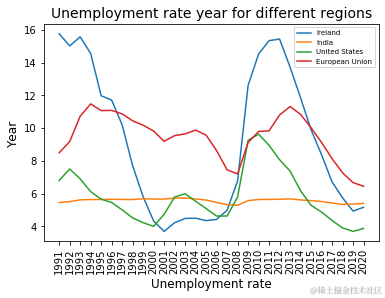
失业率与国家总失业率对比
从 2015 年开始,爱尔兰在控制失业率方面做得更好,因此在 2020 年持续低迷的大流行病期间,爱尔兰在处理失业率方面做得更好。
但从 2019 年开始,爱尔兰的失业率仍有上升趋势,应注意避免进一步的损害。
plot_unemp_regio
不同国家和地区的失业率
在大流行病期间,爱尔兰在处理失业率方面似乎总体上介于欧盟和美国之间,印度在此期间与爱尔兰紧随其后。
数据显示,在过去一年中,美国的失业率在这些国家中最低。
plot_unemp_region(country)
skiprows = [0], index_col = "Date")
In [588]:
cur.head()
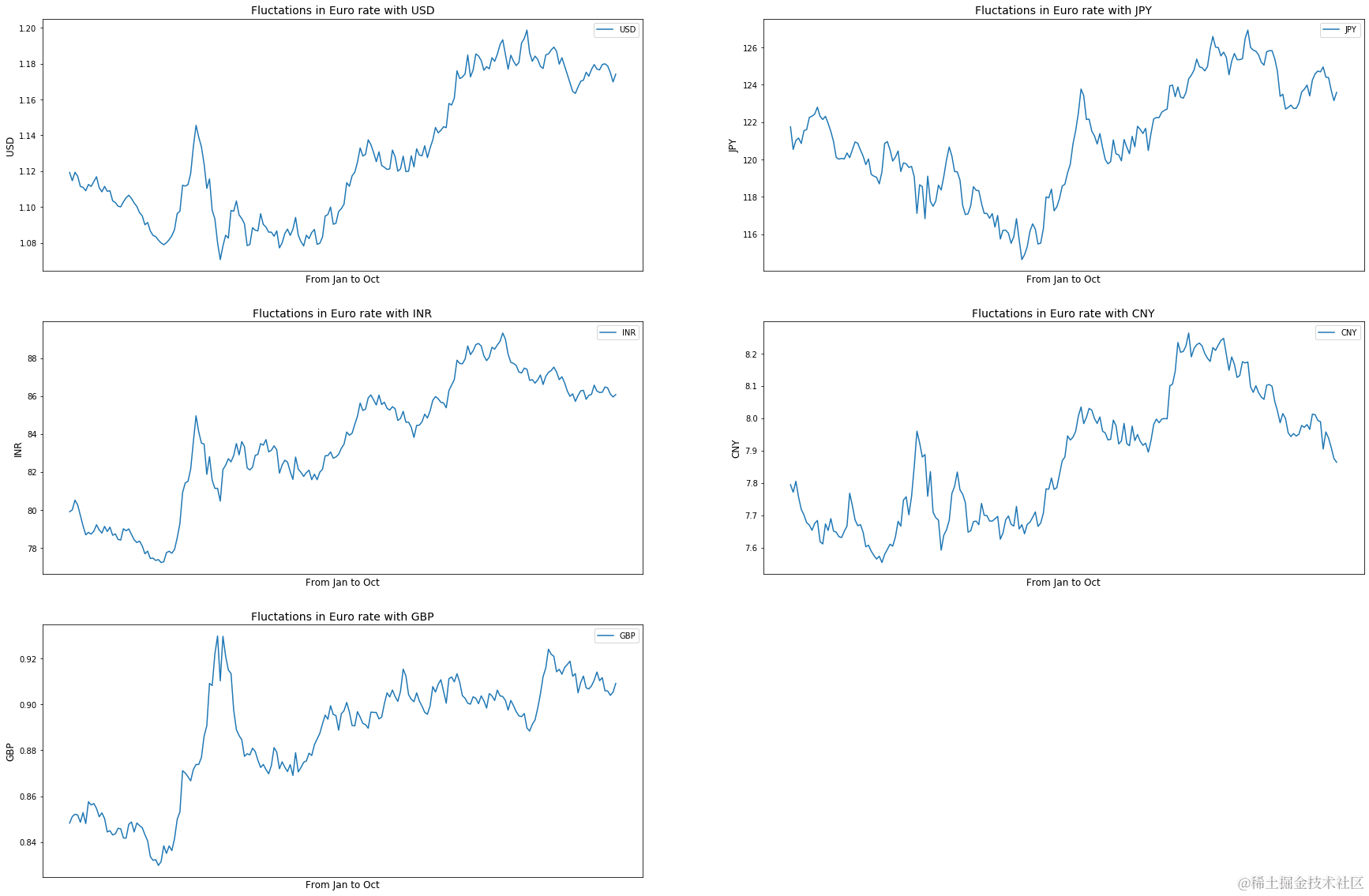
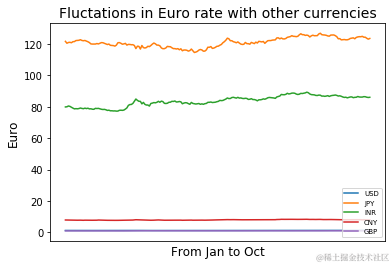
显示欧元相对于其他主要货币波动的功能
输入要与欧元汇率进行比较的货币列表
绘制 2020 年 1 月至 2020 年 10 月期间单个货币相对于欧元的波动图
从图中可以看出,在过去几个月中,欧元相对于美元、日元、人民币等主要货币的汇率走低,这表明由于为控制病毒传播而实施的封锁和限制行动的法律,企业和组织无法正常运作。
欧元估值受中国货币人民币的影响最大,受印度货币卢比的影响最小。
def plot_currency_rate(currency):
plt.figure(figsize = (30,20))
for c in list(enumerate(currency)):
plt.subplot(3, 2,c[0]+1)
plt.plot(cur.loc[:][c[1]],label = c[1])
In [303]:
plot_currency_rate(currency)
for c in currency:
plt.plot(cur.loc[:][c],label = c)
plt.ylabel("Euro", fontsize = 12)
基于每日病例预测死亡的模型开发
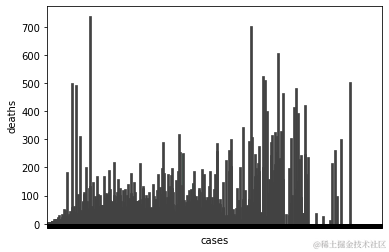
sns.barplot(data=df, x= 'cases' , y = 'deaths' , estimator=np.std)
从下面代码中的相关矩阵图中,我可以看到死亡和病例之间的相关性高达 0.736,而其他变量之间的相关性很弱。
df.corr()
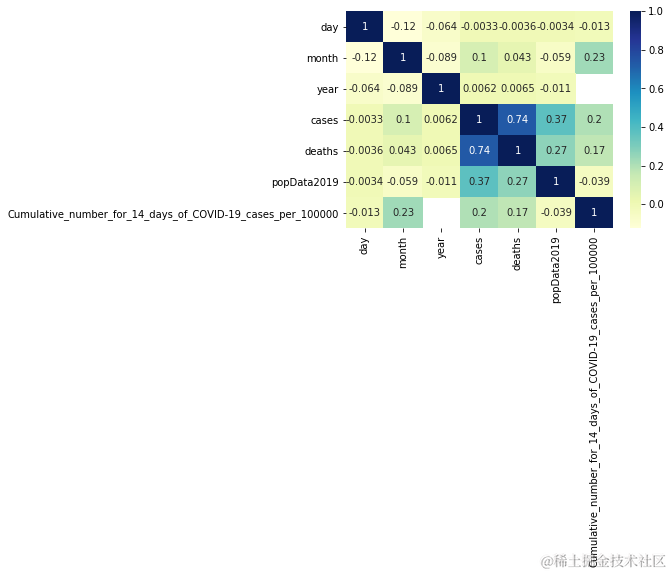
sns.heatmap(df.corr())

sns.heatmap(df.corr(),annot=True , cmap='YlGnBu')
sns.pairplot(df)

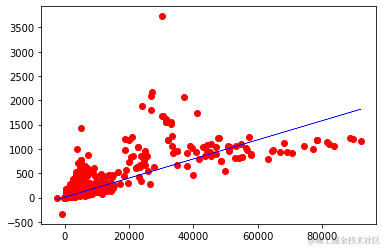
通过可视化观察数据分布,可以清楚地看出病例数的增加导致死亡人数的增加。因此,为了根据全国每天的病例数预测死亡人数,我们使用了线性回归法来完成这一过程,结果如下。
这段代码用于将数组或矩阵随机分割成训练集和测试集。
# 用于将数组或矩阵随机分割成训练集和测试集
from sklearn.model_selection import train_test_split
自变量为 cases,因变量为 deaths,分别赋值给 X 和 y。
X, y = df[['cases']], df['deaths']
- X 是包含 “cases” 条目的数据框(DataFrame)的一列,y 是包含目标/响应变量 “deaths” 的序列(Series)。
X.head(5)
- 数据被划分为测试集和训练集,使用 train_test_split() 函数,以 80:20 的比例进行划分。
- train_test_split() 函数中的 test_size 参数设为 0.2,表示将 20% 的数据作为测试集。
# 训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
在 [565] 处:
# 定义一个线性回归模型
from sklearn import linear_model
# 使用训练集训练模型
regr.fit(X_train, y_train)
回归系数
- 回归系数是未知总体参数的估计值,表示预测变量(cases)与响应变量(deaths)之间的关系。
- beta0 的回归系数为 0.0196,这意味着平均而言,当没有报告病例时,死亡人数为 0.0196。
- 截距系数为 6.759,说明每天病例增加一个单位时,死亡人数增加 6.759。例如,每增加 100 个新病例,死亡人数每天增加 7.5。
- 对测试数据进行线性模型预测死亡人数
#基于测试数据进行预测
y_pre
结果:

# 每天对应病例数量的实际死亡人数
y_test.head(10)
结果:
df.head()
结果:
计算评估指标需要重新调整 X 的形状:
# 重新调整 X 的形状以计算指标
X.values.reshape
结果:
<function ndarray.reshape>
计算均值绝对误差(MAE):
from sklearn.metrics import mean_squared_error,r2_score , mean_absolute_error
平均绝对误差(MAE)
- 平均绝对误差(MAE)是用于回归模型的另一种损失函数。
- MAE 是目标变量和预测变量之间的绝对差的总和。
- 我们有实际值 y_test 和预测值 y_pre,可以观察到它们之间的差异。
#MAE
mean_absolute_error(y_test , y_pre)
结果:
18.3128
R-Squared
- R-squared 是衡量数据与拟合的回归线之间接近程度的统计指标。
- 提供了关于预测变量“cases”在我们的模型中如何解释响应变量“death”的程度的指示。
- 我的模型使用预测变量“cases”能够解释响应变量“death”的变异程度为61%。
#R方分数
r2_score(y_test , y_pre)
结果:
0.6156843
散点图展示了线性回归线以及数据围绕该线分布的情况。
plt.scatter(X_test, y_test , color= 'blue' , linewidths=1)
g
输出[579]:
0.615
输入[580]:
# 构建随机森林模型。
输入[581]:
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor
输入[582]:
rfr.fit(X_train, y_train)

Y_pred = rfr.predict(X_test)
输入[584]:
rfr.score(X_test, y_test)
输出[584]:
0.39
输入[585]:
plt.scatter(X_test, Y_pred, color='red')
plt.plot(X_test, y_pre, color='blue', linewidth=0.5)
结论
通过探索性数据分析,发现每天新冠病例增加时,报告的死亡人数也会有所上升。通过将病例作为预测因子、每天的死亡人数作为目标变量的两个回归模型的结果,线性模型在预测每天的死亡人数方面更准确,与每天报告的病例数相关。
通过对包含失业率和欧元汇率数据的数据集进行数据可视化分析,还能够探索各国为限制病毒传播而引入的限制措施对欧洲主要经济体和失业率产生的影响。
欧元兑美元、英镑、人民币等主要货币的汇率在过去几个月中看到了下降,这表明封锁措施对企业和国家经济的影响。对失业率的影响也在失业率数据中清晰可见,爱尔兰的失业率相对于其他国家来说处理得更好,但在过去几个月中失业率明显上升。
参考资料
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!

 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据
Python和Lag-Llama金融时序预测收益率零样本与微调对比回测实证研究|附代码数据



