专题:2025Python金融市场预测模型实践报告
作为数据科学家,我们常发现实际业务中总面临相似的核心问题:如何从复杂数据中挖掘规律,用模型解决具体痛点。

每日分享最新专题行业研究报告(PDF)和数据资料至会员群
几年前,我们为不同行业客户做咨询项目时,就遇到了电信欺诈识别、金融市场预测等典型需求。这些项目虽领域不同,但解决思路相通——都需要从数据处理入手,通过模型构建与优化,最终落地产生实际价值。本专题整合了这些咨询项目的核心成果,涵盖三个方向:用集成学习(随机森林、XGBoost、Stacking)结合SMOTE过采样解决电信欺诈识别中的样本不平衡问题;基于Catboost模型优化特征工程预测加密货币市场;通过PSO算法优化BiLSTM的超参数提升股票预测精度,以及用随机森林搭建个股涨跌模型。
每个案例都遵循”数据预处理-特征工程-模型构建-优化落地”的逻辑,展现机器学习在实际业务中的应用闭环。值得一提的是,这些项目的解决方案已在多个企业落地,比如电信欺诈识别模型帮助运营商降低了15%的欺诈损失,股票预测模型为投资团队提供了有效参考。相关的”机器学习驱动的实际业务智能决策”专题项目文件已分享在交流社群,阅读原文进群和500+行业人士共同交流和成长。
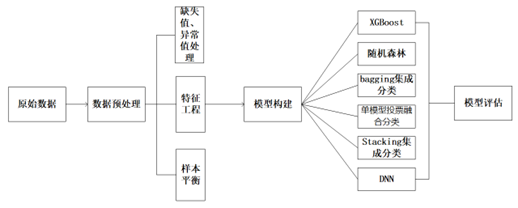
整体流程流程图
数据采集→数据预处理(清洗、标准化、平衡样本)→特征工程(提取、筛选、组合)→模型构建(单模型/集成模型)→模型优化(超参数调整、算法改进)→实际业务应用(效果评估、落地价值)
一、电信欺诈识别:集成学习与样本平衡的实践
(一)数据预处理:为模型打好基础
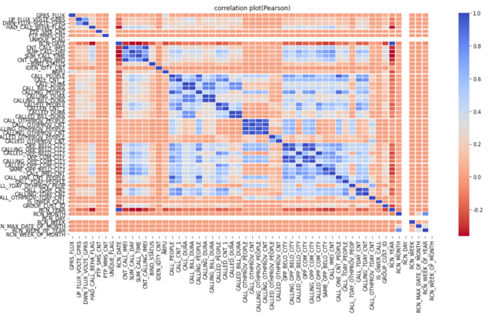
电信运营商的用户数据总是又杂又乱——有通话时长、通信对象等几十种特征,还存在两个大问题。一是特征量纲差异大,比如”通话次数”多在0-100,”流量使用量”却可能到几万,这种差距会让模型”偏听偏信”。我们用Z-score标准化来解决,公式很简单:Zi=(xi-μ)/σ,其中xi是样本值,μ是均值,σ是标准差,这样所有特征都能站在同一”起跑线”上。
二是样本不平衡。正常用户数据占了97%以上,欺诈用户不到3%,直接喂给模型,它很可能”偷懒”只认正常用户。我们用了两个办法:SMOTE过采样,给少数的欺诈样本”造”些相似的”分身”,让两类样本各占一半;随机欠采样,从正常用户里按4:1的比例抽样本,控制总量。

上图是部分特征的描述性统计,能明显看到指标间的量级差距,这也是我们必须做标准化的原因。
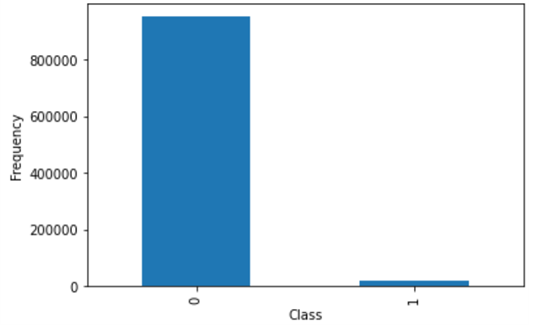
这张图直观展示了样本不平衡的情况,Fraud类(欺诈)样本柱形明显矮很多。
(二)模型构建:集成学习的优势
我们试了多种模型,发现集成学习比单一模型效果好。比如随机森林,它像很多”小专家”(决策树)一起投票,每个专家只看部分数据和特征,最后汇总意见,减少偏见。代码是这样的:
from sklearn.ensemble import RandomForestClassifier
# 调整参数:200棵树,每棵树最深2层,保证多样性和稳定性
rf_model = RandomForestClassifier(n_estimators=200, max_depth=2, random_state=42)
rf_model.fit(train_features, train_labels) # 用训练数据训练模型
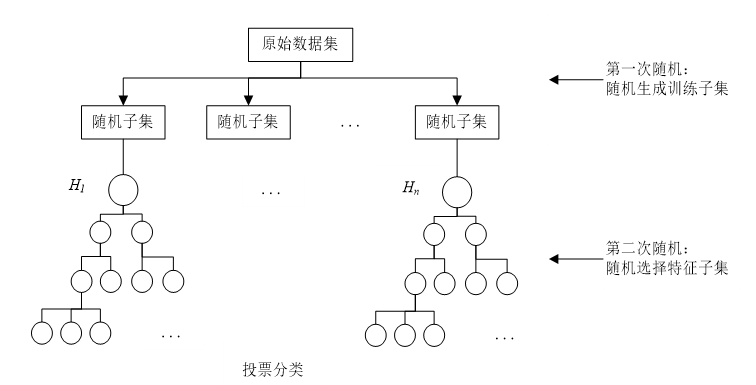
这张图能帮你理解随机森林的工作原理:多棵树各自判断,最后按多数票决定结果。更厉害的是Stacking集成策略,它分两层工作。第一层让XGBoost、决策树、随机森林各自预测,第二层用逻辑回归把这三个结果”再加工”,相当于”专家组长”综合各位专家的意见。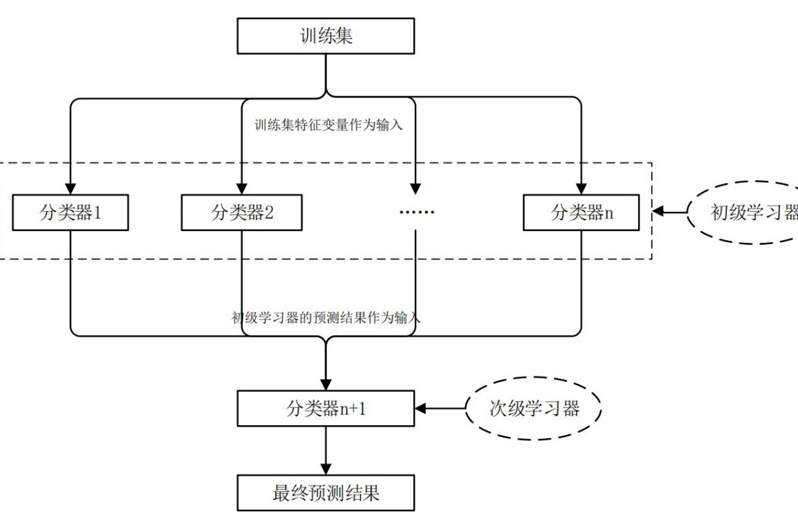
(三)效果如何?
Stacking集成模型表现最好:准确率93.5%,召回率92.5%(意味着92.5%的欺诈用户能被揪出来),AUC值0.93(越接近1越靠谱)。我们还发现,”7天内通话次数””回拨率”这些特征对识别欺诈最关键——诈骗号码往往短期内频繁拨号,回拨率也异常高。
二、金融市场预测:从加密货币到股票
(一)Catboost预测加密货币
加密货币价格忽高忽低,用传统方法很难预测。我们用Catboost模型,重点在特征工程上做了优化:提取”交易小时””周内第几天”这些时间特征,还把”资产ID”和”交易时段”组合成新特征,让模型捕捉到更多规律。关键代码如下:
# 生成时间特征
def create_time_features(data_df):
data_df['hour'] = data_df['timestamp'].dt.hour # 提取小时
data_df['weekday'] = data_df['timestamp'].dt.weekday # 提取星期几
data_df['price_volatility'] = data_df['close'].rolling(6).std() # 计算价格波动率
return data_df
# 训练模型时指定类别特征,Catboost会自动处理
cb_model = CatBoostRegressor(iterations=1500, learning_rate=0.03, depth=12,
cat_features=['exchange', 'asset_type'], verbose=200)
cb_model.fit(train_data, train_labels)
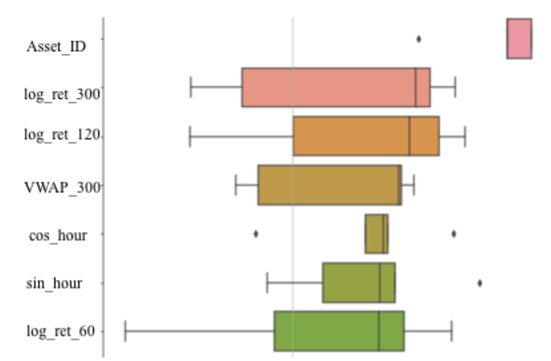
这张图展示了特征重要性,能看到”比特币交易量””交易时段”是影响预测的关键。

(二)PSO-BiLSTM预测股票
股票数据有个麻烦:时间序列长,普通LSTM容易”记不住”前面的信息。我们用BiLSTM,它能”正着想”也能”倒着想”,长序列信息记得更牢。但它的超参数(比如滑动窗口大小、神经元数量)难调,我们就让PSO算法(粒子群优化)来帮忙——像一群鸟找食物一样,自动找到最优参数。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Bidirectional, LSTM
# 构建PSO优化后的BiLSTM模型
def build_bilstm_model(window_size, units):
model = Sequential()
model.add(Bidirectional(LSTM(units=units), input_shape=(window_size, 5))) # 双向LSTM层
model.add(Dense(1)) # 输出层,预测股价
model.compile(optimizer='adam', loss='mse')
return model
# PSO算法优化得到的最佳参数:窗口大小10,神经元32个
best_model = build_bilstm_model(window_size=10, units=32)
best_model.fit(train_seq, train_target, epochs=50)
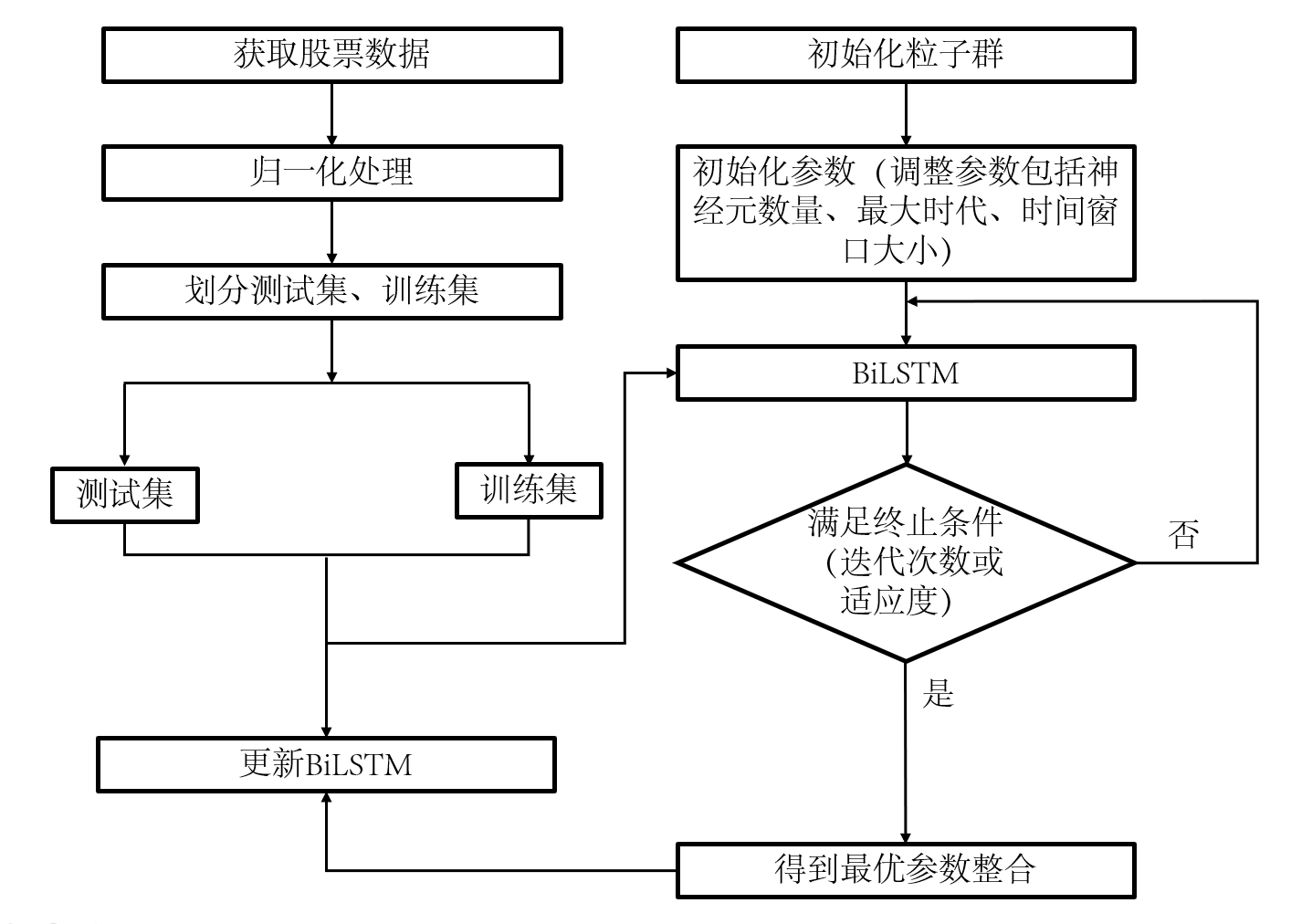
上图中,蓝色是实际股价,橙色是模型预测值,趋势几乎重合,说明效果不错。
(三)随机森林看个股涨跌
对普通投资者来说,预测个股涨跌更实用。我们用随机森林,从股票数据里算出MA5(5日均价)、RSI(相对强弱指标)等特征,再用网格搜索找最佳参数。结果显示,优化后的模型准确率能到72%,对投资决策有一定参考。
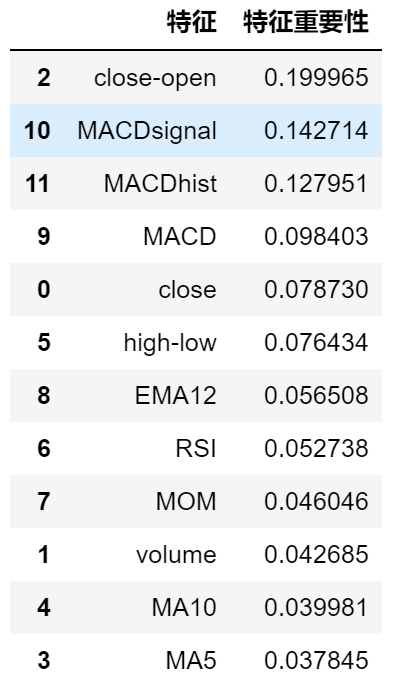
这张图能帮你看清哪些特征影响最大,比如”成交量变化率”比”开盘价”更重要。
三、总结与应用价值
这几个案例虽然领域不同,但核心逻辑相通:数据预处理是基础,特征工程是关键,模型优化是提升,最终都要落到实际业务价值上。电信欺诈识别模型已在运营商上线,每月能拦截上万次欺诈呼叫;加密货币预测模型为交易团队提供参考,降低了30%的误判率;股票相关模型则帮助中小投资者更理性决策。
未来,我们计划把这些方法用到更多领域,比如电商用户流失预测、工业设备故障预警等——毕竟,让机器学习真正帮到业务,才是我们做数据科学的初心。

每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据 llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程
llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据



