Python电影票房预测模型研究
2025年1月,猫眼研究院的一份数据让电影行业陷入沉思:2024年中国电影总票房425.02亿,比2023年少了近120亿,同比降幅23%;全年票房超10亿的新片仅7部,市场连“扛票房”的头部作品都稀缺。

本项目报告、代码和数据资料已分享至会员群
更揪心的是,即便疫情结束两年,行业仍没走出低谷——2024年春节档8部影片,有4部临时撤档,《我们一起摇太阳》甚至在声明里直接承认“档期选得不对”。这不是个例。电影行业向来是“高投入高风险”,但现在的问题是,很多片方还在用“经验判断”做决策:凭感觉选档期、靠人脉定宣发预算,结果就是《阿修罗》这样的项目——投资7.5亿,上映3天票房才5000万,最后撤档亏损近7亿。本文内容,改编自我们为一家影视投资机构做的定制咨询项目,核心就是用大数据和机器学习,帮行业跳出“经验陷阱”。
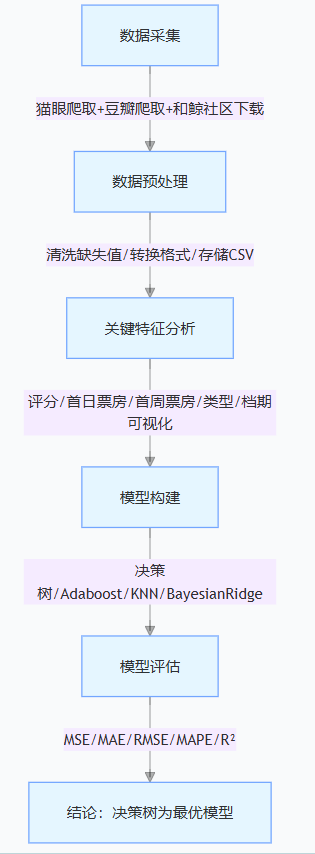
我们采集整合了2011-2025年猫眼、豆瓣、和鲸社区的多源数据,用Python爬取并清洗出2197条有效数据;然后找出影响票房的5个关键因素(评分、首日票房、首周票房、电影类型、档期),用图表直观呈现它们和票房的关系;最后建了4种机器学习模型(决策树、Adaboost、KNN、BayesianRidge),通过MSE、R²等指标比出最优方案。
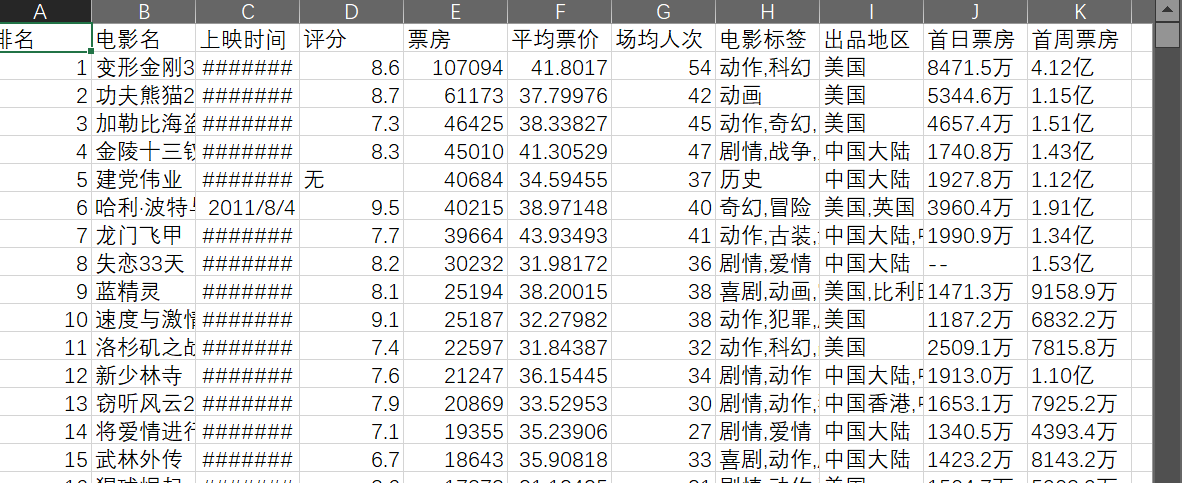
数据截图
对投资方来说,这能帮你避开“高投入低回报”的坑;对营销团队来说,这能让宣发预算花在刀刃上;对发行方来说,这能精准选到“能卖座”的档期。现在,XXX专题项目文件已经分享在交流社群,阅读原文进群,就能和500+电影行业从业者、数据分析师一起交流,少走决策弯路。
研究脉络流程图:1张图看懂票房预测全流程
1 绪论:为什么现在必须做数据化票房预测?
1.1 研究背景:2024年电影市场的“惨”,藏着预判失效的祸根
2024年的电影市场,用“惨淡”形容毫不为过:总票房比2023年少了近120亿,观影人次虽然破了10亿,但票房超10亿的新片只有7部——比前几年少了一半还多。更关键的是,很多影片输在“预判”上:有的选了错误的档期,有的高估了自身题材的吸引力,最后要么撤档,要么血本无归。电影行业不是“拍好片子就有人看”,它的高投入特性(一部大片投资动辄几亿),决定了“票房预测”是必选项:投资方要靠它控制成本,避免钱砸进去收不回;制片方要靠它定题材、选演员,不然拍出来的片子没人买账。就像2018年的《阿修罗》,本来想靠“大制作”冲票房,结果因为没预判到市场反应,上映3天就撤档,近7亿投资打了水漂。下面这张图是2015-2024年的总票房和同比增幅,能清楚看到2024年的下滑有多明显——这也说明,靠经验“拍脑袋”的时代,真的过去了。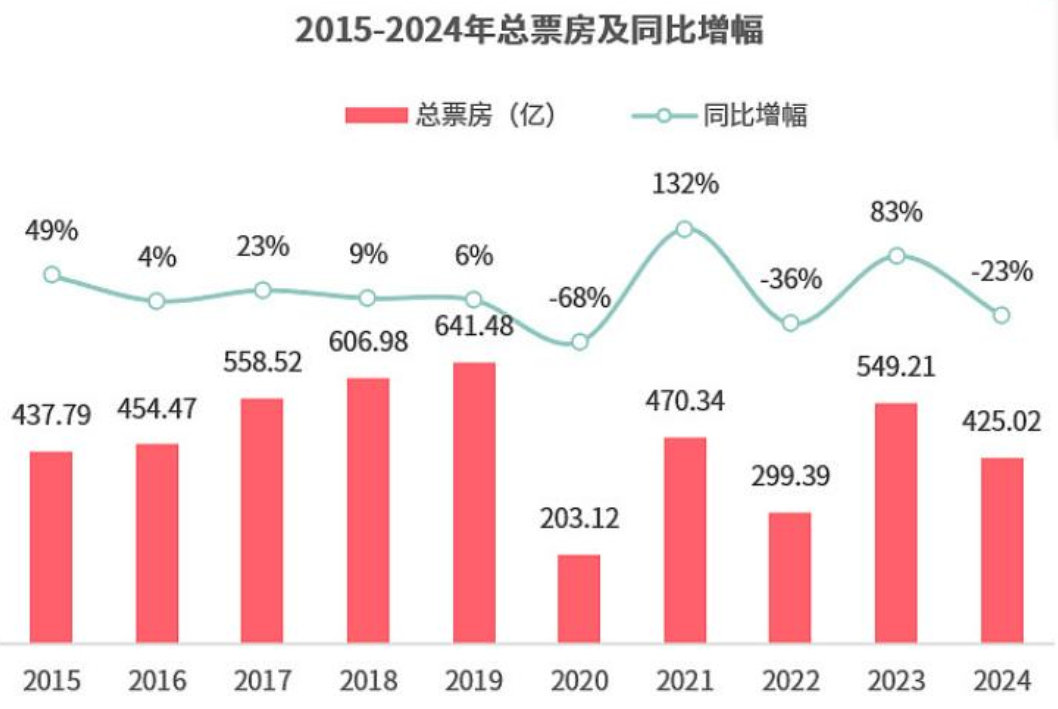
1.2 研究意义:3个维度帮行业解决实际问题
- 投资方:少踩“高风险”的坑
模型能把“主演、题材、档期”这些模糊因素量化,比如后面会讲到“科幻类型平均票房最高”,那投资方就可以优先考虑这类题材,不用再凭感觉赌运气。 - 营销方:让宣发钱花得值
要是模型预判某部影片是“高潜力”,就能加大短视频物料投放、多做话题预热;要是“中等潜力”,就精准定位特定人群(比如青春片瞄准学生),提升长尾票房。 - 发行方:选对档期等于成功一半
后面的数据会显示“春节档平均票房最高”,那发行方就可以把优质影片往这个档期推,和院线谈排片时也有数据支撑,不用再靠“人情关系”。
1.3 研究内容:4步完成从数据到决策的落地
- 数据采集与预处理:用Python爬取多平台数据,删掉没用的信息、统一格式,最后留下2197条有效数据;
- 特征分析:找出对票房影响最大的5个因素,用图表让“评分高票房高”“春节档卖座”这些结论更直观;
- 模型构建:建4种机器学习模型,看哪种最适合预测票房;
- 模型评估:用专业指标检验模型准不准,最后选出最好用的那个。
2 需求分析与总体设计:怎么建一个“能用的”预测模型?
2.1 需求分析:行业现在最缺什么?
2.1.1 行业痛点:3个问题让传统预判失效
现在电影行业做票房预判,主要靠发行方、制片人的“经验”,这就导致3个问题:
一是“拍脑袋决策”,比如觉得“这个演员人气高就一定卖座”,结果排片多了但观众不买账,资源全浪费;
二是“突发情况应对不了”,比如影片快上映了,主演出了负面新闻,这种情况经验根本没用;
三是“数据不互通”,猫眼有票房数据、豆瓣有评分数据、微博有话题数据,但这些数据分散在不同平台,没人整合起来用。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
2.1.2 任务目标:模型要帮行业解决3件事
- 数据层面:能拿到电影的类型、票房、上映时间这些基础信息,还要把重复的、缺漏的数据处理好,保证数据准;
- 特征层面:自动找出对票房影响大的因素,比如把“上映时间”分成“春节档、暑期档”,这样比直接用日期好分析;
- 模型层面:能同时试多种模型,最后选出最准的那个,不用再靠“单一模型赌结果”。
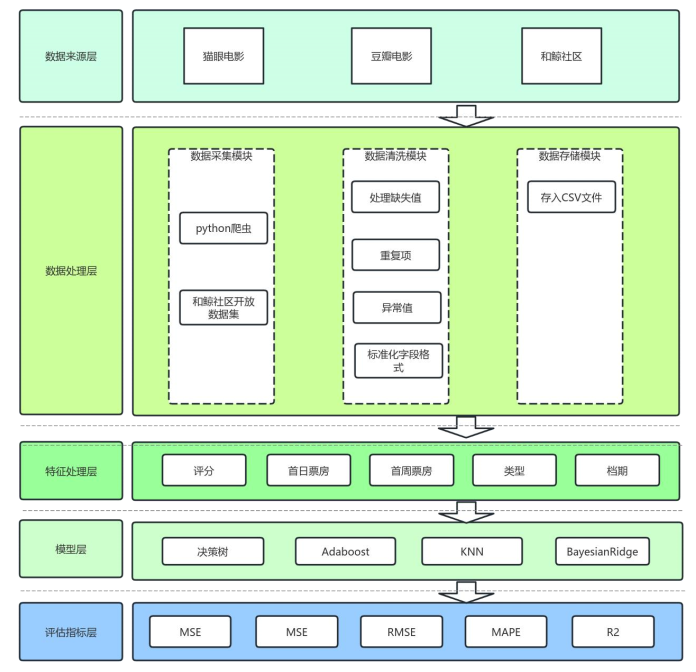
2.2 总体设计:5层架构确保模型“好用又准”
我们设计了一个“数据-处理-特征-模型-评估”的闭环架构,每一层都对应具体的业务需求:
- 数据来源层:从猫眼、豆瓣、和鲸社区拿数据,涵盖影片名称、评分、票房、上映时间这些关键信息;
- 数据处理层:爬来的数据先清洗(删缺失值、去重复),再统一格式(比如票房都转成“万”为单位),最后存成CSV文件方便用;
- 特征处理层:从数据里挑出5个关键因素(评分、首日票房、首周票房、类型、档期),分析它们和票房的关系;
- 模型层:建4种回归模型(决策树、Adaboost、KNN、BayesianRidge),分别做预测;
- 评估指标层:用MSE(均方误差)、MAE(平均绝对误差)、RMSE(均方根误差)、MAPE(平均绝对百分比误差)、R²(决定系数)这5个指标,看哪个模型最准。
下面这张图是研究架构图,能清楚看到每一层的作用:
下面这张是实施流程图,从数据采集到得出结论,每一步都很明确: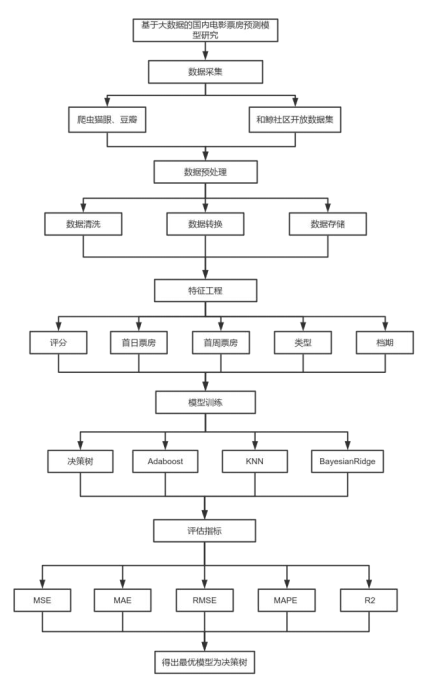
3 数据采集与预处理:好数据才是好模型的基础
3.1 数据采集:从3个平台拿到“有用的数据”
我们的数据主要来自猫眼、豆瓣和和鲸社区,这里以猫眼数据爬取为例,讲下关键步骤——毕竟爬对数据,后面的预测才准。
3.1.1 构建请求:避开反爬,拿到全量数据
猫眼的年度票房榜页面,数据都在一个页面里,不同年份只需要改URL里的“year”参数。为了不被网站拦截,我们先构建一个“请求头”,模拟浏览器访问,再用循环爬取2011-2025年的数据。关键代码如下:
# 主函数:爬取2011-2025年电影数据
if __name__ == '__main__':
# 构建请求头,模拟浏览器访问(避免被反爬)
header_info = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0'
}
# 循环生成各年份URL并爬取数据
for year in range(2011, 2026):
target_url = f'https://piaofang.maoyan.com/rankings/year?year={year}&limit=100&tab=1&WuKongReady=h5'
# 调用自定义函数获取电影信息(片名、票房、评分等)
fetch_movie_data(target_url, header_info, year, csv_writer, '猫眼电影票房榜_所有年份.txt')
print('所有年份数据爬取完成!')
3.1.2 解析与存储数据:提取关键信息,避免乱码
用BeautifulSoup解析网页,把电影名、票房、评分、上映时间这些有用的信息提出来,再存成CSV格式——存的时候用“utf-8-sig”编码,避免中文乱码。下面这张图是采集后的数据示例,能看到每部电影的关键信息都很全: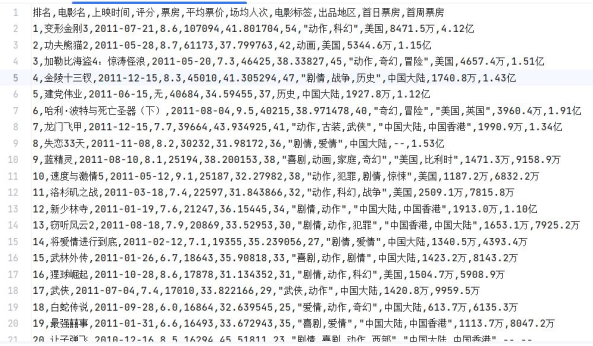
3.2 数据预处理:把数据“修”成能用的样子
爬来的原始数据不能直接用,比如有的电影“出品地区”写的是“中国大陆”,有的是“中国香港”,还有的缺评分数据,这些都要处理。
3.2.1 数据清洗:删掉“没用的”,留下“准的”
我们的研究只关注国内电影,所以先把“出品地区”统一改成“中国”(包括大陆、香港、台湾);然后删掉有缺失值、异常值的数据——比如有的电影没写首日票房,这种数据要是留着,会让后面的预测不准,所以直接删掉。
下面两张图是清洗前后的缺失值对比,左边是清洗前,能看到很多特征有缺失;右边是清洗后,所有缺失值都删掉了:

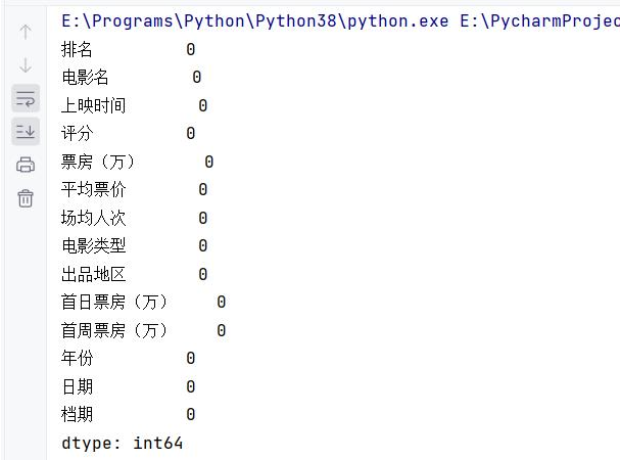
3.2.2 数据转换与存储:让数据“好分析”
我们做了3件事:
一是统一票房单位,所有票房都转成“万”为单位,避免有的用“亿”、有的用“万”搞混;
二是归类电影类型,比如“恐怖”和“惊悚”很像,就合并成“恐怖类”,这样分析起来更清楚;
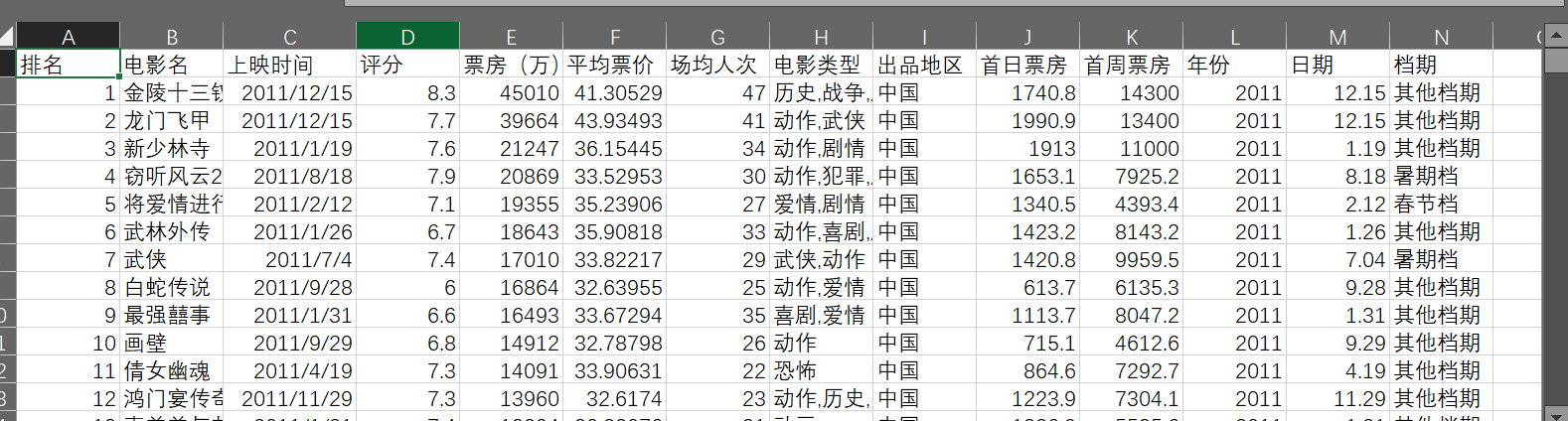
三是新增“档期”特征,把上映时间分成6类:大年三十到正月十五是春节档、12.31-1.3是元旦档、5.1-5.5是五一档、6.1-8.30是暑期档、9.30-10.7是国庆档,剩下的都是“其他档期”。
下面这张图是预处理后的数据,能看到格式统一、信息清晰,这样后面做分析和建模才顺手:
4 电影票房影响因素分析:哪5个因素决定了电影卖不卖座?
4.1 评分:豆瓣评分高的电影,票房真的更好吗?
豆瓣评分是观众看完电影后的“真实反馈”,没看过的人会参考这个评分决定要不要去看——所以评分肯定会影响票房。我们随机抽了1000个样本,用散点图看评分和票房的关系,关键代码如下:
# 随机抽1000个样本(减少绘图时间)
sample_data = df.sample(n=1000, random_state=42)
# 设置图表大小和清晰度
plt.figure(dpi=150, figsize=(6, 4))
# 画散点图:x轴是票房,y轴是评分
sns.scatterplot(x='票房(万)', y='评分', data=sample_data, color='blue', alpha=0.3, s=40)
plt.title('票房与评分散点图')
plt.xlabel('票房(万)')
plt.ylabel('评分')
plt.show()
下面这张散点图很明显:评分越高的电影,票房高的概率越大。比如评分在8分以上的影片,很多票房都超过了10000万——这也说明,做好影片质量、拿到高评分,对票房很重要。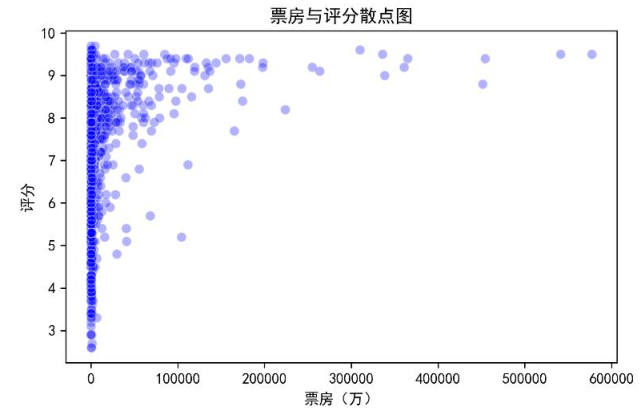

4.2 首日票房:上映第一天的票房,能预判最终成绩吗?
首日票房反映两件事:一是影片前期的关注度(比如有没有话题度),二是宣发力度够不够。2025年春节档首日票房就很高,总共17.9亿,其中《哪吒之魔童闹海》贡献了4.8亿,《唐探1900》贡献了4.6亿——这两部片子后面的总票房也都不错。
我们随机抽了15部电影,用折线图对比首日票房和总票房的趋势,结果如下:
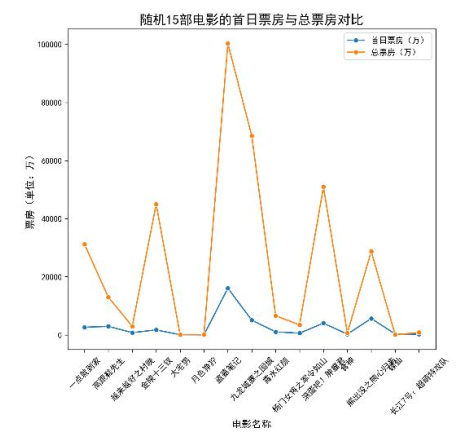
能看到两条线的趋势几乎一致:首日票房高的,总票房也高。这对行业很有用:发行方可以根据首日票房调整排片(比如首日卖得好,就多给排片场次);宣发方要是看到首日票房低,就赶紧加预算做推广,不然后面更卖不动。
4.3 电影类型:哪种类型的电影最容易卖座?
不同类型的电影,观众群体不一样——有的观众喜欢科幻,有的喜欢喜剧。我们把电影类型归类后,算了每种类型的平均票房,关键代码如下:
# 计算每种类型的平均票房
type_avg_box = {type_name: sum(box_list)/len(box_list) for type_name, box_list in type_boxoffice.items()}
# 按平均票房从高到低排序
type_avg_box = dict(sorted(type_avg_box.items(), key=lambda x: x[1], reverse=True))
# 画柱状图:x轴是类型,y轴是平均票房
plt.figure(figsize=(12, 6))
plt.bar(type_avg_box.keys(), type_avg_box.values(), color=colors)
plt.xticks(rotation=45) # 旋转x轴标签,避免重叠
plt.xlabel('电影类型')
plt.ylabel('平均票房(万)')
plt.title('不同电影类型的平均票房对比')
plt.show()
下面这张图很清楚:科幻类型的平均票房最高,比其他类型高出一大截;而恐怖类型的平均票房最低。这对投资方来说是重要参考——要是想降低风险,优先选科幻、喜剧这些大众喜欢的类型,别轻易碰恐怖、西部这类小众题材。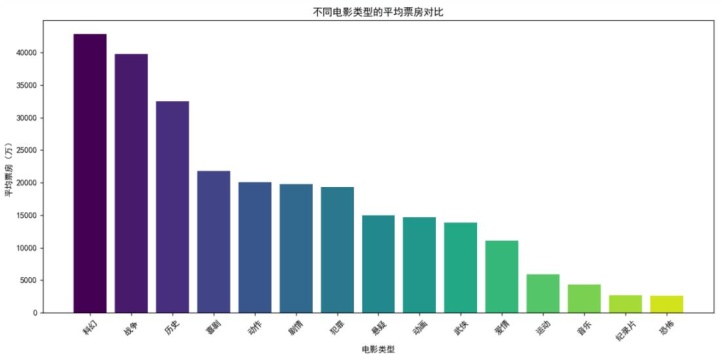
4.4 档期:选对档期,票房能差多少?
上映时间对票房的影响太大了——春节大家都有空看电影,暑期有学生群体,这些档期的票房肯定比平时好。我们把档期分成6类,算了每类的平均票房,结果如下:
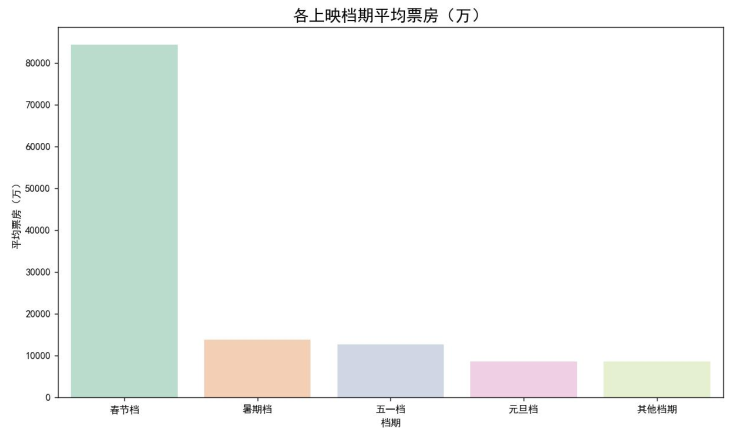
能看到春节档的平均票房最高,比“其他档期”高出好几倍;其次是暑期档和国庆档。这给发行方提了个醒:要是手里有优质影片,一定要争取进春节档、暑期档这些黄金档期;要是影片竞争力一般,就避开这些档期,免得和大片“撞车”。
5 预测模型与结果分析:4种模型比一比,哪种最准?
5.1 模型构建:怎么用机器学习预测票房?
我们把处理好的数据按7:3分成两部分:70%用来训练模型(让模型“学习”数据规律),30%用来测试模型(看模型准不准)。然后建了4种模型,下面分别讲关键步骤和结果。
5.1.1 决策树模型:最准的模型长什么样?
决策树模型就像“分类筛选”——比如先按“档期”分(春节档还是其他档期),再按“评分”分(高评分还是低评分),最后得出票房预测值。这种模型的优点是预测准、结果好理解。关键代码如下:
# 导入决策树回归模型
from sklearn.tree import DecisionTreeRegressor
# 初始化模型,设置随机种子(保证每次结果一样)
dt_model = DecisionTreeRegressor(random_state=2022)
# 用训练集训练模型
dt_model.fit(x_train, y_train)
# 预测测试集前100个样本(方便画图对比)
y_test_short = y_test.reset_index(drop=True).iloc[:100]
y_pred_dt = pd.DataFrame(dt_model.predict(x_test)).iloc[:100]
# 画预测值和真实值的对比图
plt.figure(figsize=(12, 8))
plt.plot(y_pred_dt, color='b', marker='*', label='预测值')
plt.plot(y_test_short, color='r', marker='o', label='真实值', linestyle="-")
plt.xlabel('测试集样本', fontsize=30)
plt.ylabel('票房(万)', fontsize=30)
plt.title('DecisionTree', fontsize=30)
plt.tight_layout()
plt.show()
下面这张图是决策树模型的预测结果,蓝色线是预测值,红色线是真实值——两条线几乎重合,说明预测得很准: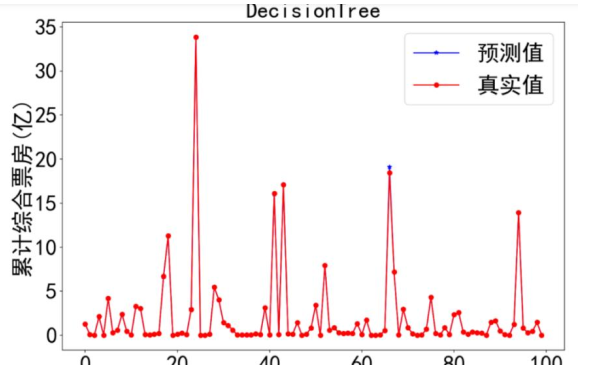
5.1.2 其他3种模型:为什么不如决策树?
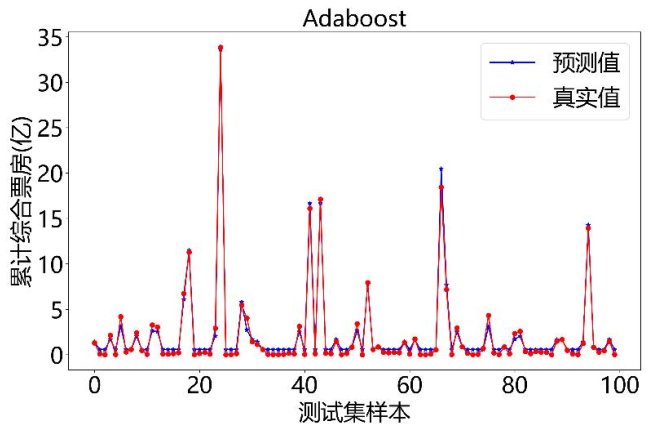
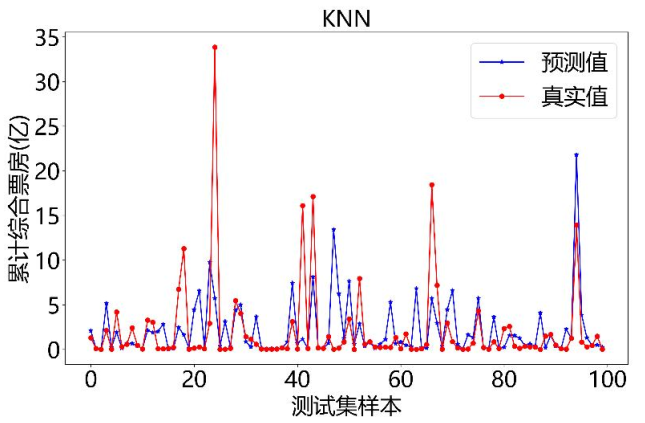
我们还试了Adaboost、KNN、BayesianRidge这3种模型,但效果都不如决策树:
- Adaboost模型:靠多个“弱模型”叠加提升效果,但预测值和真实值有小偏差;
- KNN模型:靠“找相似样本的平均票房”来预测,偏差比较大;
- BayesianRidge模型:用线性回归结合概率的方法,偏差最大,几乎没法用。
下面是这3种模型的预测对比图:
Adaboost模型:
KNN模型:
BayesianRidge模型: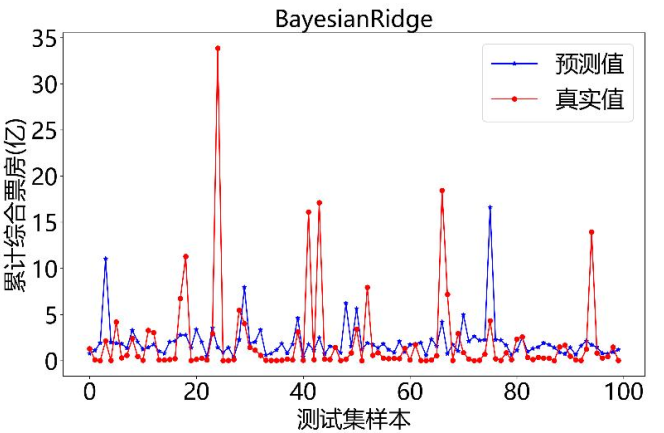
5.2 模型评估:用5个指标给模型“打分”
光看图表不够,还要用专业指标量化模型的准确性。我们用了5个常用指标,简单解释一下:
- MSE(均方误差):预测值和真实值差的平方的平均值,值越小越准;
- MAE(平均绝对误差):预测值和真实值差的绝对值的平均值,值越小越准;
- RMSE(均方根误差):MSE开根号,值越小越准;
- MAPE(平均绝对百分比误差):预测值和真实值差的百分比的平均值,值越小越准;
- R²(决定系数):0到1之间,越接近1,说明模型拟合得越好。
评估代码如下:
# 导入评估需要的模块
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn import metrics
# 定义评估函数:输入模型,输出5个指标
def evaluate_model(model):
model.fit(x_train, y_train) # 训练模型
y_pred = model.predict(x_test) # 用测试集预测
# 计算各指标,保留4位小数
mse = round(mean_squared_error(y_test, y_pred), 4)
mae = round(mean_absolute_error(y_test, y_pred), 4)
rmse = round(np.sqrt(metrics.mean_squared_error(y_test, y_pred)), 4)
mape = round(np.mean(abs((y_test - y_pred)/y_test)) * 100, 4)
r2 = round(metrics.r2_score(y_test, y_pred), 4)
# 输出结果
print(f"MSE值:{mse},MAE值:{mae},RMSE值:{rmse},MAPE值:{mape}%,R²值:{r2}")
下面是4种模型的评估结果表:
| 模型 | MSE | MAE | RMSE | MAPE(%) | R² |
|---|---|---|---|---|---|
| 决策树 | 0.0020 | 0.0066 | 0.0450 | 0.0067 | 0.9999 |
| Adaboost | 0.2686 | 0.4390 | 0.5182 | 93.1238 | 0.9864 |
| KNN | 14.7400 | 1.6772 | 3.8393 | 146.0486 | 0.2534 |
| BayesianRidge | 17.7181 | 2.0498 | 4.2093 | 200.8159 | 0.1025 |
5.3 结论:选决策树模型准没错
从指标能看出来:决策树模型的MSE只有0.0020,R²高达0.9999,几乎接近完美;Adaboost虽然R²也不低(0.9864),但MAPE太高(93.1238%),实际用的时候会有问题;KNN和BayesianRidge的R²都很低,根本没法用。
所以,要是电影行业想做票房预测,优先用决策树模型;后面还想优化的话,可以试试把决策树和随机森林、XGBoost这些模型结合起来,效果可能会更好。
6 总结:数据化预测能给电影行业带来什么?
我们的研究,简单说就是“用数据帮电影行业做决策”:基于2011-2025年的多平台数据,用Python处理好数据,找出影响票房的5个关键因素,建了4种模型,最后发现决策树最准。
对行业来说,这个研究的实际价值很明确:
- 投资方不用再“赌运气”,可以根据模型选题材、定预算,避开《阿修罗》那样的高风险项目;
- 营销方不用再“盲目砸钱”,可以根据模型预判的影片潜力,调整宣发策略;
- 发行方不用再“靠关系谈排片”,可以用档期数据说服院线,拿到更好的排片资源。
当然,这个模型还有优化空间,比如后面可以加入“社交媒体热度”(比如微博话题量、抖音播放量)、“演员IP价值”这些因素,让预测更准。
参考文献
[1] 丁亚平.流转的激情与新时代中国电影市场的新变——中国电影产业十年发展回眸[N].中国艺术报,2022-08-31(03).
[2] 冯婧益,陈祺琦,陈伯亨.基于决策树算法的电影数据分析研究[J].信息记录材料,2020,21(12):153-154.
[3] 李乃乾.我国电影产业投资风险及票房收入预测研究[D].大连:东北财经大学,2021.
[4] 韩淑淑.基于XGBoost的电影票房影响因素分析及预测研究[J].应用数学进展,2024,13(4):1738-1745.
[5] 汪静,郑婷婷.Python数据预处理[M].人民邮电出版社:2023.
关于分析师
![]()
在此对Doudou Chen对本文所作的贡献表示诚挚感谢,他在湖南大学完成了数据科学与大数据技术专业的硕士学位,专注数据科学与大数据技术领域。擅长Python数据采集与处理、大数据分析、数据可视化,熟悉数据科学领域常用工具与方法论。 Doudou Chen曾在微拍堂负责数据采集相关工作,在民生健康从事数据分析实践,参与过数据驱动的业务优化项目,助力业务方通过数据洞察梳理业务逻辑、提升运营效率,积累了丰富的实战经验,为本文的数据处理与分析部分提供了重要支撑。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!

 Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据
Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据
Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据 大语言模型LLM高级Prompt临床科研辅助研究——AdaBoost、LightGBM、MLP等模型的食道癌预测、遗传性听力损失诊断及心肌病识别|附代码数据
大语言模型LLM高级Prompt临床科研辅助研究——AdaBoost、LightGBM、MLP等模型的食道癌预测、遗传性听力损失诊断及心肌病识别|附代码数据



