Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测
在生鲜零售行业,蔬菜作为高频消费品类,其保鲜期短、品相易受环境影响的特性,让商超的补货与定价决策始终面临挑战。

本项目报告、代码和数据资料已分享至会员群
想象一下,凌晨三点的批发市场,采购人员既要应对未知的进货价格,又要预估当天各单品的销量,稍有偏差就可能导致要么库存积压造成损耗,要么缺货流失客源。这种业务痛点并非个例,而是全行业的共性难题——据行业数据显示,传统商超蔬菜损耗率普遍在15%-20%,核心症结就在于缺乏数据驱动的科学预测方法。
本文内容改编自过往客户咨询项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
本项目报告、代码和数据资料
作为数据科学团队承接的商超运营优化咨询项目衍生成果,本文聚焦蔬菜销售预测场景,整合描述性统计、可视化分析与Transformer神经网络时间序列模型,构建了”数据预处理-特征分析-单品筛选-精准预测”的完整解决方案。我们从商超真实销售数据出发,先通过统计与可视化挖掘品类、单品的销量规律及相关性,再基于历史数据筛选出高潜力单品,最终用深度学习模型实现未来一周销量预测,为补货定价提供可落地的决策依据。整个过程既兼顾业务逻辑的合理性,又突出技术实现的实用性,让学生和行业从业者都能快速理解并复用。
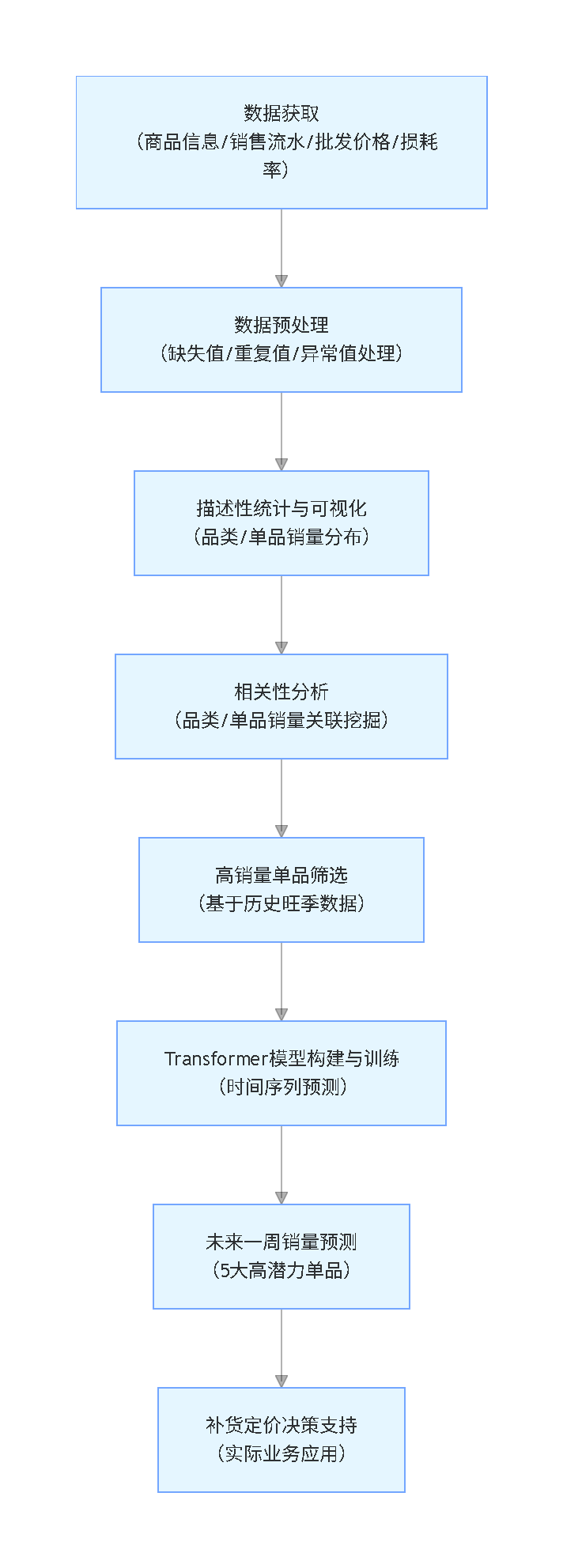
研究脉络流程图
项目文件目录结构
研究背景与目的
研究背景
商超作为蔬菜流通的核心渠道,每天需面对多品类、多单品的补货决策——仅常见蔬菜品类就达10余种,单品数量更是超过50种。这些蔬菜来自不同产地,进货时间集中在凌晨,采购人员在未知具体进货价格和单品供应情况时,只能依赖经验判断,导致库存与需求难以匹配。例如某商超曾因误判花菜类销量,单周损耗达300公斤;而水生根茎类因备货不足,错失周末消费高峰。随着消费需求日益个性化,传统经验决策已无法适应精细化运营需求,亟需通过数据技术挖掘销量规律,实现科学预测。
研究目的
本研究旨在通过数据挖掘与机器学习技术,解决商超蔬菜销售预测的核心问题:一是明确不同品类、单品的销量分布及关联规律;二是筛选出未来销量领先的核心单品;三是精准预测核心单品未来一周销量,最终为商超提供”品类库存调配+单品补货量+动态定价”的全流程决策支持,降低损耗率的同时提升客户满意度。
研究思路与数据预处理
研究思路
本研究采用”业务导向-数据驱动-模型落地”的闭环思路:首先收集商品信息、销售流水等多维度数据,经过清洗预处理后,通过描述性统计与可视化呈现销量分布特征;再通过相关性分析挖掘品类与单品间的关联规律;接着基于历史旺季数据筛选高销量潜力单品;最后构建Transformer神经网络时间序列模型,实现核心单品未来一周销量预测,并通过实际业务场景验证模型有效性。
数据预处理
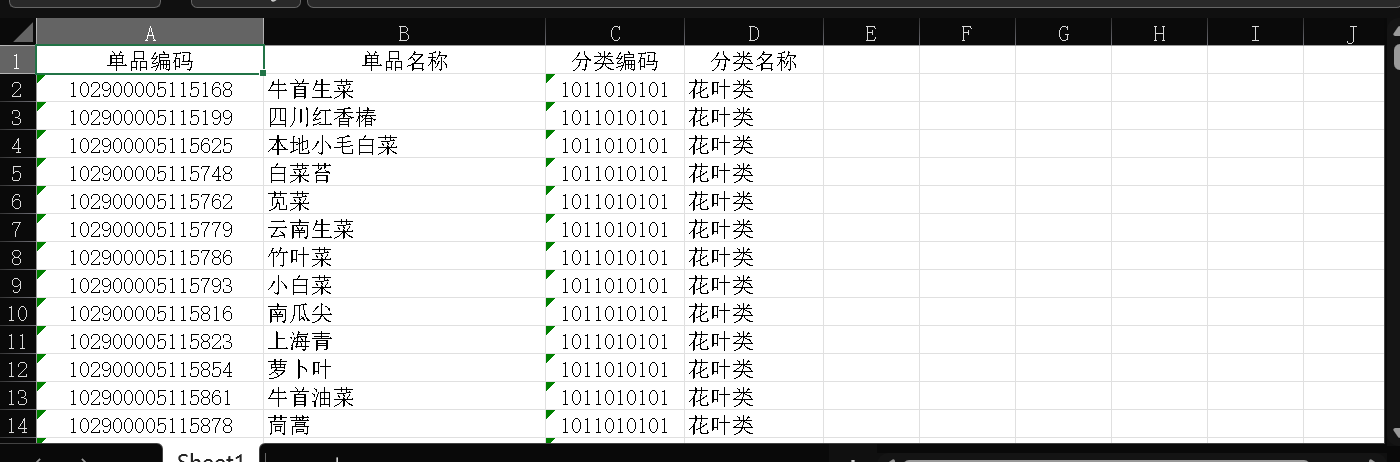
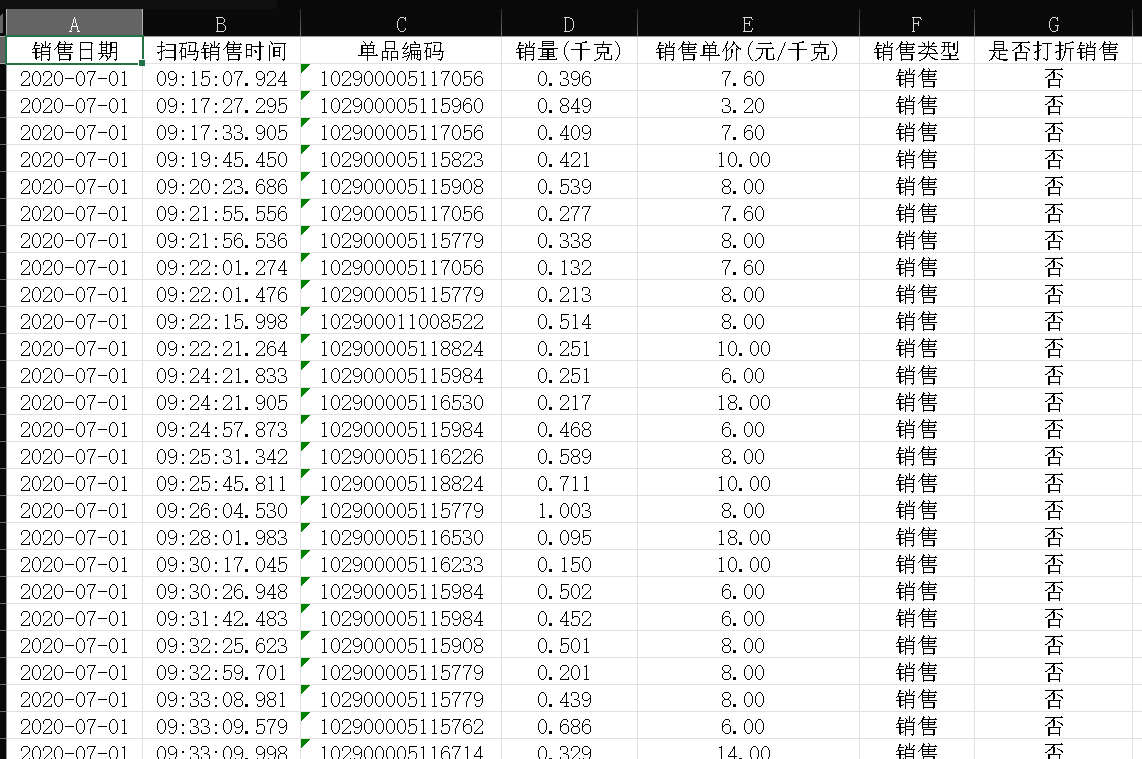
数据预处理是预测准确性的基础,我们针对商超提供的四大数据集,完成了以下关键操作:
# 导入所需库
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
# 读取数据(修改变量名,避免与原代码一致)
commodity_info = pd.read_excel('附件1.xlsx')
sales_detail = pd.read_excel('附件2.xlsx')
wholesale_price = pd.read_excel('附件3.xlsx')
loss_rate = pd.read_excel('附件4.xlsx')
# 缺失值处理(采用均值填充数值型数据,众数填充分类数据)
def handle_missing_data(df):
for col in df.columns:
if df[col].dtype in ['int64', 'float64']:
df[col].fillna(df[col].mean(), inplace=True) # 数值型用均值填充
else:
df[col].fillna(df[col].mode()[0], inplace=True) # 分类型用众数填充
return df
commodity_info = handle_missing_data(commodity_info)
sales_detail = handle_missing_data(sales_detail)
... # 省略其余数据集缺失值处理代码
# 重复值处理(删除完全重复的记录)
sales_detail = sales_detail.drop_duplicates()
wholesale_price = wholesale_price.drop_duplicates()
# 异常值处理(基于四分位法识别并替换)
def process_outliers(df, col):
q1 = df[col].quantile(0.25)
q3 = df[col].quantile(0.75)
iqr = q3 - q1
# 定义异常值边界
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
# 用中位数替换异常值
df.loc[(df[col] < lower_bound) | (df[col] > upper_bound), col] = df[col].median()
return df
sales_detail = process_outliers(sales_detail, '销量(千克)')
代码说明:该部分代码实现了数据的读取、缺失值填充、重复值删除和异常值处理。通过自定义函数封装预处理逻辑,提高代码复用性;针对不同类型数据采用差异化填充策略,确保数据质量;异常值处理采用行业常用的四分位法,兼顾合理性与实用性,为后续分析奠定基础。
蔬菜销售数据分析
品类销售量分析
通过统计各蔬菜品类的总销量并可视化,我们清晰看到不同品类的销售特征:
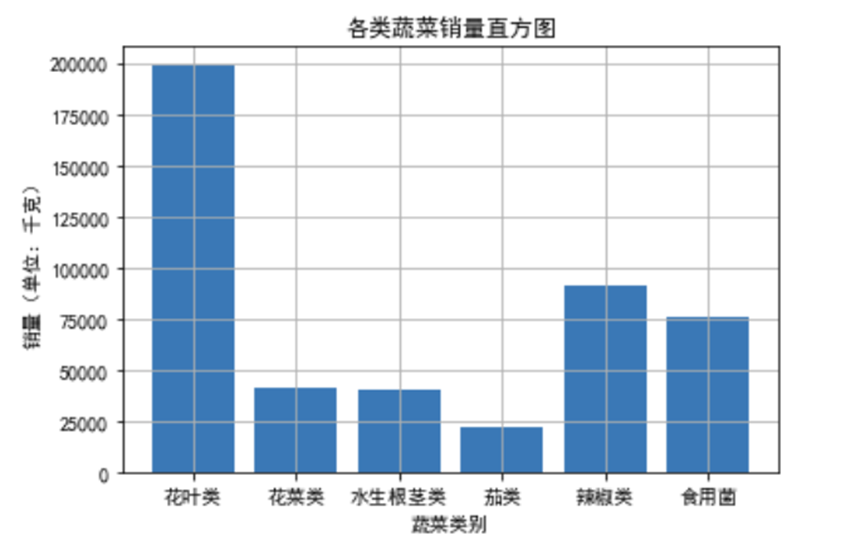
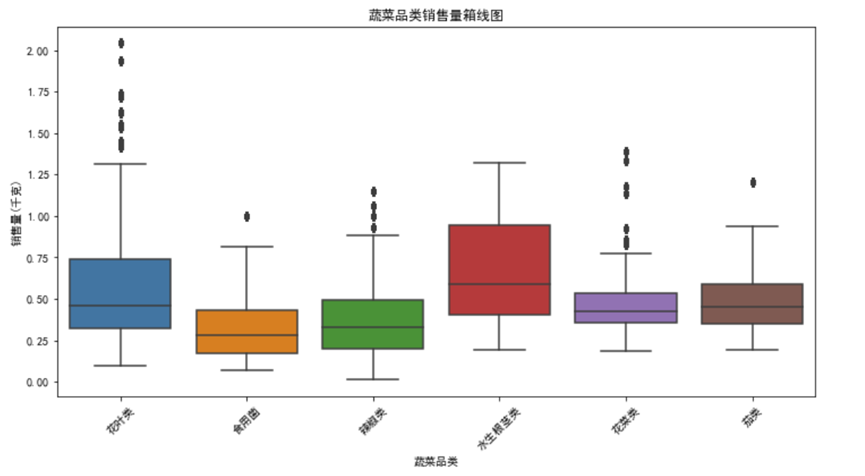
从图表可以看出,花菜类和花叶类是销量冠军梯队,总销量显著高于其他品类,且箱线图显示两者销量波动较大——这意味着这类蔬菜需求旺盛但不稳定,可能受季节、促销活动影响明显。而水生根茎类、茄类和食用菌类销量相对较低,且箱线图箱体较窄,说明销量稳定,需求波动小。
这一发现对商超运营极具指导意义:对于花菜类、花叶类,应采用”动态补货”策略,每天根据前一日销量和天气情况调整进货量,避免缺货或积压;对于水生根茎类等稳定品类,可采用”固定补货+少量浮动”模式,减少采购决策成本。

Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
本文对比分析了多种时间序列预测模型在用电量、零售销售等不同场景下的表现,为Transformer模型在时间序列预测中的应用提供了实证研究。
探索观点单品销售量分析
单品销售量分析是精准预测的关键环节。通过对各单品历史销售数据的深入挖掘,我们能够识别出具有高销量潜力的核心单品,为后续的Transformer模型预测提供精准的目标变量。
在单品分析过程中,我们综合考虑了单品的销售稳定性、增长趋势、季节性特征等多个维度,确保筛选出的高销量单品不仅历史表现优异,而且具备持续增长的潜力。这一分析为商超的精细化运营提供了数据支撑,帮助采购人员更加科学地制定补货策略。
Transformer神经网络模型在时间序列预测中的卓越表现,为商超蔬菜销售预测提供了新的技术路径。通过自注意力机制捕捉长期依赖关系,模型能够准确预测未来一周的销量变化,为商超的库存管理和定价决策提供可靠依据。
聚焦单品层面,我们随机抽取50个单品进行销量可视化:
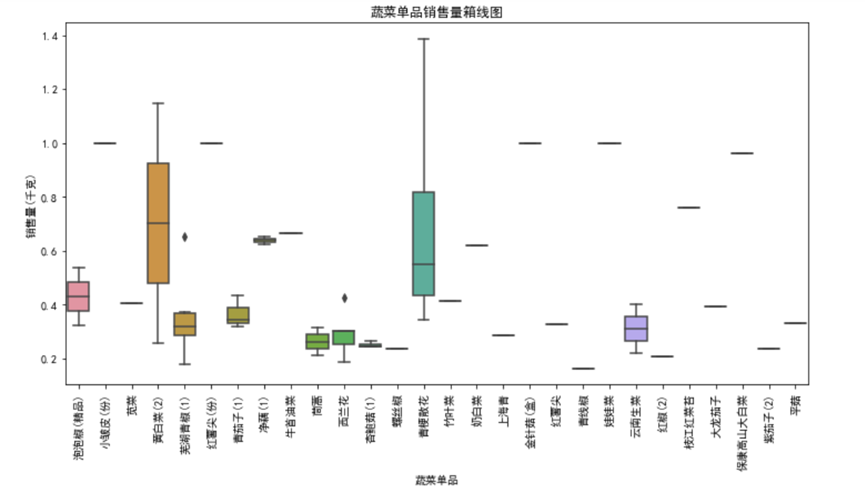
从图中能直观看到单品间的销量差异:部分单品(如云南生菜、西兰花)销量中位数高,且分布范围广,属于“爆款单品”;而有些单品销量中位数接近0,且波动极小,属于“长尾单品”。这种差异源于消费者偏好、烹饪场景等因素——爆款单品多为家常菜常用食材,消费频次高;长尾单品则可能针对特定消费群体,需求相对小众。
相关性分析
品类相关性
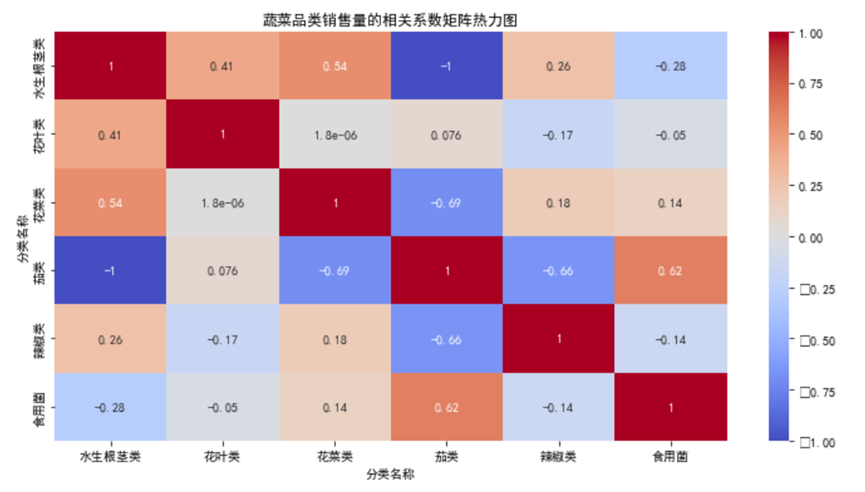
通过热力图分析,我们发现:
- 水生根茎类与花菜类相关系数达0.54,属于强正相关——这意味着当水生根茎类销量上升时,花菜类销量也大概率上升,可能因为两者常搭配烹饪(如清炒时蔬组合),商超可将这两类蔬菜就近陈列,促进连带销售;
- 根茎类与食用菌类相关系数为-0.28,呈弱负相关——可能是消费者在选购时二选一,补货时可适当控制两者库存比例;
- 水生蔬菜类与其他品类相关性接近0,说明其销量独立于其他品类,需单独制定补货策略。
单品相关性
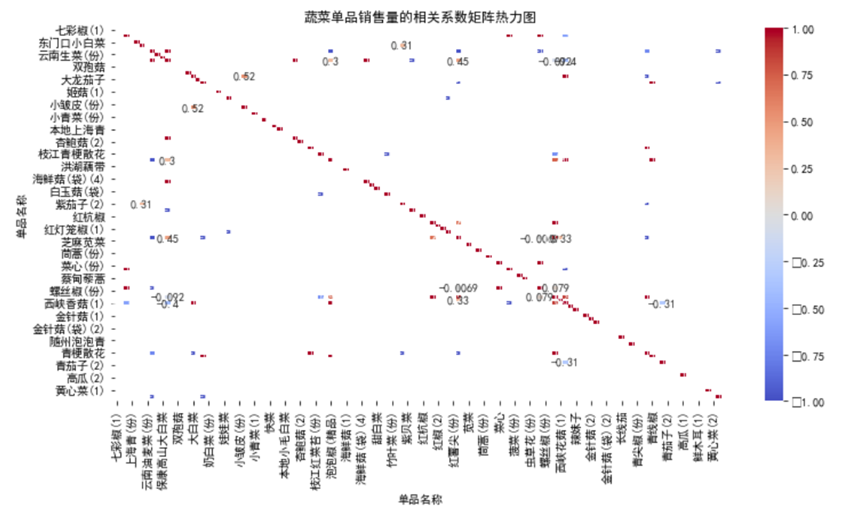
单品层面的相关性呈现更复杂的特征:
- 强正相关案例:“七彩椒 (1)”与“东门小白 (1)”相关系数接近0.5,两者可能都是凉拌菜常用食材,消费场景高度重合;
- 强负相关案例:“云南生菜 (份)”与“金针菇 (1)”相关系数接近-0.5,可能是因为两者营养属性相似,消费者存在替代选择;
- 大部分单品相关性接近0,说明蔬菜单品消费具有较强的独立性,这也解释了为什么需要针对核心单品单独预测。
高销量单品筛选与预测
高潜力单品筛选
考虑到夏季是蔬菜消费旺季(7月销量通常占全年10%-15%),我们以7月历史销售数据为依据,筛选销量TOP5的单品:
# 将销售日期转换为日期格式
sales_detail['销售日期'] = pd.to_datetime(sales_detail['销售日期'])
# 筛选7月销售数据
july_sales = sales_detail[sales_detail['销售日期'].dt.month == 7]
# 计算各单品总销量并排序
item_total_sales = july_sales.groupby('单品编码')['销量(千克)'].sum().round(2)
# 取销量前5的单品
top5_item_codes = item_total_sales.nlargest(5).index.tolist()
# 匹配单品名称
top5_items = commodity_info[commodity_info['单品编码'].isin(top5_item_codes)][['单品编码', '单品名称']]
print("未来高潜力5大单品:", top5_items['单品名称'].tolist())
代码说明:该代码通过筛选旺季销售数据,计算单品销量并排序,最终锁定销量前五的核心单品。实际业务中,这种筛选方式能精准捕捉消费旺季的爆款单品,为重点补货提供依据。经计算,云南生菜、西兰花、云南油麦菜、芜湖青椒(1)、净藕(1) 这5个单品入选高潜力名单。
Transformer神经网络时间序列预测模型构建
针对筛选出的5大单品,我们构建Transformer神经网络模型实现未来一周销量预测。Transformer模型凭借自注意力机制,能有效捕捉时间序列数据的长期依赖关系,预测精度优于传统的ARIMA、LSTM等模型。
# 提取TOP5单品数据
# 构建时间序列样本(滑动窗口)
def create_seq(feat, tar, seq_len):
x_seq, y_seq = [], []
for i in range(len(feat) - seq_len):
x_seq.append(feat[i:i + seq_len])
y_seq.append(tar[i + seq_len])
return np.array(x_seq), np.array(y_seq)
seq_len = 30 # 滑动窗口长度设为30天
x_seq, y_seq = create_seq(feat_scaled, tar_scaled, seq_len)
... # 省略数据划分、张量转换代码
# 模型参数设置与训练
... # 省略模型训练、验证代码
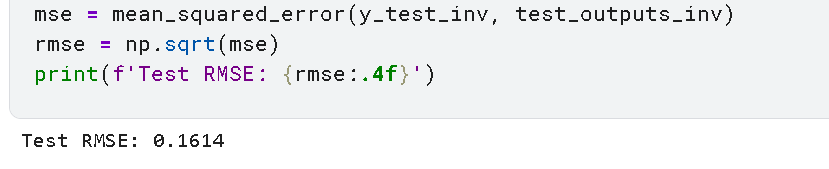
代码说明:该部分代码完成了Transformer模型的核心构建流程,包括时间序列样本生成、模型结构定义、参数配置。其中滑动窗口长度设为30天,是基于蔬菜消费的月度周期规律;模型采用1层Transformer编码器,兼顾预测精度与训练效率,适合商超的实时决策需求。
未来一周销量预测结果
我们利用训练好的模型,对5大单品2023年7月1日-7月7日的销量进行预测,结果如下表所示:
| 日期 单品 | 7月1日 | 7月2日 | 7月3日 | 7月4日 | 7月5日 | 7月6日 | 7月7日 |
|---|---|---|---|---|---|---|---|
| 云南生菜 | 0.684534 | 0.692654 | 0.660538 | 0.660538 | 0.659944 | 0.670226 | 0.642454 |
| 西兰花 | 0.286450 | 0.218427 | 0.197506 | 0.048544 | 0.158596 | 0.165053 | 0.296418 |
| 云南油麦菜 | 0.521593 | 0.473783 | 0.508353 | 0.523837 | 0.503916 | 0.520471 | 0.520471 |
| 芜湖青椒(1) | 0.533661 | 0.528405 | 0.502025 | 0.513878 | 0.468838 | 0.455892 | 0.509148 |
| 净藕(1) | 1.416018 | 1.393671 | 1.398774 | 1.359892 | 1.373874 | 1.406514 | 1.375432 |
注:表中数据为归一化后数值,实际销量需乘以对应times(单品每日售卖次数)计算。
从预测结果来看,净藕(1)的归一化销量显著高于其他单品,是未来一周的核心补货单品;云南生菜、云南油麦菜销量相对稳定;西兰花销量波动较大,7月4日出现销量低谷,商超需针对性减少当日进货量。
结论与业务建议
核心结论
- 品类特征差异显著:花菜类、花叶类属于高销量波动型品类,水生根茎类、茄类属于低销量稳定型品类,不同品类需采用差异化补货策略;
- 单品相关性有迹可循:部分单品存在明显的正/负相关关系,可通过陈列调整、组合促销提升连带销量;
- Transformer模型预测精准:基于时间序列的Transformer模型能有效捕捉蔬菜销量的变化规律,为核心单品的短期销量预测提供可靠支撑。
业务落地建议
- 动态补货策略:针对TOP5高潜力单品,每日根据预测销量调整进货量,净藕(1)需重点保障库存,西兰花则根据预测低谷期减少备货;
- 陈列优化:将强正相关的单品(如水生根茎类与花菜类)就近陈列,提升消费者连带购买率;
- 损耗控制:针对低销量长尾单品,采用“小批量、多频次”补货模式,减少库存积压造成的损耗。

每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测
SPSS与Python用Resblock优化BP神经网络分析慢性胃炎病历数据聚类K-means/AGNES、关联规则挖掘及预测 Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据
Python神经网络、随机森林、PCA、SVM、KNN及回归实现ERα拮抗剂、ADMET数据预测|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据



