关联规则学习 在机器学习中用于发现变量之间的有趣关系。
Apriori算法是一种流行的关联规则挖掘和频繁项集提取算法,在关联规则学习中有应用。
它旨在对包含交易的数据库进行操作,例如商店客户的购买(购物篮分析)。除了购物篮分析之外,该算法还可以应用于其他问题。
什么是频繁项集
频繁项集是数据集中出现频率较高的项集。频繁项集挖掘的目的是发现一组交易中共同出现的有趣项目组合。
频繁项集挖掘基础知识
三个概念:市场、篮子、商品。
需要满足的假设条件:
a. 商品和篮子之间是多对多的关系。
b. 不考虑商品的数量。
c. 某件商品可能不出现在任何一个篮子里,但是任何篮子都包含至少一件商品。
d. 篮子中商品的顺序无关紧要。
有两个项目的项集称为2-项集或配对,有3个项目的项集称为3-项集(或者三元组),以此类推。
迈向关联规则
支持度
支持度表示项集出现的频率。最小支持阈值决定了频繁项集的评判标准。
2-项集的支持度通常用概率表示:
support(X->Y) = P(XuY)
置信度
confidence(X->Y) = P(X|Y) = support(XuY) / support(X)
关联规则
从支持度和置信度,可以建立频繁项集中项目之间的关联规则。例如:香草威化->香蕉,奶油。[支持度=1%, 置信度=40%]。规则可以读作:在所有篮子中,有1%包含香草威化、香蕉和生奶油的组合;在购买香草威化的客户中,有40%同时购买了香蕉和生奶油。
规则左侧是先导,右侧是后继。
包含数据的示例
附加值——修复计划中的漏洞
避免有些商品自身的表现好于作为关联规则后继时的表现。通过附加值考虑其关联的合理性。
附加值 = 规则置信度 – 右侧的支持度
如果附加值是大的正数,那么规则是好的、有用的。如果附加值接近于0,则这条规则可能是正确的,但是没太大用处。如果附加值是大的负数,那么规则中的商品实际上是负相关的,这时单独使用表现会更好。
寻找频繁项集的方法
快速寻找频繁项集的一条重要原则:向上闭包属性。向上闭包指的是,只有在项集的所有项目都频繁出现时,该项集才是频繁项集。
Apriori算法:
a. 设置一个支持阈值
b. 构建一个1-项集列表,根据支持度得到SingletonList列表
c. 从SingletonList中选择项集构建DoubletonList
d. 从DoubletonList中选择项集构建TripletionList。
e. 重复d步,从前面构建的列表中的单项生成n-项集,直到频繁集用完。
例如,在网络用户导航领域,我们可以搜索诸如访问过网页A和网页B的客户也访问过网页C的规则。
Python sklearn 库没有 Apriori 算法,其中 Python 库 MLxtend 用于市场篮子分析。在这篇文章中,我将分享如何使用Python 获取关联规则和绘制图表,为数据挖掘中的关联规则创建数据可视化 。首先我们需要得到关联规则。
从数组数据中获取关联规则
要获取关联规则,您可以运行以下代码
import pandas as pd oary = ott(daset).trafrm(dtset) df = pd(oh_ry, column=oht.cns) print (df)

frequent = apror(df, mn_upprt=0.6, useclaes=True) print (frequent )

数据挖掘中的置信度和支持度
为了选择有趣的规则,我们可以使用最知名的约束,即置信度和支持度的最小阈值 。
支持度是指项目集在数据集中出现的频率。
置信度表示规则被发现为真的频率。
suprt=rules(\['suport'\]) cofidece=rules(\['confience'\])
关联规则——散点图
建立散点图的python代码。由于这里有几个点有相同的值,我添加了小的随机值来显示所有的点。
for i in range (len(supprt)): suport\[i\] = suport\[i\] + 0.00 * (ranom.radint(,10)- 5) confidence\[i\] = confidence\[i\] + 0.0025 * (rao.rant(1,10) - 5) plt.show()
以下是支持度和置信度的散点图:
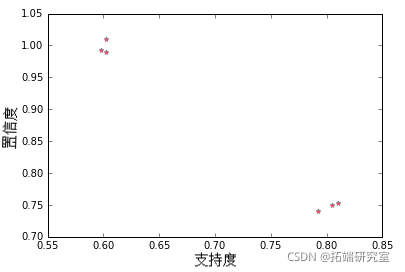

如何为数据挖掘中的关联规则创建数据可视化
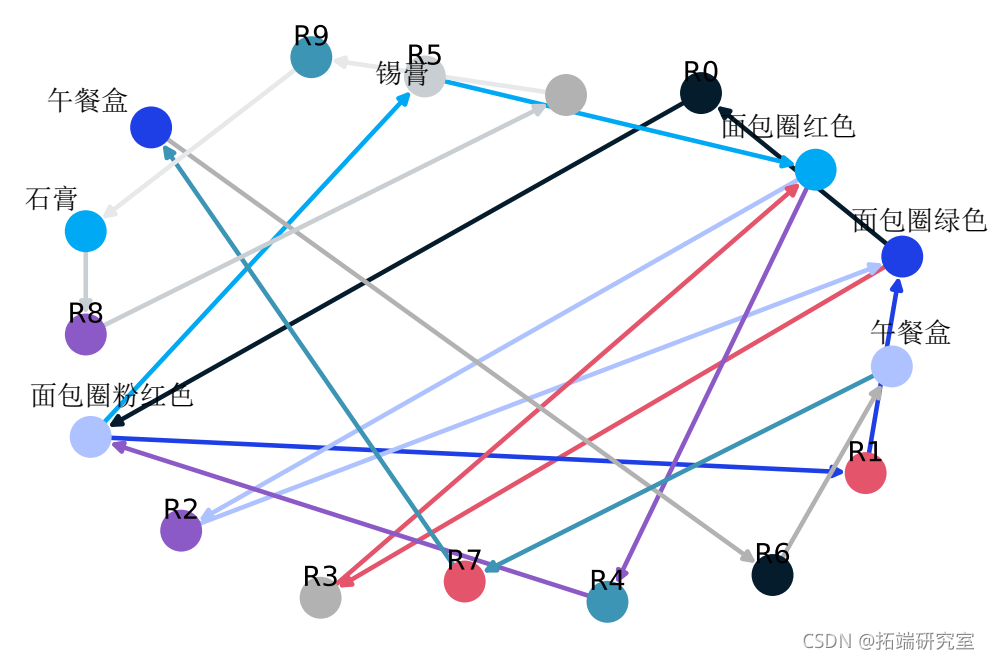
为了将关联规则表示为图。这是关联规则示例:(豆,洋葱)==>(鸡蛋)
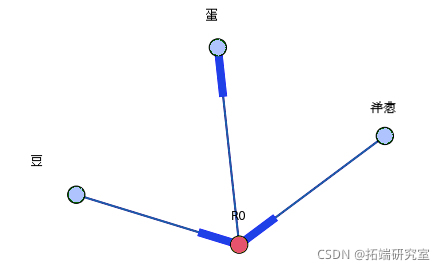
随时关注您喜欢的主题
下面的有向图是为此规则构建的,如下所示。具有 R0 的节点标识一个规则,并且它总是具有传入和传出边。传入边将代表规则前项,箭头在节点旁边。
下面是一个从实例数据集中提取的所有规则的图形例子。
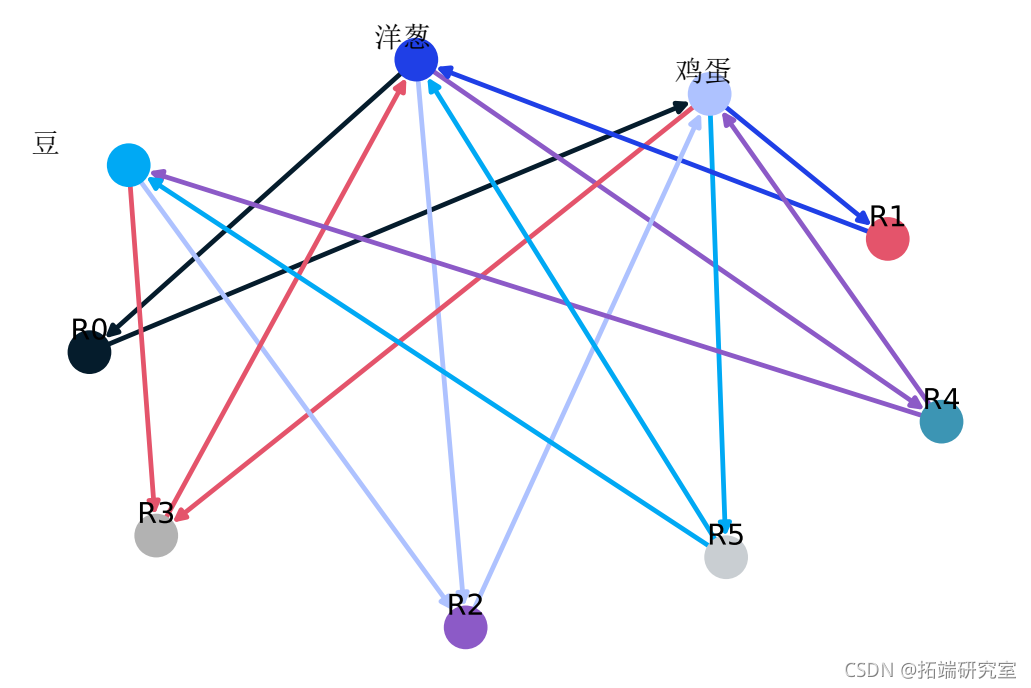
这是构建关联规则的源代码。
import networkx as nx
G1 = nx.iGaph()
colr_ap=\[\]
N = 50
colors = np.randm.rndN)
for i in range (rue\_o\_w):
G1.a\_od\_from(\["R"+st(i)\])
for a in rsloc\[i\]\['anedts'\]:
G1.dnoesrom(\[a\])
G1.adedg(a, "R"+str(i))
for c in ruleioc\[i\]\[''\]:
G1.addnodsom()
G1.adddge"R"str(i), c, colo=\[i\], weht=2)
for noe in G1:
fod_astring = alse
for iem in sts:
if nde==itm:
found\_a\_ring = True
if fond_sting:
cor_mp.apend('ellw')
else:
cor_mapapped('green')
plt.show()
在线零售数据集的数据可视化
为了对可视化进行真实感受和测试,我们可以采用可用的在线零售商店数据集并应用关联规则图的代码。
以下是支持度和置信度的散点图结果。这次使用seaborn库来构建散点图。下面是零售数据集关联规则(前 10 条规则)的可视化。
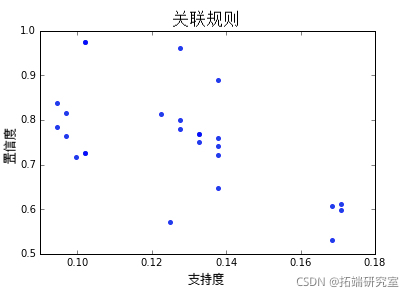
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载 2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载
2026年机器人产业:具身智能发展现状趋势报告:从春晚舞台到工厂车间|附80+份报告PDF、数据、可视化模板汇总下载 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据
Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据



