在数据科学的浩瀚宇宙中,我们如同孜孜不倦的探索者,不断追寻着更高效、精准的数据分析方法。从数据科学家的视角看,数据不仅是一串串数字,更是蕴含着巨大价值的宝藏,等待我们用合适的工具去挖掘。
近年来,非欧式空间数据大量涌现,传统神经网络在处理这类数据时力不从心。图神经网络(GNN)凭借其独特的设计,如邻居节点聚合、消息传递机制等,成为处理非欧式数据的有力武器,在社交网络、分子结构等诸多领域展现出巨大潜力。它能深入挖掘图中节点间的关联,捕捉数据内在结构特征,为我们理解复杂关系提供了新途径。
视频
图神经网络GNN:原理与应用
同时,主成分分析(PCA)及其衍生的核主成分分析(KPCA)在数据降维、特征提取等方面发挥着关键作用。在交通数据预测中,PCA 嵌入为时空图神经网络(ST – GNNs)注入新活力,有效解决了自适应嵌入的局限性,提升模型泛化能力与可迁移性,助力交通预测在复杂多变的城市环境中更精准地把握交通动态。而在汽油精制过程中,KPCA 能针对操作变量的非线性关系进行降维处理,结合多元线性回归模型,从众多影响因素中筛选出关键变量,为辛烷值损耗研究等化工领域问题提供了有效的分析手段。
这些技术并非孤立存在,而是相互交织,共同为数据分析与应用构建起坚实的技术体系。我们在实际项目中不断打磨、验证这些方法,正如您即将看到的,它们在解决各类实际问题时展现出强大的能力。本次专题项目文件已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长,让我们一起在数据科学的道路上携手前行,探索更多未知。
图神经网络GNN:原理与应用
摘要:本文深入探讨图神经网络(GNN)这一前沿技术,剖析其诞生背景、核心思想、网络结构、消息传递技术及数学原理,展示其在不同层级图任务中的应用。通过系统阐述,呈现GNN在处理非欧式空间数据方面的独特优势与广阔应用前景,为相关领域研究与实践提供理论与应用参考。
一、引言
在数字化时代,数据呈现出爆炸式增长,且形式愈发复杂多样。传统神经网络在处理规则的欧式空间数据(如图像、文本)时表现优异,然而面对现实世界中大量存在的非欧式数据,却显得力不从心。非欧式数据广泛存在于社交网络、分子结构、推荐系统、交通网络等场景,其结构的不规则性和复杂性,使得传统神经网络难以有效处理。在此背景下,图神经网络(Graph Neural Network,GNN)应运而生,成为解决非欧式数据处理难题的有力工具。


JiQuan Zhao
可下载资源
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测
视频
LSTM神经网络架构和原理及其在Python中的预测应用
视频
卷积神经网络CNN肿瘤图像识别
GNN的关键操作是消息传递。具体而言,就是先聚合邻居节点的信息,然后更新当前节点的表示,以此实现图结构数据的特征学习。以社交网络为例,若要分析某个用户的特征,GNN会收集该用户的好友(邻居节点)的相关信息,如兴趣爱好、行为习惯等,然后综合这些信息来更新对该用户的描述。这种消息传递机制能够充分挖掘图中节点之间的关联关系,捕捉数据的内在结构特征。

三、GNN网络的基本结构
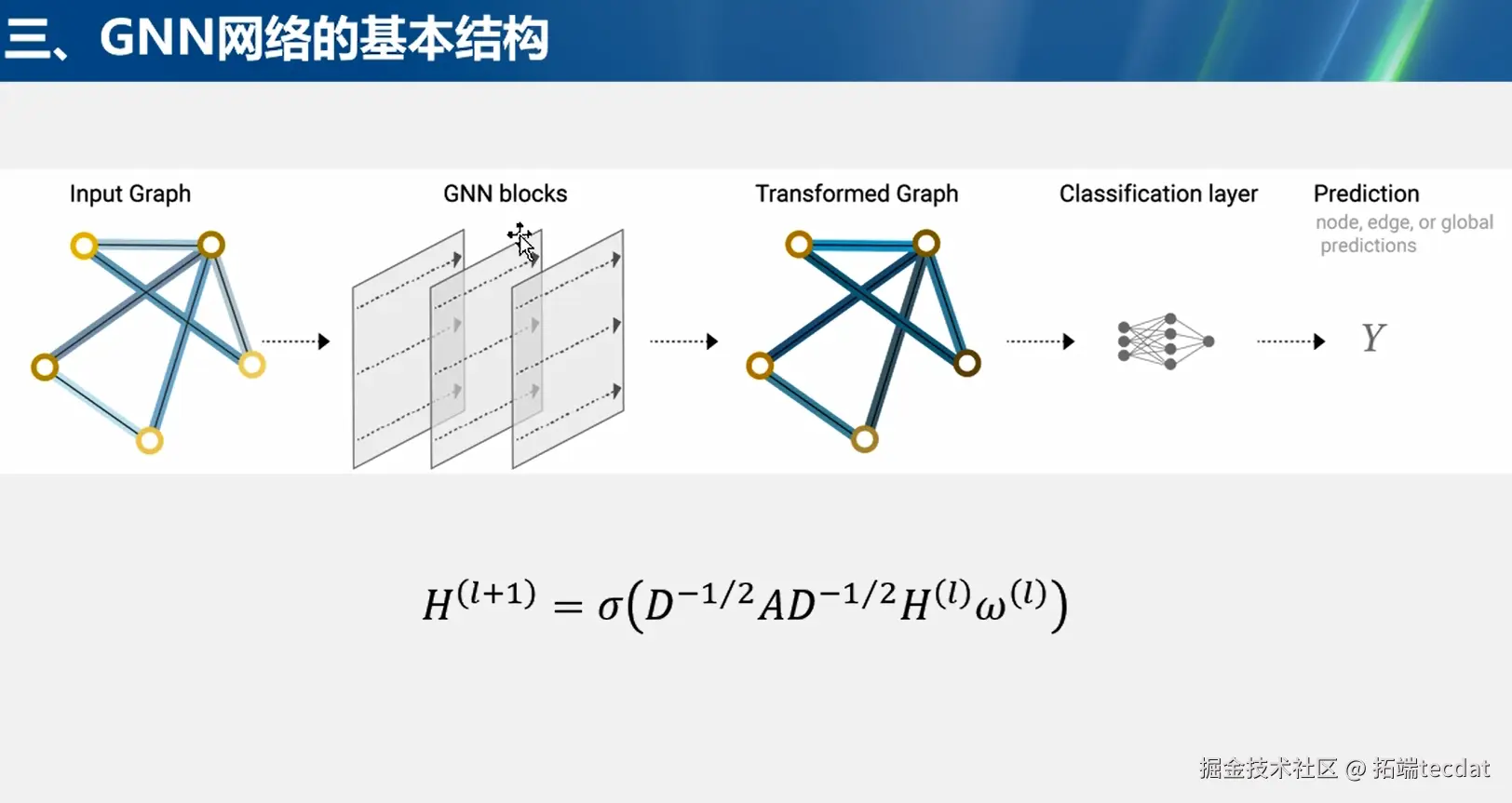
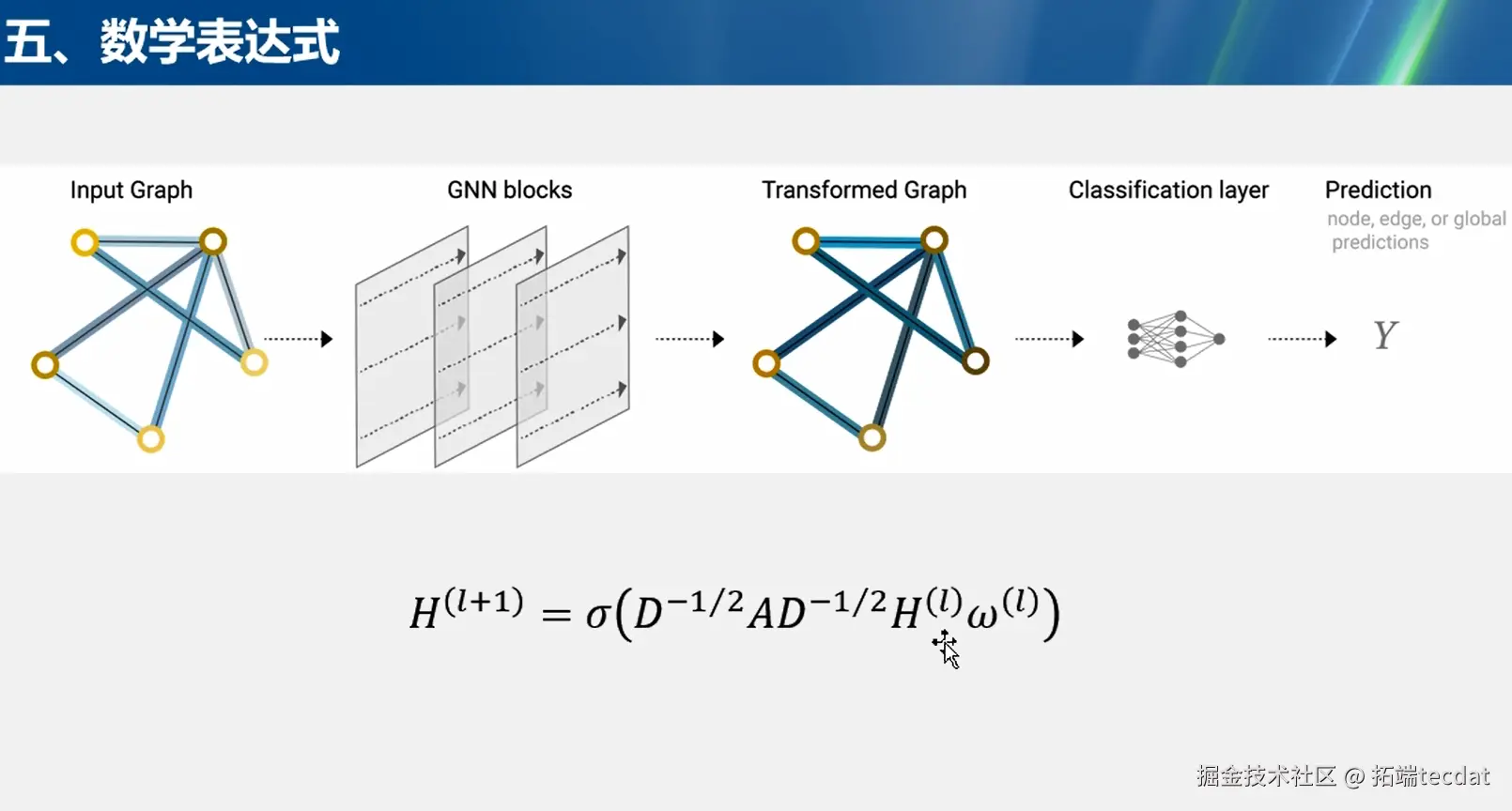
结构流程
GNN网络的基本结构包括输入图(Input Graph)、GNN模块(GNN blocks)、转换后的图(Transformed Graph)、分类层(Classification layer)和预测(Prediction)几个部分。输入图是原始的图结构数据,经过GNN模块的处理,对图的节点和边进行特征变换,得到转换后的图。然后,通过分类层对转换后的图进行分类或回归等操作,最终得到关于节点、边或整个图的预测结果。
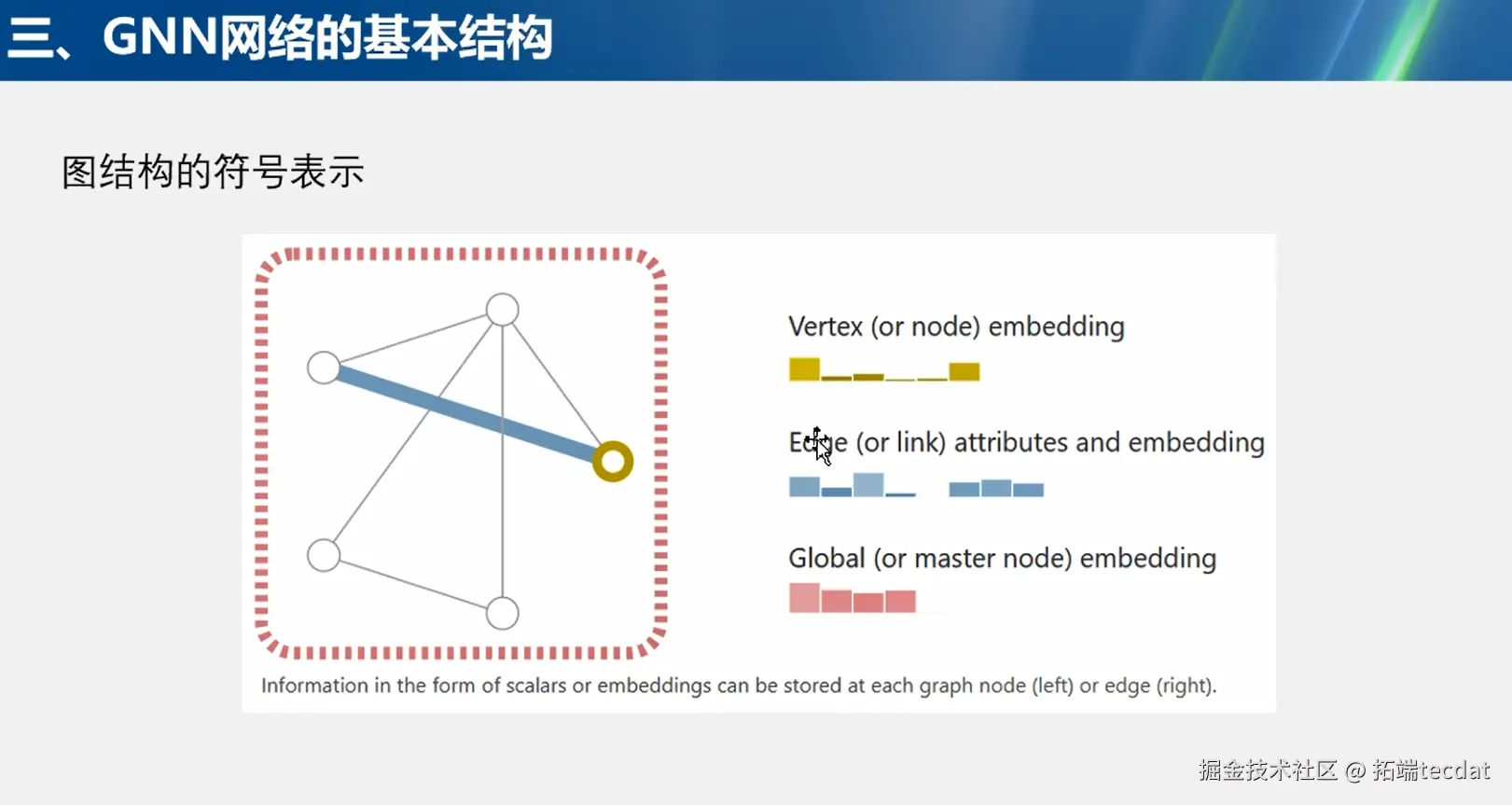
符号表示与公式
在图结构的符号表示中,涉及顶点(节点)嵌入(Vertex/node embedding)、边属性与嵌入(Edge/link attributes and embedding)、全局(主节点)嵌入(Global/master node embedding) 。数学公式H(l+1)=σ(D−1/2AD−1/2H(l)ω(l))H(l+1)=σ(D−1/2AD−1/2H(l)ω(l))用于描述GNN网络中节点表示的更新过程。其中,H(l)H(l)表示第ll层的节点特征矩阵,AA是图的邻接矩阵,描述节点之间的连接关系;DD是度矩阵,是对角矩阵,对角元素为节点的度;ω(l)ω(l)是可学习的权重矩阵;σσ是激活函数,用于引入非线性变换。通过这个公式,节点不断聚合邻居节点信息并更新自身表示,逐步学习到更具代表性的特征。

随时关注您喜欢的主题
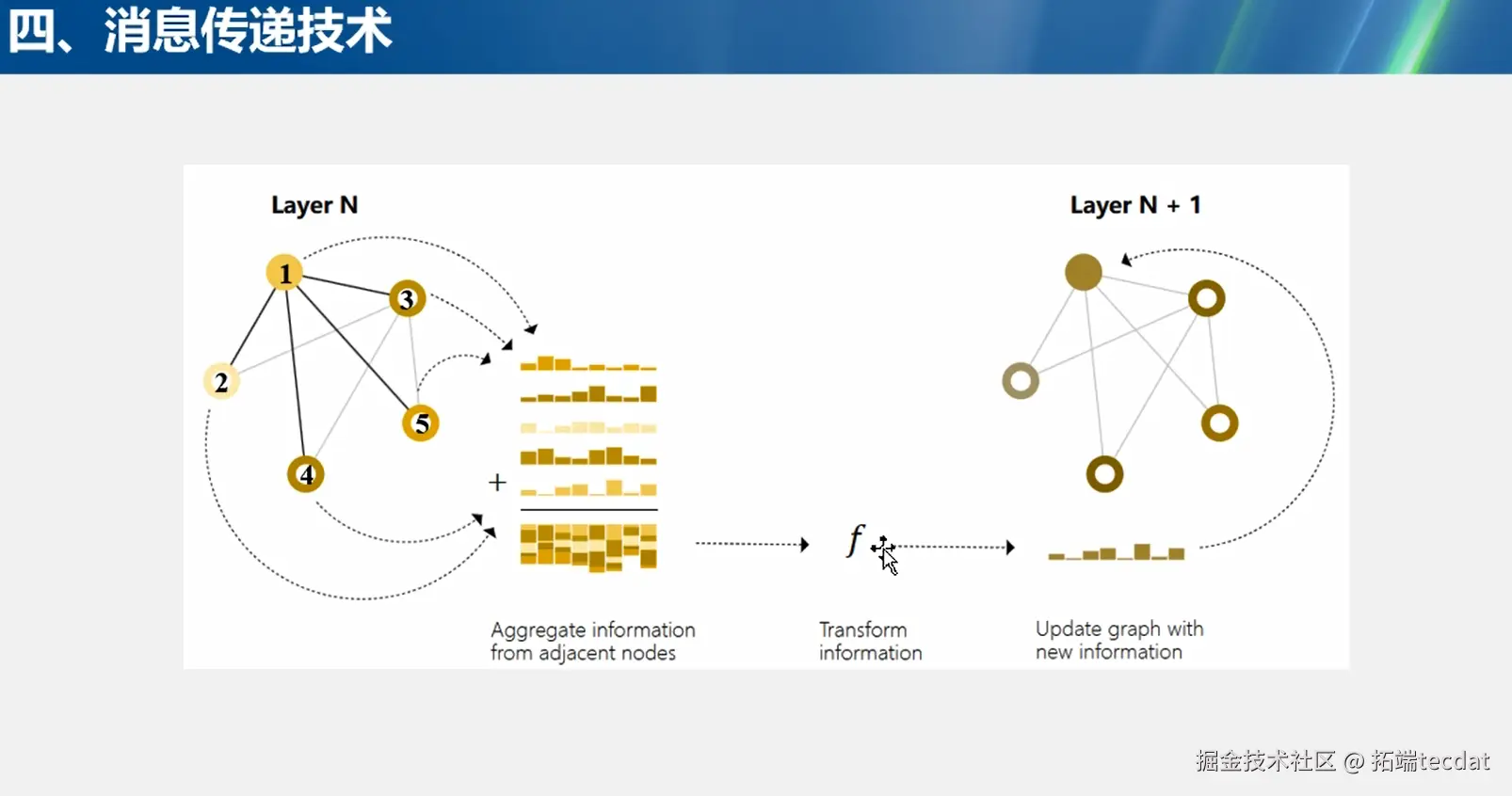
从消息传递技术的图示来看,在Layer N中,节点1、2、3、4、5之间存在连接关系,节点会从其邻居节点聚合信息,形成一个信息集合。经过函数ff的变换后,在Layer N + 1中,节点的表示得到更新,图的结构特征也随之改变。这种逐层的消息传递和节点更新,使得GNN能够深入挖掘图数据的复杂结构和内在联系。
五、数学表达式
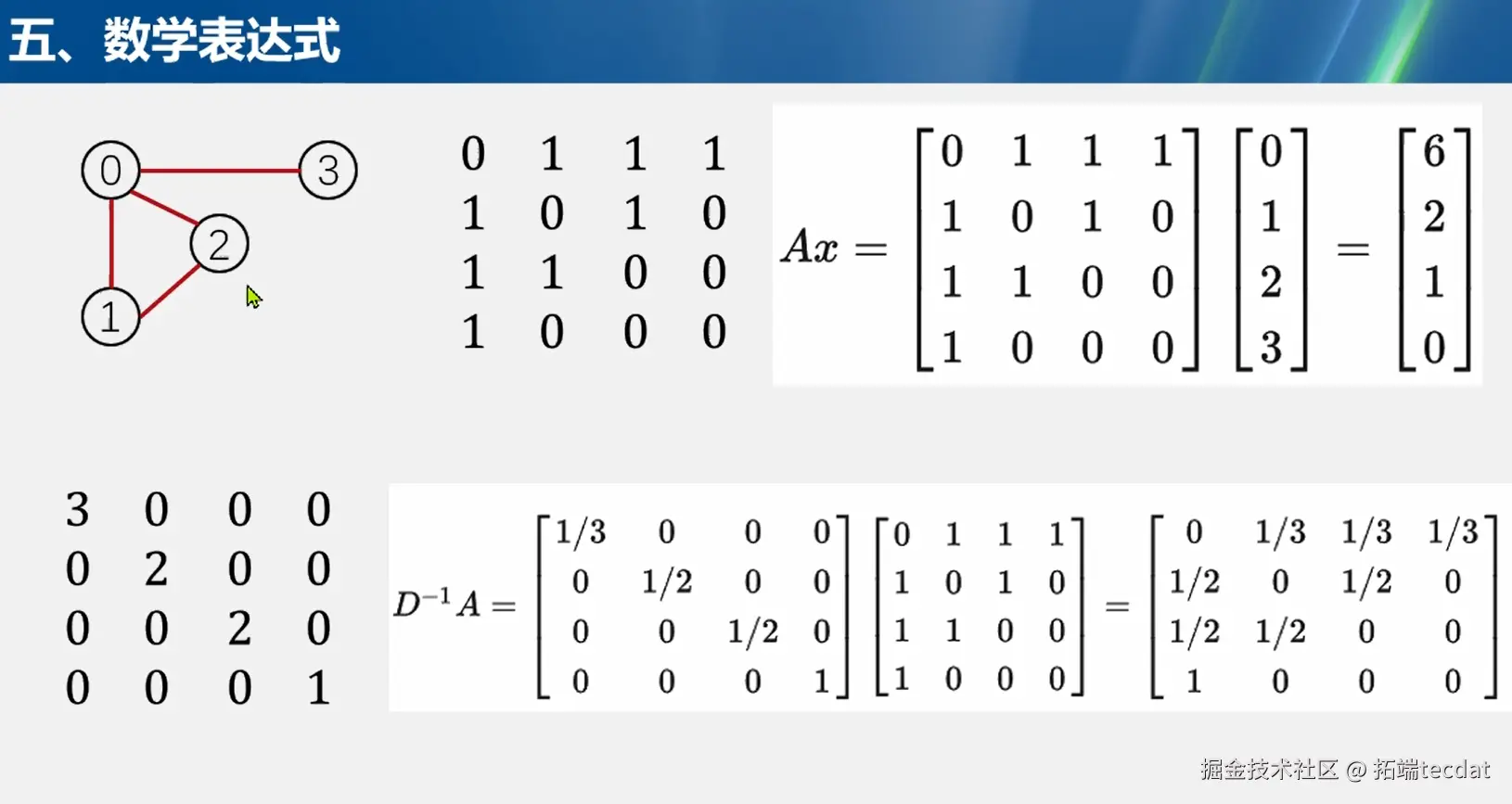
矩阵运算示例
以具体的矩阵运算为例,假设有图结构对应的邻接矩阵AA和向量xx ,通过矩阵乘法AxAx可以得到新的向量。例如在某个图结构中,邻接矩阵AA和向量xx相乘,计算结果反映了图中节点连接关系与节点特征的综合作用。另一个重要运算D−1AD−1A ,其中D−1D−1是度矩阵的逆矩阵,这个运算通过对邻接矩阵进行归一化处理,使得节点的信息传递更加合理,能够更好地平衡不同节点的影响力。
公式意义
这些数学表达式是GNN实现节点特征更新和图结构学习的数学基础。邻接矩阵AA记录了图中节点的连接情况,度矩阵DD反映了节点的连接强度,通过对它们的运算和组合,能够准确地描述图中节点之间的信息传递和相互作用,从而为GNN的消息传递和特征学习提供坚实的数学支撑。
六、图任务
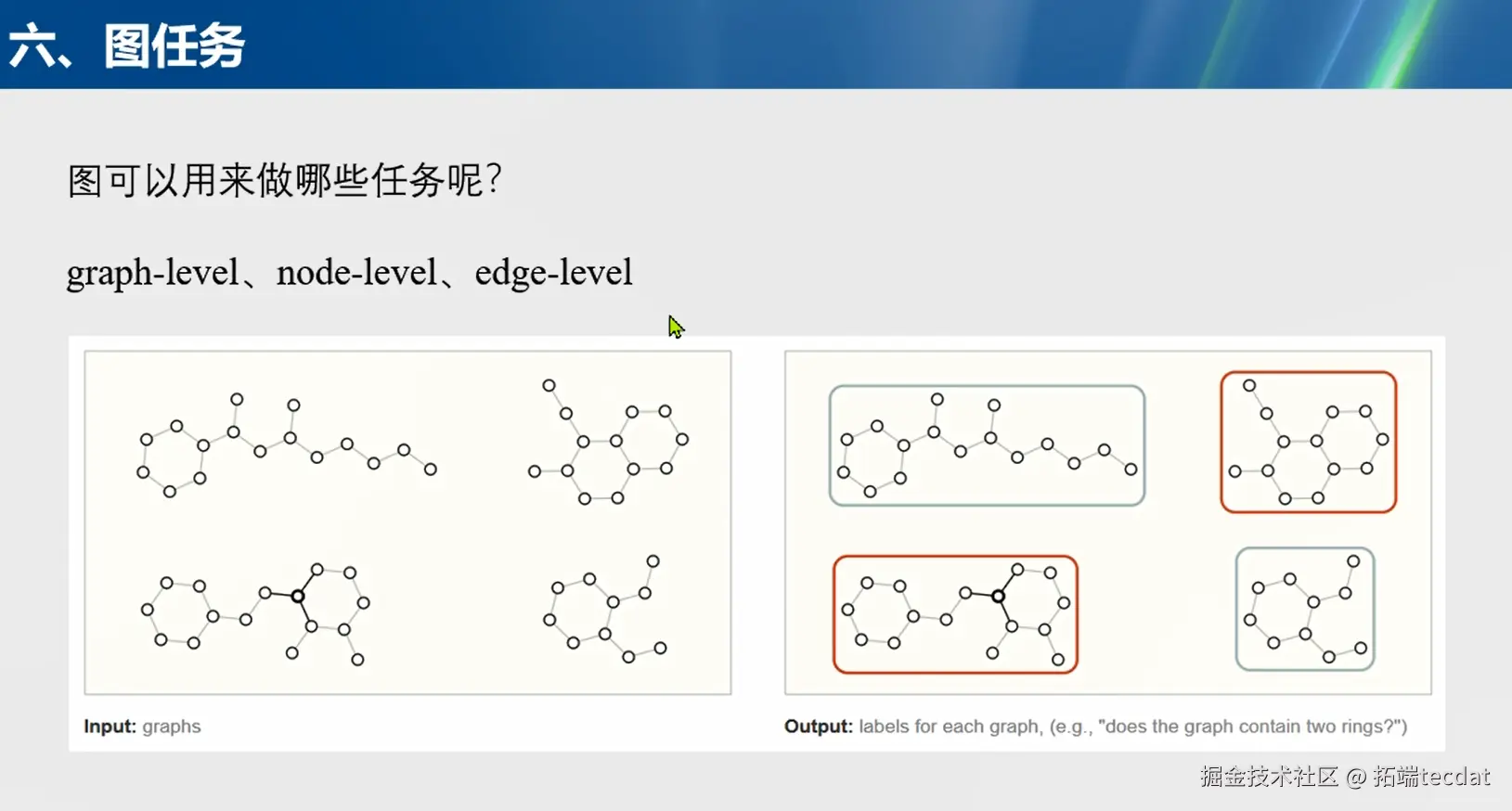
任务层级
图任务主要分为图级(graph – level)、节点级(node – level)和边级(edge – level) 。图级任务是对整个图进行分类或回归等操作,例如判断一个分子结构是否属于某类化合物;节点级任务关注单个节点的属性或类别预测,如在社交网络中预测某个用户的兴趣爱好;边级任务则侧重于分析边的属性或连接关系,比如判断两个用户之间是否存在某种特定的社交关系。
应用示例
从图示来看,输入不同的图结构,通过GNN处理后,输出对每个图的标签预测,如判断图中是否包含特定的结构(如两个环)。在实际应用中,图级任务可用于图像分类、分子活性预测;节点级任务可用于推荐系统中的用户行为预测、生物网络中的蛋白质功能预测;边级任务可用于社交网络中的关系预测、交通网络中的道路流量预测等。
七、应用案例与展望
应用案例
在社交网络分析中,GNN可以通过消息传递机制聚合用户邻居的信息,准确预测用户的兴趣偏好,从而实现精准推荐。在分子结构研究领域,GNN能够对分子图进行特征学习,预测分子的化学性质和生物活性,加速药物研发进程。在交通网络中,GNN可以根据道路连接关系和交通流量信息,预测交通拥堵情况,辅助交通管理决策。
发展展望
随着数据规模和复杂性的不断增加,GNN面临着计算效率和可扩展性的挑战。未来,需要进一步优化GNN的算法结构,探索更高效的消息传递机制和模型训练方法,以提升其在大规模图数据上的处理能力。同时,GNN与其他技术(如强化学习、生成对抗网络)的融合也将成为研究热点,有望拓展其在更多领域的应用,如智能交通、金融风控、生物医学等,为解决复杂的实际问题提供更强大的技术支持。
八、结论
图神经网络作为处理非欧式数据的重要技术,以其独特的核心思想、网络结构和消息传递机制,在众多领域展现出巨大的应用潜力。通过对GNN的深入研究,我们能够更好地理解和处理现实世界中的复杂图结构数据,为各行业的数字化转型和智能化发展提供有力的技术保障。在未来的研究和实践中,持续探索GNN的优化和拓展方向,将有助于推动其在更多领域的广泛应用和创新发展。
Python时空图神经网络ST-GNNs-PCA嵌入交通数据预测可视化及KPCA核主成分分析汽油精制应用实例
本研究横跨交通预测与汽油精制两大领域,PCA 嵌入在其中均扮演着核心角色,我们旨在通过深入探索与研究,全面展示 PCA 嵌入在不同复杂系统中的卓越性能与广泛应用潜力。本研究横跨交通预测与汽油精制两大领域,PCA 嵌入在其中均扮演着核心角色,我们旨在通过深入探索与研究,全面展示PCA嵌入在不同复杂系统中的卓越性能与广泛应用潜力。
在当今时代,交通预测对于城市的高效运转和规划具有极为关键的意义。随着科技的不断进步,时空图神经网络(ST – GNNs)以及变换器模型应运而生,它们凭借对交通数据中时间与空间相关性的有效建模能力,在交通预测领域初露锋芒,为精准预测交通状况带来了新的希望与可能。然而,不可忽视的是,现代城市正经历着前所未有的快速城市化进程,城市的交通模式和出行需求如同变幻莫测的风云,处于持续的动态变化之中。这种动态性给长期交通预测工作设置了重重障碍,使得追求精准预测变得异常艰难。
在此背景下,为了突破这一瓶颈,我们开启了一场对自适应嵌入设计的深度反思与重新探索之旅,创新性地提出了主成分分析(PCA)嵌入方法。这一方法宛如一把神奇的钥匙,赋予模型无需重新训练即可巧妙适应新场景的卓越能力。通过将 PCA 嵌入巧妙整合到现有的 ST – GNN 和变换器架构之中,我们欣喜地见证了模型性能的显著提升。值得一提的是,PCA 嵌入独特的灵活性使得训练与测试之间的图结构能够自由变换,从而使得在一个城市中训练得到的模型能够在其他城市实现零样本预测,这无疑为时空模型的鲁棒性和泛化能力注入了强大动力,为交通预测领域开辟了新的视野与方向。
此外,在化工领域的汽油精制过程中,辛烷值作为核心指标备受关注。众多因素如原料性质、吸附剂性质以及操作变量等相互交织,影响着辛烷值的损耗。为了精准把握其中的关键变量,我们采用先降维后建模的策略,分别运用多元线性回归模型处理原料性质和吸附剂方面的变量关系,借助 KPCA 核主成分分析模型应对操作变量的非线性关系,成功筛选出主要变量,实现了从复杂变量体系到关键少数的有效聚焦。本研究综合交通预测与汽油精制过程中的变量处理研究,旨在为相关领域的技术发展提供全面且深入的方法与思路,以应对实际应用中的各种挑战与需求。
ST-GNNs-PCA交通数据预测 |附数据代码
时空图神经网络(ST – GNNs)和变换器模型的近期进展为交通预测开辟了令人振奋的可能性。这些模型擅长捕捉交通数据中的空间和时间依赖性,通过利用交通网络结构在稳定条件下提供有前景的结果[1] – [7]。
然而,现代城市快速的城市化进程和持续变化给准确的交通预测带来独特挑战[5],[8] – [10]。随着城市发展,交通模式和需求难以预测地发生变化,这需要模型能够跟上这些动态变化。
视频
主成分分析PCA降维方法和R语言分析葡萄酒可视化实例
视频
【视频讲解】PCA主成分分析原理及R语言经济研究可视化2实例合集
视频
PCA原理与水果成熟状态数据分析实例:Python中PCA-LDA 与卷积神经网络CNN
视频
机器学习的交叉验证Cross Validation原理及R语言主成分PCA回归分析城市犯罪率
视频
Python、R时间卷积神经网络TCN与CNN、RNN预测时间序列实例
视频
CNN(卷积神经网络)模型以及R语言实现
视频
Python深度神经网络DNNs-K-Means(K-均值)聚类方法
问题陈述
在交通预测中,我们定义一个图为(G=(V, E, A)),其中(V)是节点集合,(E\subseteq V\times V)表示边,(A)是与图(G)相关联的邻接矩阵。在每个时间步(t),图与实数空间(R^
V|\times C)中的动态特征矩阵(X_t)相关联,其中(C)表示节点特征的维度(例如,交通流量、交通速度、一天中的时间和一周中的时间)。交通预测涉及开发和训练一个神经网络模型(f_{\theta}),其公式为:(f_{\theta}:[X_t, A, E]\mapsto Y_t),其中(E)表示从训练数据学习的自适应嵌入层,(X_t = X_{(t – l_1):t})且(Y_t = X_{(t + 1):(t + l_2)}),(l_1)和(l_2)分别表示输入和输出序列的长度。
方法论
(一)自适应嵌入层概述
在交通预测中,空间不可区分性构成一个重大挑战,即在特定观察窗口内具有紧密对齐历史模式的时间序列在其未来轨迹中显示出显著差异。为解决此问题,研究人员利用了托布勒第一地理定律,通过将图神经网络引入交通预测以解决空间不可区分性。图神经网络中的消息传递基于局部相似性原则,其中邻近节点预期表现出相似的交通模式。用于交通预测的时空图通常使用道路连接距离或绝对物理坐标来计算边权重。然而,这些预定义图中的连接关系往往不完整或有偏差,因为它们严重依赖补充数据和人类专业知识,这使得捕捉空间依赖的全面全景图的任务变得复杂。为应对这一挑战,自适应图方法被提出以利用自适应嵌入的参数表示,这些参数在整个训练阶段不断更新以最小化模型误差。自适应图旨在识别源自人类定义概念的偏差,并揭示数据中的隐藏空间依赖。主流自适应图学习方法利用随机初始化的可学习矩阵。传统上,自适应图生成如下:
# 此处为生成自适应图的代码示例(可根据实际情况修改变量名等)
# 假设 E 为自适应嵌入矩阵,N 为节点数量,C 为嵌入维度
import torch
N = 100 # 示例节点数量
C = 20 # 示例嵌入维度
E = torch.randn(N, C) # 随机初始化自适应嵌入矩阵![]()
其中(E\in R^{N\times C})是自适应嵌入,随机初始化,(N)表示节点数量,(C)为嵌入维度。最近,更具创新性的方法被引入,这些方法绕过自适应图的构建,转而使用可学习的节点嵌入技术。诸如STID和STAEformer等模型引入可训练的自适应嵌入,从而增强模型区分相似历史模式的能力。这些策略中的每一种都为解决多变量时间序列预测中空间不可区分性的基本挑战提供了独特方法。
(二)自适应嵌入的局限性
在本节中,我们深入探讨自适应嵌入固有的三个关键局限性:过度的空间不可区分性、缺乏归纳能力和有限的可迁移性。
- 缺乏归纳能力:随着城市环境演变,新的基础设施和交通模式出现,使得以前不可区分的位置随着时间推移可能变得不同。然而,自适应嵌入在推理过程中依赖固定嵌入,其适应这种动态变化的能力本质上是有限的。这一限制在图5中直观地显示出来,其中随着环境偏离其训练分布,模型性能下降。图5显示,虽然长短期记忆(LSTM)模型在分布内和分布外设置中保持相对较低的平均绝对误差(MAE)值,但其他最先进的模型(GWNet、AGCRN、MTGNN、TrendGCN、STAEformer)对分布变化表现出明显的敏感性,突出了自适应嵌入缺乏归纳能力的事实。
- 过度空间可区分性:自适应嵌入可能受到过度空间可区分性的影响,特别是对于空间关系不太关键的数据集。
- 有限可迁移性:自适应嵌入的一个关键限制在于其在不同场景和部署中的可迁移性受限。随着传感器部署随时间演变,维持固定的图大小变得越来越具有挑战性,特别是当城市环境需要通过添加、退役或临时故障对其传感器网络进行修改时。自适应嵌入的固有设计与特定传感器紧密耦合,严重限制了其在不同城市的适用性,对于每个新部署都需要完整的模型重新训练。这种不灵活性在基础设施变化频繁的快速发展城市地区尤其成问题,导致显著的计算开销和资源需求。虽然近期研究提出了潜在解决方案,如元学习框架和迁移学习策略,但这些方法未能解决自适应嵌入的核心问题。因此,大多数主流ST模型缺乏泛化能力。
(三)主成分分析嵌入
为解决自适应嵌入的上述局限性,我们提出PCA嵌入作为一种替代方法。PCA嵌入通过其统计和数据驱动性质有效缓解了三个关键挑战,同时保持捕捉基本时空关系的能力。

形式上,由于交通数据的固有周期性,我们首先将每一天划分为相等的时间槽以获得(Z\in R^{D\times N\times T}),其中(D)是天数,(N)表示节点数量,(T)是一天中的时间槽数量(例如,以5分钟采样间隔,(T = 288))。然后我们应用PCA以获得每天的嵌入矩阵:(E_{d_{pca}} = Z_d\cdot P\in R^{N\times C}),(d\in{1,…,D}),其中(P)是由PCA生成的投影矩阵,(C)是PCA嵌入的维度。随后,我们对所有训练日的PCA嵌入进行平均以获得最终的节点表示:![]()
# 计算PCA嵌入矩阵的代码示例(可修改变量名等)
import torch
import numpy as np
from sklearn.decomposition import PCA
# 假设 Z 是按天划分的交通数据矩阵,形状为 (D, N, T)
D = 10 # 示例天数
N = 50 # 示例节点数量
T = 12 # 示例一天中的时间槽数量
Z = torch.randn(D, N, T) # 示例数据
# 将 Z 转换为适合PCA处理的形状 (D * N, T)
Z_reshaped = Z.reshape(D * N, T)
# 应用PCA
pca = PCA()
pca.fit(Z_reshaped)
P = pca.components_.T # 投影矩阵
# 计算每天的PCA嵌入矩阵
E_d_pca_list = []
for d in range(D):
Z_d = Z[d]
E_d_pca = Z_d @ P
E_d_pca_list.append(E_d_pca)
# 平均PCA嵌入矩阵
E_final = np.mean(E_d_pca_list, axis=0)
在测试阶段,使用相同的PCA投影矩阵(P)以确保特征提取的一致性。
# 测试阶段使用PCA投影矩阵的代码示例(可修改变量名等)
# 假设 X_test 是测试数据矩阵
X_test = torch.randn(N, T) # 示例测试数据
E_test = X_test @ P # 计算测试数据的PCA嵌入
为减轻信息泄漏,将验证集的一小部分(5%)指定为验证子集。然后应用PCA提炼捕捉系统时空动态的关键特征。
- PCA嵌入的优势:PCA嵌入方法通过其严格的统计基础和数据驱动的适应性有效克服了自适应嵌入的三个关键约束。下面,我们详细说明PCA嵌入如何解决每个局限性:
- 首先,就有限归纳能力而言,PCA的泛化能力显著,因为它捕捉输入数据的基本统计特征而非依赖固定的、可训练参数。随着环境动态变化,PCA通过从更新的数据输入重新计算特征,本质上适应分布变化,从而在不同条件下保持其性能。这与可能需要重新训练以适应的静态嵌入形成对比。
- 其次,PCA通过其正交基表示缓解过度空间可区分性的挑战,确保提取的空间特征保持相互独立。通过适当选择解释总方差足够比例的主成分子集(例如,(\sum_{i = 1}^{k}\lambda_i / \sum_{i = 1}^{n}\lambda_i\geq\theta)),PCA保持平衡的空间表示而不会过拟合训练数据。这一特性使其在需要空间泛化的场景中特别稳健。
- 第三,PCA的固有统计方法有效解决了可迁移性差的限制,这允许在不同场景和部署中无缝应用。在传感器网络发生改变(如节点的添加、退役或故障)的情况下,仅需重新计算PCA衍生特征((X_{new_{PCA}}\to E_{adapted})),无需重新训练整个模型。我们的实验总结于表I:
-

这些结果展示了时空模型的零样本能力,特别是在小规模和大规模设置中。这些结果凸显了变换器架构的巨大潜力。总体而言,PCA在提取关键ST关系的同时提供增强的泛化能力、受控的空间区分和改进的跨上下文可迁移性,使其成为不断发展的城市环境中的重要工具。我们总结PCA嵌入的优势如下:

实践
在本节中,我们通过解决以下研究问题来分析PCA嵌入的性能:
- RQ1:PCA嵌入的性能是否与自适应嵌入一致?
- RQ2:PCA嵌入在零样本泛化方面表现如何?
- RQ3:PCA嵌入在面对空间变化时表现如何?
- RQ4:为什么PCA嵌入在零样本泛化中起作用?
- RQ5:与微调方法相比,PCA嵌入表现如何?
为评估当前ST – GNNs的空间变化性能,我们引入四个交通基准数据集:PEMS03 – 2019、PEMS04 – 2019、PEMS07 – 2018和PEMS08 – 2017,这些这些数据集符合现有标准[22],[23],并使用相同的传感器在不同年份捕获交通数据。数据集的详细信息如表II所示。

实验设置涉及基于历史数据的前12个时间步预测接下来的12个时间步[12],[19]。按照[23]中所述的方法,我们按时间顺序将数据划分为训练集、验证集和测试集,对于同年和跨年数据均保持6:2:2的比例。为防止信息泄漏,我们使用第二年数据的5%进行PCA降维以生成嵌入,然后在剩余的95%上进行测试。

(一)与自适应嵌入的比较(RQ1)
我们旨在解决的主要研究问题是,使用PCA嵌入而非可学习嵌入是否会导致训练期间模型性能下降。为探索这一点,我们在PEMS基准上对模型性能进行了比较分析,同时使用PCA嵌入和可学习嵌入。我们的结果表明,与可学习嵌入相比,使用PCA嵌入不会显著降低模型有效性,这表明手动降维可以实现与可学习方法相当的结果。值得注意的是,在某些情况下,PCA嵌入甚至表现出更优性能。我们假设这种改进主要是由于PCA嵌入在减轻模型过拟合方面具有更强的能力。近期研究[5],[9],[10]已经确定了空间变化问题,尽管原始测试数据仅相隔三周收集。我们观察到,循环神经网络架构,如AGCRN和TrendGCN,更容易出现过拟合,并且变换器架构在PEMS03数据集上也会遇到此问题。
随时关注您喜欢的主题
(二)零样本性能(RQ2)
虽然使用PCA嵌入不一定会在分布内性能上产生改进,但我们的工作揭示了在模型可解释性方面的显著优势。它使我们能够超越以前的训练范式,以前的训练范式通常将模型验证局限于相同的测试集。我们的方法允许在不同数据集上进行模型验证,而不管节点数量的变化。具体而言,如表I所示,我们在PEMS03和PEMS07数据集上使用PCA嵌入进行训练。我们使用(A→B)表示模型在数据集(A)上训练并在数据集(B)上测试。在测试阶段,我们通过分别应用从PEMS03和PEMS07导出的投影矩阵(W)来替换嵌入,以生成来自PEMS04和PEMS08的训练样本的嵌入(E)。
表I显示,STAEformer(基于变换器的架构)表现出卓越的零样本泛化能力。此外,我们的发现表明,利用更大的数据集,如PEMS07的883个节点相比于PEMS03的358个节点,会带来更优性能,这表明数据集大小与泛化能力之间存在正相关关系。基于这些结果,我们假设PCA嵌入可能成为未来大规模交通模型的统一范式。同样,我们在表I中的LargeST[6]中进行了实验。以与先前实验一致的方式,我们分别在圣地亚哥和湾区数据集上训练模型,然后在其余场景中进行测试。我们观察到ST – 模型的零样本能力被显著低估。以前的训练范式未能充分释放模型的潜力。相比之下,我们的结果表明,零样本性能与在这些数据集上训练的模型相比并没有显著劣势。
我们相信PCA嵌入方法为未来大规模交通模型的发展铺平了道路。
(三)PEMS一年的测试性能(RQ3)
表展示了在原始PEMS基准数据集[23]上训练并在我们收集的跨年度数据上测试的ST模型性能的比较分析。我们还展示了在不同预测范围(预测范围3、预测范围6、预测范围12)中纳入我们的PCA嵌入策略的结果。在几乎所有情况下,添加PCA嵌入显著增强了模型泛化能力。我们的方法对不同架构的模型适应良好,并在所有数据集上都表现出出色的性能提升。在PEMS03数据集上的改进尤为显著,我们观察到性能有大幅提升。例如,对于STID,平均MAE从33.99降至9.18,RMSE从46.70降至13.75,MAPE从686.25降至…在PEMS04数据集上,我们在所有模型中都观察到一致的改进。例如,对于MTGNN,平均MAE从46.72降至24.61,RMSE从71.38降至39.45,MAPE从43.07降至…对于PEMS07和PEMS08,改进同样令人印象深刻。在PEMS08中,带有PCA的STID取得了显著收益,平均MAE从37.33降至15.96,RMSE从62.12降至26.62,MAPE从26.36降至…这些在不同数据集和模型架构上的全面改进证明了我们的PCA嵌入策略在增强时空交通预测性能方面的有效性。不同预测范围中MAE、RMSE和MAPE指标的持续降低凸显了我们方法的鲁棒性和泛化能力。
(四)与不同策略的比较(RQ4)
我们通过在表III中对PCA嵌入和零嵌入策略进行全面比较来扩展我们的分析。
model = AGCRN(
num_layer=args.num_layer,
cheb_k=args.cheb_k,
)
loss_fn = mad_mae
optizer = torch.optim.Adam(

零嵌入策略,即在测试阶段将自适应嵌入设置为零,旨在消除训练阶段引入的潜在偏差[11]。然而,我们的实证观察表明,与使用原始嵌入相比,这种方法在零样本评估中并非最优。此外,我们研究了自适应嵌入的微调策略,其中微调使用与PCA相同的5%验证数据进行。比较分析突出了不同架构在泛化性能上的显著差异。值得注意的是,更简单的嵌入策略,如STID和STAEformer所使用的策略,表现出更优的泛化能力。特别是PCA嵌入产生的性能指标与通过微调获得的指标非常接近。这一结果可以通过考虑自适应嵌入的固有目的来解释,如在STID中所述,其主要目的是减轻时空不可区分性问题。通过应用PCA,主成分有效地描绘了不同传感器的表示,从而增强了模型的整体判别能力。结果表明,PCA可能适用于广泛的场景,特别是当计算效率和模型可解释性被优先考虑时。
(五)PCA嵌入的可视化(RQ4)

图展示了一个全面的4×4 PCA嵌入对齐矩阵,说明了不同PEMS数据集之间的跨数据集可迁移性模式。每个子图显示了PCA嵌入在降维特征空间中的分布,其中蓝色点表示源数据集嵌入,红色点表示目标数据集嵌入。可视化方法有效地揭示了不同交通监测系统之间的内在结构对应关系和差异。嵌入的空间排列揭示了不同程度的跨数据集对齐,这对于理解交通预测任务中的迁移学习和零样本泛化潜力尤为关键。值得注意的是,某些数据集对表现出高度的嵌入重叠,表明其底层交通模式具有强大的结构相似性,而其他数据集对则显示出更分散的分布,表明特定领域的特征。这种基于PCA的嵌入分析不仅验证了不同PEMS数据集之间可迁移特征的存在,还为评估智能交通系统中跨域适应的可行性提供了一个定量框架,从而有助于我们理解城市交通模式的基本结构及其在不同监测系统中的泛化潜力。
(六)PCA嵌入能否避免过度可区分性?(RQ5)
我们进行了全面的网格搜索,以确定当应用于PEMS03数据集时,STID和STAEformer模型的最佳主成分数量,如图所示。
data_path, adj_pth, ode_num = getdataseinfo(args.dataset)
logger.info("Adj path: " + adj_path)rgs, logger)
model = STID
no_nu=node_num,
input_dim=ags.input_dim,
output_dim=rgs.output_dim,
if_spatial=True,
lossfn = maskedmae
optimizer =rameter), lr=args.lrate,
我们的结果表明,这两个模型分别在大约4个和8个主成分时达到峰值性能。超过这些阈值,性能要么下降(对于STID)要么趋于平稳(对于STAEformer)。波动的平均绝对误差(MAE)曲线,在STID中尤为明显,表明传统方法在纳入过度的空间区分时可能容易出现过拟合。我们的发现表明,使用具有受限主成分数量的PCA嵌入可以有效地保留关键空间信息,同时超越依赖可训练自适应嵌入的基线模型(由红色虚线表示)。这一结果证实了之前提到的关于自适应嵌入中过度可区分性潜在陷阱的警告,特别是在空间关系至关重要的数据集中。
综上所述,PCA嵌入在交通预测领域展现出诸多优势,能够有效应对自适应嵌入存在的局限性,在提升模型性能、泛化能力以及应对空间变化等方面具有显著的潜力,为交通预测模型的发展提供了新的思路与方法,有望在未来的智能交通系统中发挥重要作用,推动交通预测技术的进一步发展与应用。
KPCA汽油精制过程的降维筛选应用案例
辛烷值(RON)作为反映汽油燃烧性能最重要的指标,一直是催化裂化汽油精制研究的重点对象。在化工进行催化裂化炼油的过程中,硫含量、饱和烃、溴值等原料性质,待生与再生吸附剂性质,以及氢油比、反应器温度、再生器压差等外界环境性质都会对辛烷值的损耗产生一定影响。在众多因素变量的影响下,成功筛选主要影响变量是对辛烷值进行损失研究的关键一步。
主要研究思路:
采用先降维后建模的方法,从三方面着手对其考虑。针对原料性质方面及待生与再生吸附剂方面探寻其内部变量是否具有线性关系,并进一步建立多元线性回归模型求解降维;针对氢油比、反应器温度、再生器压差等354个操作变量,根据其内部变量非线性的特点建立KPCA核主成分分析模型求解降维,从而筛选出具有代表性的主要建模变量。
考虑一——原料性质:多元线性回归模型
通过查阅文献可以发现,硫含量与辛烷值通常呈正相关关系,硫含量越低,辛烷值越低。同时,原料性质中的其余变量如饱和烃、密度等含量也都和辛烷值大小存在一定的联系。所以,下面我们对原料性质中的7个变量进行分析,进一步探论变量间的关系,从而对能否降维做出判断。

图1 原料性质中不同变量间的相关性
首先,针对辛烷值、硫含量、饱和烃、烯烃、芳烃、溴值及密度7个变量做其相关矩阵(见图1)。
由图1可以看出,硫含量、饱和烃和烯烃之间存在十分显著的相关性;密度也有一定的相关性,但相关性相较而言不是特别显著,我们选择将其暂时搁置,不作降维处理;另一方面通过矩阵我们也可以明显地看出芳烃和溴值与其他变量间的相关性十分微弱,因此我们可以考虑是否将该变量在后文中剔除的问题。
在判断出来原料性质中7个不同变量间存在部分相关关系后,我们对其是否存在线性关系进行进一步的讨论。
在未知其是否具有线性关系的情况下,我们先对各变量进行拟合,绘制散点图做出线性判断。拟合结果如下图所示(见图2):



图2 辛烷值与硫含量、饱和烃、烯烃、芳烃、溴值及密度的关系
通过拟合可以发现,芳烃和溴值的散点图图像呈块状分布,并不接近于一条直线。因此可以初步猜测芳烃、溴值均与辛烷值之间不存在线性关系,通过后文进一步研究来判断是否可以将其剔除,实现原料性质变量的部分降维。
根据拟合结果,我们建立多元线性回归模型,对辛烷值与其他六个变量的线性性进行讨论研究。
考虑二——吸附剂:多元线性回归模型
吸附剂作为现代工业不可或缺的产品,在石油工业的采油、炼油方面发挥着重要作用。它能够脱除原料中的硫含量,从而进行汽油的精制。同时,再生吸附剂又可以实现吸附剂的循环使用,从而减少废渣的生成,降低处理成本,提高炼油效率。
我们很容易想到,两种吸附剂之间应该存在某种关系。所以同理,接下来我们对待生吸附剂焦炭、待生吸附剂S、再生吸附剂焦炭、再生吸附剂S绘制相关矩阵(见图3),从而对其是否具有相关性、能否进行降维进行进一步的判断。

图3 待生吸附剂性质与再生吸附剂性质的相关性
由图可知,待生吸附剂焦炭、待生吸附剂S、再生吸附剂焦炭、再生吸附剂S之间的相关性十分显著。下面对其是否具有线性关系进行进一步探讨。
考虑三——氢油比、反应器温度等354个操作变量:KPCA核主成分分析模型
在化工进行炼油工艺时,由于该程序的复杂性及设备的多样性,这些操作变量之间往往具有高度的非线性和相互强耦联的关系。通常情况下进行降维处理时,我们首先会考虑使用主成分分析法(PCA)进行处理,然而由于主成分分析仅适用于线性关系的背景,对于此时非线性关系的情况,我们可以先对数据通过核函数转换空间,然后再利用主成分分析进行处理。即建立KPCA核主成分分析模型进行操作变量的降维。
KPCA核主成分分析方法的核心思想是通过引入核函数方法将输入到空间的数据映射到特征空间,并在特征空间进行主成分分析,从而实现数据的降维。
1.多元线性回归模型的求解
(一)针对原料性质
基于逐步回归方法(见图4)可以得到辛烷值
关于硫含量、饱和烃、烯烃、芳烃、溴值及密度

图4 逐步回归排除变量结果
即通过逐步回归,将烯烃、芳烃和溴值这三个变量排除,建立了辛烷值与硫含量、饱和烃、密度有关的线性方程。基于此对其进行显著性检验与回归诊断(见图5-图7):

图5 模型显著性结果
由上图模型汇总的结果可知,逐步回归后该模型的
方检验量为0.307,模型效果比较显著。

图6 自变量显著性结果
由图6自变量回归系数的显著性结果可知,最终得到的回归模型中硫含量、饱和烃及密度的sig值都远小于0.05,效果十分显著,可以说明辛烷值与这三个原料性质变量之间存在明显的线性关系
图7 残差时序图
由上图残差时序图也可知,残差基本处于对称


分布状态,上下波动基本稳定在一定范围内,回归拟合效果比较理想
KPCA核主成分分析模型的求解
根据MATLAB计算,可以最终得到22个累计贡献率大于85%的主成分,相关结果如下所示(见表3、图11)。
表3 各主成分累计贡献率


由于所得主成分并非是独立变量,不是354个操作变量中的某几个,而是这些变量的线性组合,即记各个所得主成分最终表示

因此,综上所述,通过降维筛选我们可以得到共计29个主要变量,其中包括4个原料性质(辛烷值、硫含量、饱和烃、密度)、2个产品性质(辛烷值、硫含量)、1个吸附剂性质及22个贡献率大于85%的操作变量主成分。实现了从367个变量到29个主要变量的降维,同时可以清楚地看出所得的主成分数据具有很强的代表性,其他几个性质变量数据也具有极强的代表性与独立性。
参考文献
[1] C. Shang, J. Chen, and J. Bi, “Discrete graph structure learning for forecasting multiple time series,” in International Conference on Learning Representations, 2021.
[2] S. Lan, Y. Ma, W. Huang, W. Wang, H. Yang, and P. Li, “Dstagnn: Dynamic spatial-temporal aware graph neural network for traffic flow forecasting,” in International conference on machine learning. PMLR, 2022, pp. 11906–11917.
[3] H. Lee, S. Jin, H. Chu, H. Lim, and S. Ko, “Learning to remember patterns: Pattern matching memory networks for traffic forecasting,” in International Conference on Learning Representations, 2022.
[4] R. Jiang, Z. Wang, J. Yong, P. Jeph, Q. Chen, Y. Kobayashi, X. Song, S. Fukushima, and T. Suzumura, “Spatio-temporal meta-graph learning for traffic forecasting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 7, 2023, pp. 8078–8086.
[5] Y. Xia, Y. Liang, H. Wen, X. Liu, K. Wang, Z. Zhou, and R. Zimmermann, “Deciphering spatio-temporal graph forecasting: A causal lens and treatment,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
[6] X. Liu, Y. Xia, Y. Liang, J. Hu, Y. Wang, L. Bai, C. Huang, Z. Liu, B. Hooi, and R. Zimmermann, “Largest: A benchmark dataset for large-scale traffic forecasting,” Advances in Neural Information Processing Systems, vol. 36, 2024.
[7] R. Jiang, Z. Wang, Y. Tao, C. Yang, X. Song, R. Shibasaki, S.-C. Chen, and M.-L. Shyu, “Learning social meta-knowledge for nowcasting human mobility in disaster,” in Proceedings of the ACM Web Conference 2023, 2023, pp. 2655–2665.
[8] Y. Zhang, Y. Li, X. Zhou, X. Kong, and J. Luo, “Curb-gan: Conditional urban traffic estimation through spatio-temporal generative adversarial networks,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 842–852.
[9] Z. Zhou, Q. Huang, K. Yang, K. Wang, X. Wang, Y. Zhang, Y. Liang, and Y. Wang, “Maintaining the status quo: Capturing invariant relations for ood spatiotemporal learning,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 3603–3614.
[10] J. Ji, W. Zhang, J. Wang, Y. He, and C. Huang, “Self-supervised deconfounding against spatio-temporal shifts: Theory and modeling,” arXiv preprint arXiv:2311.12472, 2023.
[11] Z. Shao, Z. Zhang, F. Wang, W. Wei, and Y. Xu, “Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,” in Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 2022, pp. 4454–4458.
[12] Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,” in Proceedings of the 28th International Joint Conference on Artificial Intelligence, 2019, pp. 1907–1913.
[13] L. Bai, L. Yao, C. Li, X. Wang, and C. Wang, “Adaptive graph convolutional recurrent network for traffic forecasting,” Advances in neural information processing systems, vol. 33, pp. 17804–17815, 2020.
[14] Z. Wu, S. Pan, G. Long, J. Jiang, X. Chang, and C. Zhang, “Connecting the dots: Multivariate time series forecasting with graph neural networks,” in Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 753–763.
[15] J. Jiang, B. Wu, L. Chen, K. Zhang, and S. Kim, “Enhancing the robustness via adversarial learning and joint spatial-temporal embeddings in traffic forecasting,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 987–996.
[16] H. Liu, Z. Dong, R. Jiang, J. Deng, J. Deng, Q. Chen, and X. Song, “Spatio-temporal adaptive embedding makes vanilla transformer sota for traffic forecasting,” in Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 4125–4129.
[17] Z. Shao, F. Wang, Y. Xu, W. Wei, C. Yu, Z. Zhang, D. Yao, G. Jin, X. Cao, G. Cong et al., “Exploring progress in multivariate time series forecasting: Comprehensive benchmarking and heterogeneity analysis,” arXiv preprint arXiv:2310.06119, 2023.
[18] S. Guo, Y. Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial-temporal graph convolutional networks for traffic flow forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 922–929.
[19] Y. Li, R. Yu, C. Shahabi, and Y. Liu, “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,” in International Conference on Learning Representations, 2018.
[20] R. Jiang, D. Yin, Z. Wang, Y. Wang, J. Deng, H. Liu, Z. Cai, J. Deng, X. Song, and R. Shibasaki, “Dl-traff: Survey and benchmark of deep learning models for urban traffic prediction,” in Proceedings of the 30th ACM international conference on information & knowledge management, 2021, pp. 4515–4525.
[21] C. Chen, K. Petty, A. Skabardonis, P. Varaiya, and Z. Jia, “Freeway performance measurement system: mining loop detector data,” Transportation research record, pp. 96–102, 2001.
[22] C. Song, Y. Lin, S. Guo, and H. Wan, “Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, pp. 914–921.
[23] S. Guo, Y. Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial-temporal graph convolutional networks for traffic flow forecasting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 922–929.
[24] T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski, “Vision transformers need registers,” arXiv preprint arXiv:2309.16588, 2023.
[25] F. Zhuang, Z. Qi, K. Duan, D. Xi, Y. Zhu, H. Zhu, H. Xiong, and Q. He, “A comprehensive survey on transfer learning,” Proceedings of the IEEE, vol. 109, no. 1, pp. 43–76, 2023.
[26] S. C. Hoi, D. Sahoo, J. Lu, and P. Zhao, “Online learning: A comprehensive survey,” Neurocomputing, vol. 459, pp. 249–289, 2021.
[27] S. Wold, K. Esbensen, and P. Geladi, “Principal component analysis,” Chemometrics and intelligent laboratory systems, vol. 2, no. 1-3, pp. 37–52, 1987.
[28] F. Pourpanah, M. Abdar, Y. Luo, X. Zhou, R. Wang, C. P. Lim, X.-Z. Wang, and Q. J. Wu, “A review of generalized zero-shot learning methods,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 4, pp. 4051–4070, 2022.
[29] W. R. Tobler, “A computer movie simulating urban growth in the detroit region,” Economic geography, vol. 46, no. sup1, pp. 234–240, 1970.
[30] X. Luo, C. Zhu, D. Zhang, and Q. Li, “Stg4traffic: A survey and benchmark of spatial-temporal graph neural networks for traffic prediction,” arXiv preprint arXiv:2307.00495, 2023.
[31] B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, 2018, pp. 3634–3640.
[32] Z. Shao, Z. Zhang, W. Wei, F. Wang, Y. Xu, X. Cao, and C. S. Jensen, “Decoupled dynamic spatial-temporal graph neural network for traffic forecasting,” in Proceedings of the VLDB Endowment, 2022, pp. 2733–2746.

关于分析师
Jiaqi Teng
在此对 JiQuan Zhao 对本文所作的贡献表示诚挚感谢,他在计算机技术领域完成了硕士学位,专注深度学习、图神经网络领域。擅长 Python、PyCharm 。JiQuan Zhao 是一名分析师,专注于计算机技术相关领域,在深度学习和图神经网络方面具备专业知识。

Jiaqi Teng
在此对 Jiaqi Teng 对本文所作的贡献表示诚挚感谢,她在新疆大学完成了统计学专业的硕士学位,擅长 R 语言、Python、SAS、SPSS、Matlab,在多元统计分析、数据清洗、经济金融、生物医学等领域有所研究。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码
多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码 RAG与Python的智能编程教程问答系统:DeepSeek大模型驱动、LangChain流程构建、FAISS向量检索与语义相似度匹配技术实现|附教程文档
RAG与Python的智能编程教程问答系统:DeepSeek大模型驱动、LangChain流程构建、FAISS向量检索与语义相似度匹配技术实现|附教程文档 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据
Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据



