
您将学习如何使用Prophet(在R中)解决一个常见问题:预测公司明年的每日订单。
Prophet最适合每日数据以及至少一年的历史数据。
Prophet 是一个时间序列预测工具,由 Facebook 开发。
它可以用于对具有季节性和趋势性的数据进行预测,例如销售数据、股票价格等。
它具有较高的准确性和易用性,被广泛应用于数据科学和机器学习领域。
我们将使用SQL处理每天要预测的数据:

数据准备与探索
`select
`` date,
value
from modeanalytics.daily_orders
order by date`
时间序列预测一直是预测问题中的难点,人们很难找到一个适用场景丰富的通用模型,这是因为现实中每个预测问题的背景知识,例如数据的产生过程,往往是不同的,即使是同一类问题,影响这些预测值的因素与程度也往往不同,再加上预测问题往往需要大量专业的统计知识,这又给分析人员带来了难度,这些都使得时间序列预测问题变得尤其复杂。
传统的时间序列预测方法,例如ARIMA(autoregressive integrated moving average)模型,在R与Python中都有实现。虽然这些传统方法已经用在很多场景中了,但它们通常有如下缺陷:
a.适用的时序数据过于局限
例如最通用的ARIMA模型,其要求时序数据是稳定的,或者通过差分化后是稳定的,且在差分运算时提取的是固定周期的信息。这往往很难符合现实数据的情况。
b.缺失值需要填补
对于数据中存在缺失值的情况,传统的方法都需要先进行缺失值填补,这很大程度上损害了数据的可靠性。
c.模型缺乏灵活性
传统模型仅在于构建数据中的临时依赖关系,这种模型过于不够灵活,很难让使用者引入问题的背景知识,或者一些有用的假设。
d.指导作用较弱
当前,虽然R与Python中实现了这些方法并提供了可视化效果,降低了模型的使用门槛。但由于模型本身的原因,这些展现的结果也很难让使用者更清楚地分析影响预测准确率的潜在原因。
总之,传统的时间序列预测在模型的准确率以及与使用者之间的互动上很难达到理想的融合。
近期,facebook发布了prophet(“先知”)项目,它以更简单、灵活的预测方式以及能够获得与经验丰富的分析师相媲美的预测结果引起了人们的广泛关注。下面我们介绍一下Prophet。
Prophet介绍
2.1整体框架
整个过程分为四部分:Modeling、Forecast Evaluation、Surface Problems以及Visually Inspect Forecasts。从整体上看,这是一个循环结构,而这个结构又可以根据虚线分为分析师操纵部分与自动化部分,因此,整个过程就是分析师与自动化过程相结合的循环体系,也是一种将问题背景知识与统计分析融合起来的过程,这种结合大大的增加了模型的适用范围,提高了模型的准确性。按照上述的四个部分,prophet的预测过程为:
a.Modeling:建立时间序列模型。分析师根据预测问题的背景选择一个合适的模型。
b.Forecast Evaluation:模型评估。根据模型对历史数据进行仿真,在模型的参数不确定的情况下,我们可以进行多种尝试,并根据对应的仿真效果评估哪种模型更适合。
c.Surface Problems:呈现问题。如果尝试了多种参数后,模型的整体表现依然不理想,这个时候可以将误差较大的潜在原因呈现给分析师。
d.Visually Inspect Forecasts:以可视化的方式反馈整个预测结果。当问题反馈给分析师后,分析师考虑是否进一步调整和构建模型。
2.2适用场景
前文提到,不同时间序列预测问题的解决方案也各有不用。Prophet适用于有如下特征的业务问题:
a.有至少几个月(最好是一年)的每小时、每天或每周观察的历史数据;
b.有多种人类规模级别的较强的季节性趋势:每周的一些天和每年的一些时间;
c.有事先知道的以不定期的间隔发生的重要节假日(比如国庆节);
d.缺失的历史数据或较大的异常数据的数量在合理范围内;
e.有历史趋势的变化(比如因为产品发布);
f.对于数据中蕴含的非线性增长的趋势都有一个自然极限或饱和状态。
我们可以将SQL查询结果集通过管道传递R数据框对象中。首先,将您的SQL查询重命名为Daily Orders。然后,在R 中,我们可以使用以下语句将查询结果集传递到数据帧df中:
df <- datasets[["Daily Orders"]]
为了快速了解您的数据框包含多少个观测值,可以运行以下语句:
# 查看对象维度
dim(df)

Prophet输入DataFrame中有两列:分别包含日期和数值。
# 查看变量
str(df)
在此示例中,您将需要进行一些手动的日期格式转换:
# 转化时间变量
df <- mutate (
df,
date = ymd_hms(date) # ymd_hms 函数转换时间
)
确认数据框中的列是正确的类,就可以ds在数据框中创建一个新列:
df <- mutate (
df,
ds = date, # 使用mutate从日期创建新的ds列
y = value # 使用mutate从值创建新的y列
)
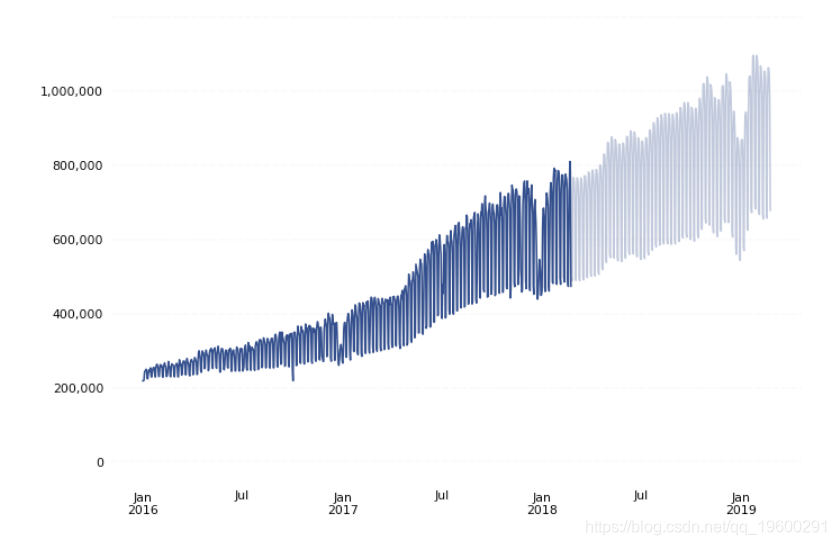
现在您已经准备好要与Prophet一起使用的数据,在将数据输入到Prophet中之前,将其作图并检查数据。
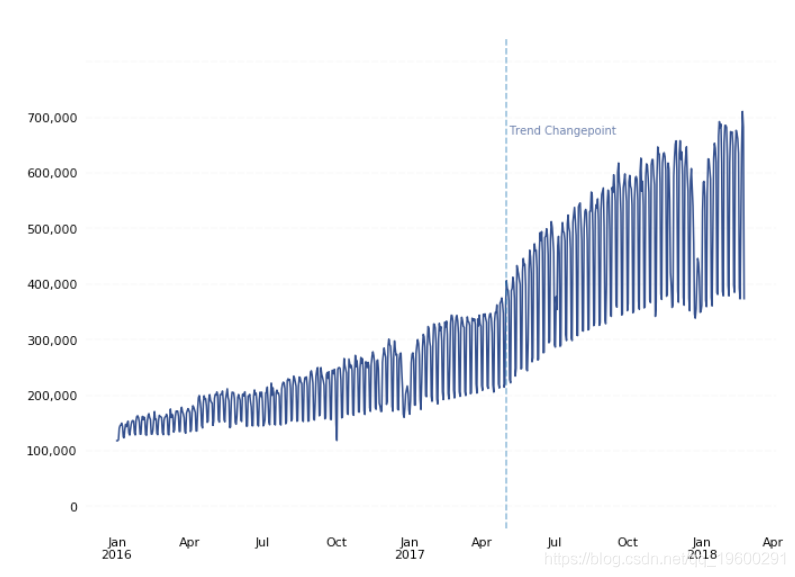
Box-Cox变换
通常在预测中,您会明确选择一种特定类型的幂变换,以将其应用于数据以消除噪声,然后再将数据输入到预测模型中(例如,对数变换或平方根变换等)。但是,有时可能难以确定哪种变换适合您的数据。
Box-Cox变换是一种数据变换,用于评估一组Lambda系数(λ)并选择可实现最佳正态性近似值的值。

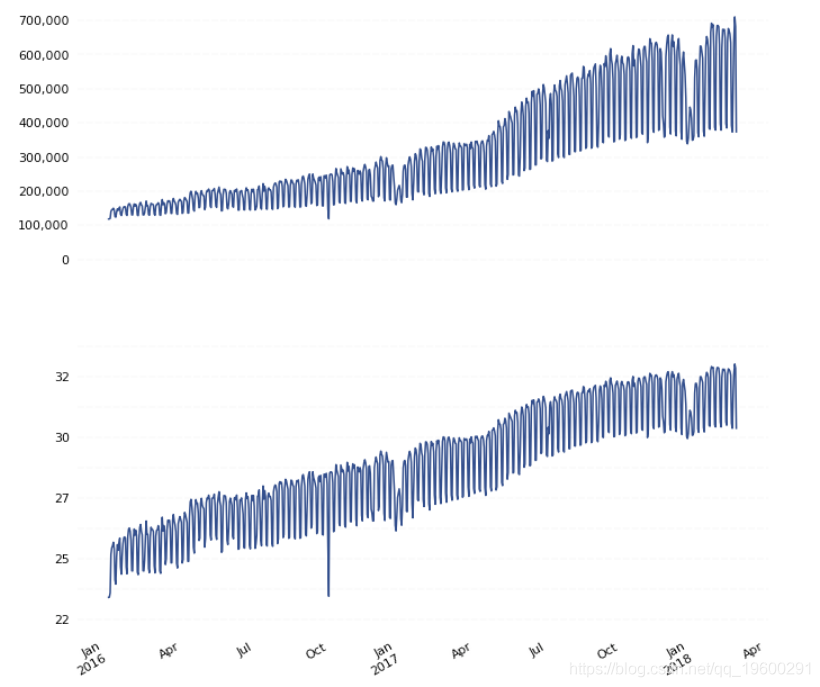
如果我们将新转换的数据与未转换的数据一起绘制,则可以看到Box-Cox转换能够消除随着时间变化而观察到增加的方差:

想了解更多关于模型定制、咨询辅导的信息?
预测
使用Prophet通过Box-Cox转换的数据集拟合模型后,现在就可以开始对未来日期进行预测。
现在,我们可以使用该predict()函数对未来数据帧中的每一行进行预测。
forecast <- predict(m, future)
此时,Prophet将创建一个预测变量的新数据框,其中包含名为的列下的未来日期的预测值yhat。
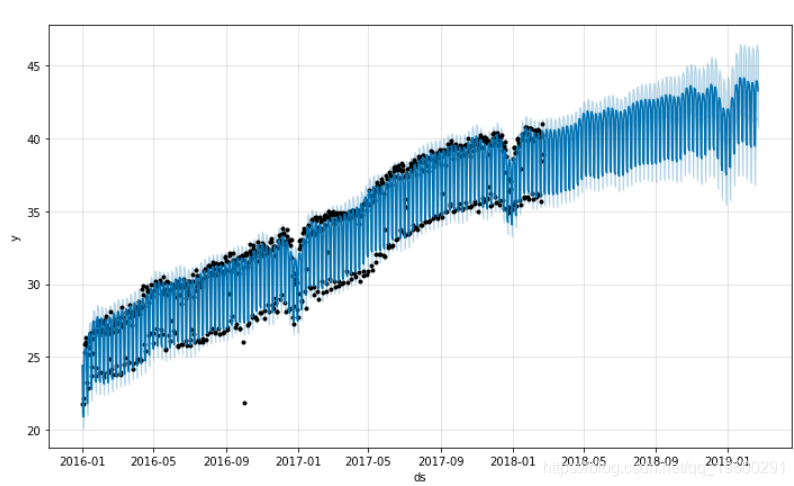
plot(m, forecast)
在我们的示例中,我们的预测如下所示:
随时关注您喜欢的主题
如果要可视化各个预测成分,则可以使用plot_components:

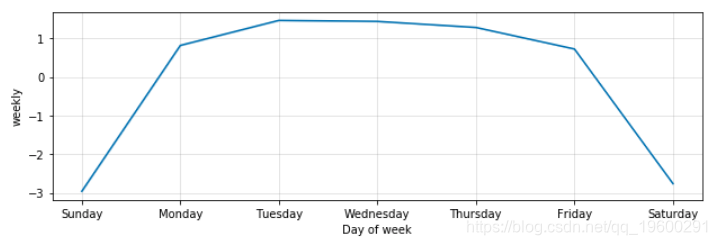
预测和成分可视化显示,Prophet能够准确地建模数据中的潜在趋势,同时还可以精确地建模每周和每年的季节性(例如,周末和节假日的订单量较低)。
现在,您已将预测值转换回其原始单位,现在可以将预测值与历史值一起可视化:
逆Box-Cox变换
由于PROPHET用于Box-Cox转换后的数据,因此您需要将预测值转换回其原始单位。要将新的预测值转换回其原始单位,您将需要执行Box-Cox逆转换。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据
Python实现Transformer神经网络时间序列模型可视化分析商超蔬菜销售数据筛选高销量单品预测|附代码数据 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究 Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据 Python比特币价格时间序列:LGBMRegressor递归自回归、随机游走及外部变量预测探索
Python比特币价格时间序列:LGBMRegressor递归自回归、随机游走及外部变量预测探索



