如何在matlab中用基于MCMC方法的Logit逻辑回归模型进行参数推断?此示例说明如何使用逻辑回归模型进行贝叶斯推断。
统计推断通常基于最大似然估计 (MLE)。
MLE 选择能够使数据似然最大化的参数,是一种较为自然的方法。MLE,即最大似然估计(Maximum Likelihood Estimation),是一种在统计学中常用的参数估计方法。它的核心思想是选择那些能使给定数据出现的概率(即似然)最大的参数值。这种方法基于一个直观且合理的假设:如果某个参数值使得观测到的数据出现的概率最大,那么这个参数值就是最合理的估计。
可下载资源
作者

在 MLE 中,假定参数是未知但固定的数值,并在一定的置信度下进行计算。在贝叶斯统计中,使用概率来量化未知参数的不确定性,因而未知参数被视为随机变量。
MCMC采样法主要包括两个MC,即Monte Carlo和Markov Chain。Monte Carlo是指基于采样的数值型近似求解方法,Markov Chain则是用于采样,MCMC的基本思想是:针对待采样的目标分布,构造一个马尔科夫链,使得该马尔科夫链的平稳分布就是目标分布,然后从任何一个初始状态出发,沿着马尔科夫链进行状态转移,最终得到的状态转移序列会收敛到目标分布,由此得到目标分布的一系列样本。
MCMC有着不同的马尔科夫链(Markov Chain),不同的链对应不用的采样法,常见的两种就是Metropolis-Hastings采样法和吉布斯采样法。
基于马尔科夫链采样
如果我们得到了某个平稳分布所对应的马尔科夫链状态转移矩阵,我们就很容易采用出这个平稳分布的样本集。
首先,基于初始任意简单概率分布比如高斯分布 采样得到状态值
,基于条件概率分布
采样状态值
,一直进行下去,当状态转移进行到一定的次数时,比如到
次时,我们认为此时的采样集
即是符合我们的平稳分布的对应样本集,可以用来做蒙特卡罗模拟求和了。
算法如下:
-
输入马尔科夫链状态转移矩阵
,设定状态转移次数阈值
,需要的样本个数
;
-
从任意简单概率分布采样得到初始状态值
;
-
for
: 从条件概率分布
中采样得到样本
;
-
样本集
即是符合我们的平稳分布的对应样本集。
贝叶斯推断
贝叶斯推断是结合有关模型或模型参数的先验知识来分析统计模型的过程。这种推断的根基是贝叶斯定理:
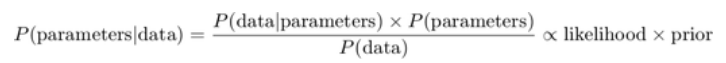
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
视频
马尔可夫链蒙特卡罗方法MCMC原理与R语言实现
例如,假设我们有正态观测值
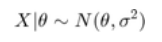
其中 sigma 是已知的,theta 的先验分布为
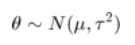
在此公式中,mu 和 tau(有时也称为超参数)也是已知的。如果观察 X 的 n 个样本,我们可以获得 theta 的后验分布
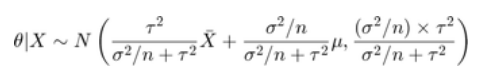
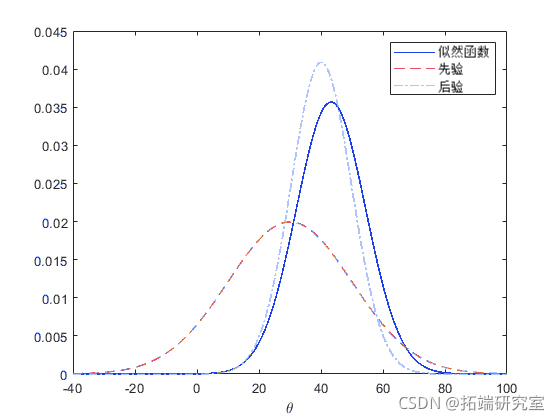
下图显示 theta 的先验、似然和后验。
y = norpdf(thta, posMan,psSD); plot(theta'-', theta,'--', theta,'-.')
汽车实验数据
在一些简单的问题中,例如前面的正态均值推断示例,很容易计算出封闭形式的后验分布。但是,在涉及非共轭先验的一般问题中,后验分布很难或不可能通过分析来进行计算。我们将以逻辑回归作为示例。此示例包含一个实验,以帮助建模不同重量的汽车在里程测试中的未通过比例。数据包括被测汽车的重量、汽车数量以及失败次数等观测值。我们采用一组经过变换的重量,以减少回归参数估值的相关性。
% 一组汽车的重量 % 每个重量下测试的汽车数量 \[48 42 31 34 31 21 23 23 21 16 17 21\]'; % 在每个重量上有不良mpg表现的汽车数量 \[1 2 0 3 8 8 14 17 19 15 17 21\]';
逻辑回归模型
逻辑回归(广义线性模型的一种特例)适合这些数据,因为因变量呈二项分布。逻辑回归模型可以写作:
 = \frac{e^{Xb}}{1+e^{Xb}}$$")
其中 X 是设计矩阵,b 是包含模型参数的向量。我们可以将此方程写作:
@(b,x) exp(b(1)+b(2).\*x)./(1+exp(b(1)+b(2).\*x));
如果您有一些先验知识或者已经具备某些非信息性先验,则可以指定模型参数的先验概率分布。例如,在此示例中,我们使用正态先验值表示截距 b1 和斜率 b2,即
@(b1) normpdf(b1,0,20); % 截距的先验。 @(b2) normpdf(b2,0,20); % 斜率的先验。
根据贝叶斯定理,模型参数的联合后验分布与似然和先验的乘积成正比。
请注意,此模型中后验的归一化常数很难进行分析。但是,即使不知道归一化常数,如果您知道模型参数的大致范围,也可以可视化后验分布。
msh(b2,b1,sipot) view(-10,30)
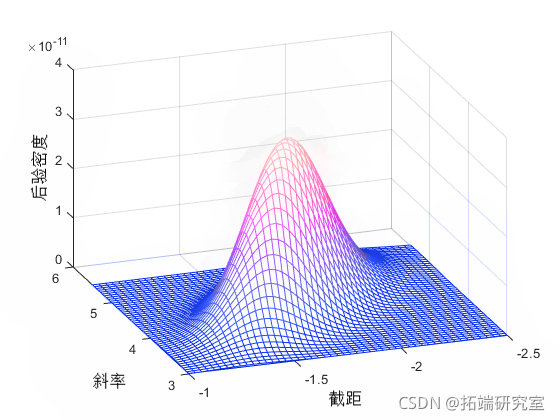
此后验沿参数空间的对角线伸长,表明(在我们观察数据后)我们认为参数是相关的。这很有意思,因为在我们收集任何数据之前,我们假设它们是独立的。相关性来自我们的先验分布与似然函数的组合。
_切片_采样
蒙特卡罗方法常用于在贝叶斯数据分析中汇总后验分布。其想法是,即使您不能通过分析的方式计算后验分布,也可以从分布中生成随机样本,并使用这些随机值来估计后验分布或推断的统计量,如后验均值、中位数、标准差等。_切片_采样是一种算法,用于从具有任意密度函数的分布中进行抽样,已知项最多只有一个比例常数 – 而这正是从归一化常数未知的复杂后验分布中抽样所需要的。此算法不生成独立样本,而是生成马尔可夫序列,其平稳分布就是目标分布。因此,切片抽样器是一种马尔可夫链蒙特卡罗 (MCMC) 算法。但是,它与其他众所周知的 MCMC 算法不同,因为只需要指定缩放的后验,不需要建议分布或边缘分布。

此示例说明如何使用切片抽样器作为里程测试逻辑回归模型的贝叶斯分析的一部分,包括从模型参数的后验分布生成随机样本、分析抽样器的输出,以及对模型参数进行推断。第一步是生成随机样本。
sliesmle(inial,nsapes,'pdf');
采样器输出分析
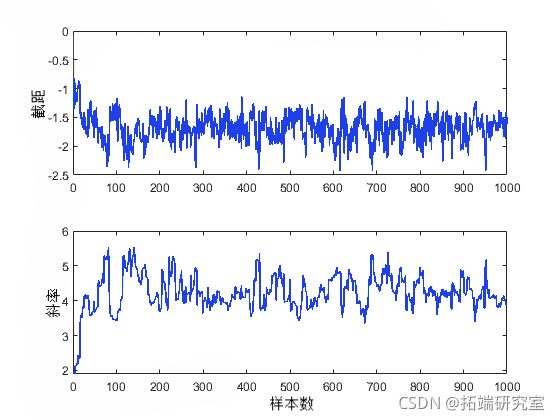
从切片采样获取随机样本后,很重要的一点是研究诸如收敛和混合之类的问题,以确定将样本视为是来自目标后验分布的一组随机实现是否合理。观察边缘轨迹图是检查输出的最简单方法。
plot(trace(:,1))
随时关注您喜欢的主题
从这些图中可以明显看出,在处理过程趋于平稳之前,参数起始值的影响会维持一段时间(大约 50 个样本)才会消失。
检查收敛以使用移动窗口计算统计量(例如样本的均值、中位数或标准差)也很有帮助。这样可以产生比原始样本轨迹更平滑的图,并且更容易识别和理解任何非平稳性。
mvag = fier( (1/50)*os(50,1), 1, tace); plot(moav(:,1))
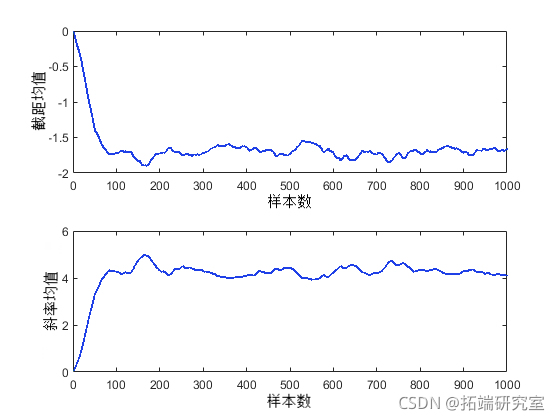
由于这些是基于包含 50 次迭代的窗口计算的移动平均值,因此前 50 个值无法与图中的其他值进行比较。然而,每个图的其他值似乎证实参数后验均值在 100 次左右迭代后收敛至平稳分布。同样显而易见的是,这两个参数彼此相关,与之前的后验密度图一致。
由于磨合期代表目标分布中不能合理视为随机实现的样本,因此不建议使用切片采样器一开始输出的前 50 个左右的值。您可以简单地删除这些输出行,但也可以指定一个“预热”期。
在已知合适的预热长度(可能来自先前的运行)时,这种方式很简便。
slcsapl(inial,nsmes,'pf',pot, ..'brin',50); plot(trace(:,1))
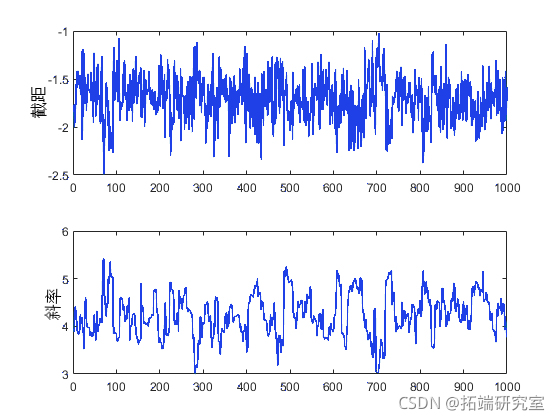
这些跟踪图没有显示出任何不平稳,表明预热期已完成。
但是,还需要了解跟踪图的另一方面。虽然截距的轨迹看起来像高频噪声,但斜率的轨迹好像具有低频分量,表明相邻迭代的值之间存在自相关。虽然也可以从这个自相关样本计算均值,但我们通常会通过删除样本中的冗余数据这一简便的操作来降低存储要求。如果它同时消除了自相关,我们还可以将这些数据视为独立值样本。例如,您可以通过只保留第 10 个、第 20 个、第 30 个等值来稀释样本。
sceampe(... 'brin'50,'tin',10);
要检查这种稀释的效果,可以根据轨迹估计样本自相关函数,并使用它们来检查样本是否快速混合。
fftetendtrce,'cnsant'); F .* coj(F); for i = 1:2 lineles = stem(:20, F(:i) 'filled' , 'o');
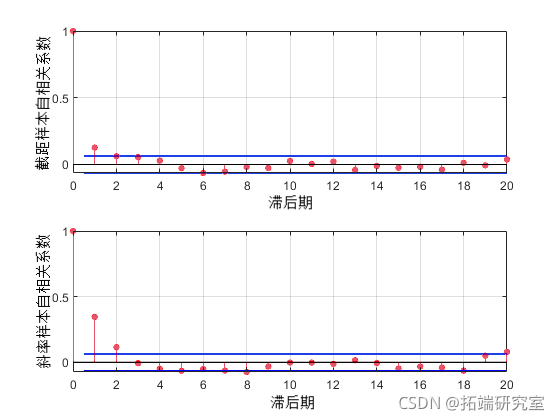
第一个滞后的自相关值对于截距参数很明显,对于斜率参数更是如此。我们可以使用更大的稀释参数重复抽样,以进一步降低相关性。但为了完成本示例的目的,我们将继续使用当前样本。
推断模型参数
与预期相符,样本直方图模拟了后验密度图。
hist(rce,\[25,25\]); view(-10,30)
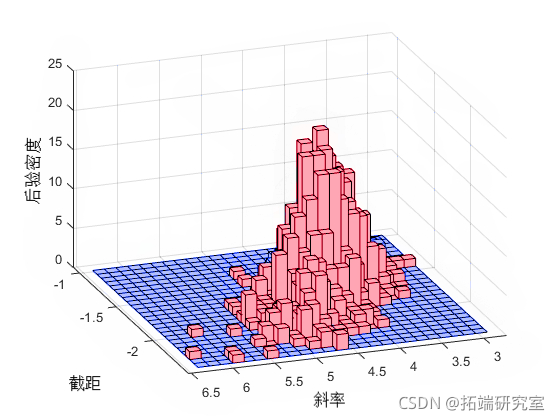
您可以使用直方图或核平滑密度估计值来总结后验样本的边缘分布属性。
kdeiy(rae(:2))
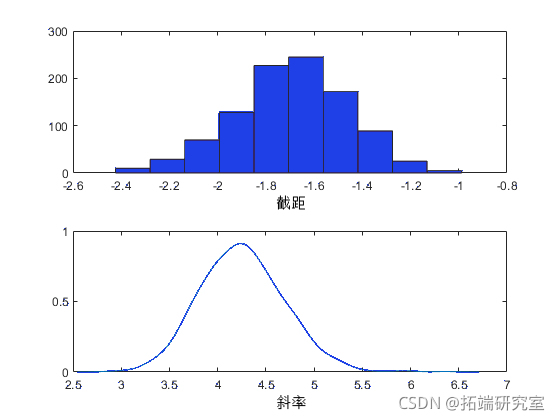
您还可以计算描述性统计量,例如随机样本的后验均值或百分位数。为了确定样本大小是否足以实现所需的精度,将所需的轨迹统计量作为样本数的函数来进行查看会很有帮助。
csu= csm(rae); plot(csm(:,1)'./(1:sals))
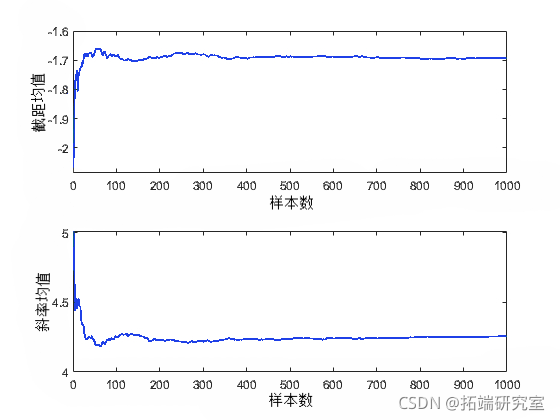
在这种情况下,样本大小 1000 似乎足以为后验均值估计值提供良好的精度。
mean(te)

总结
您能够轻松地指定似然和先验。您也可以将它们结合起来用于推断后验分布。您可以通过马尔可夫链蒙特卡罗仿真在 MATLAB 中执行贝叶斯分析。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 2026汽车行业全景洞察报告:智能座舱·线控底盘·城市NOA·出海·ESG|附600+份报告PDF、数据、可视化模板汇总下载
2026汽车行业全景洞察报告:智能座舱·线控底盘·城市NOA·出海·ESG|附600+份报告PDF、数据、可视化模板汇总下载 2026汽车行业趋势洞察和典型增长市场解析:轻量化、智能化、出海|附600+份报告PDF、数据、可视化模板汇总下载
2026汽车行业趋势洞察和典型增长市场解析:轻量化、智能化、出海|附600+份报告PDF、数据、可视化模板汇总下载 MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据
MATLAB奥运会奖牌预测研究 —CNN神经网络、逻辑回归、Liang-Kleeman信息流、多元回归及随机森林模型的因果关联与概率预测|附代码数据



